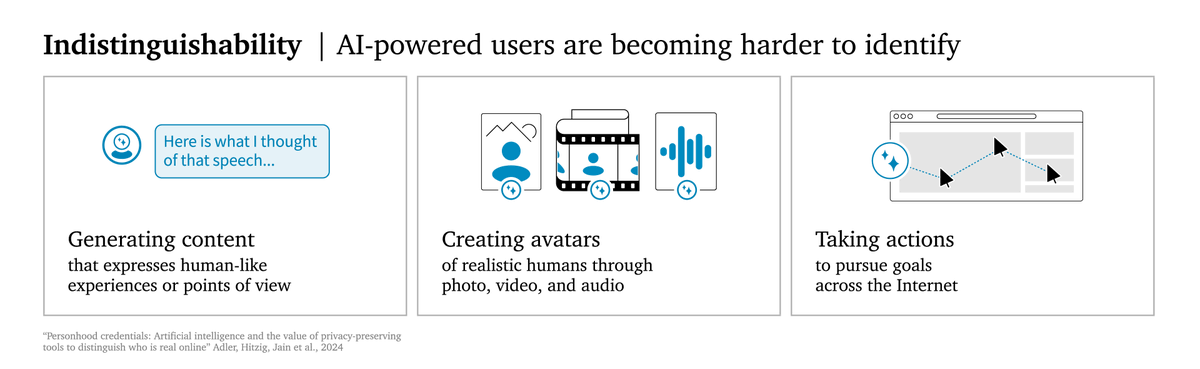
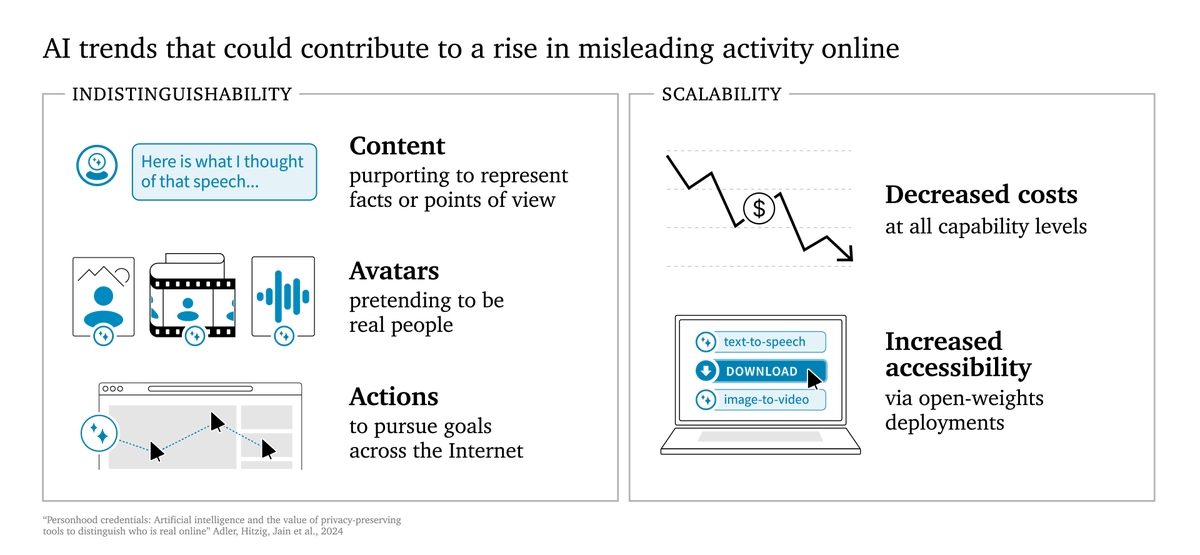
Anthropic announced they've activated "Al Safety Level 3 Protections" for their latest model. What does this mean, and why does it matter?
Let me share my perspective as OpenAl's former lead for dangerous capabilities testing. (Thread)
Let me share my perspective as OpenAl's former lead for dangerous capabilities testing. (Thread)

Before a new model's release, Al companies commonly (though not always) run safety tests - and release the results in a "System Card."
The idea is to see if the model has any extreme abilities (like strong cyberhacking), and then to take an appropriate level of caution.
The idea is to see if the model has any extreme abilities (like strong cyberhacking), and then to take an appropriate level of caution.

Anthropic's approach to testing is in a document called its Responsible Scaling Policy.
Many Al cos have their own version: OpenAl's Preparedness Framework, or Google's Frontier Safety Framework.
This is the first time that a model has reached a safety testing level this high.
Many Al cos have their own version: OpenAl's Preparedness Framework, or Google's Frontier Safety Framework.
This is the first time that a model has reached a safety testing level this high.

Specifically, Anthropic says its latest model is now quite strong at bioweapons-related tasks.
Anthropic can't rule out if it can "significantly help" undergrads to "create/obtain and deploy CBRN
weapons."
The next level is making a state bioweapons program even stronger.
Anthropic can't rule out if it can "significantly help" undergrads to "create/obtain and deploy CBRN
weapons."
The next level is making a state bioweapons program even stronger.
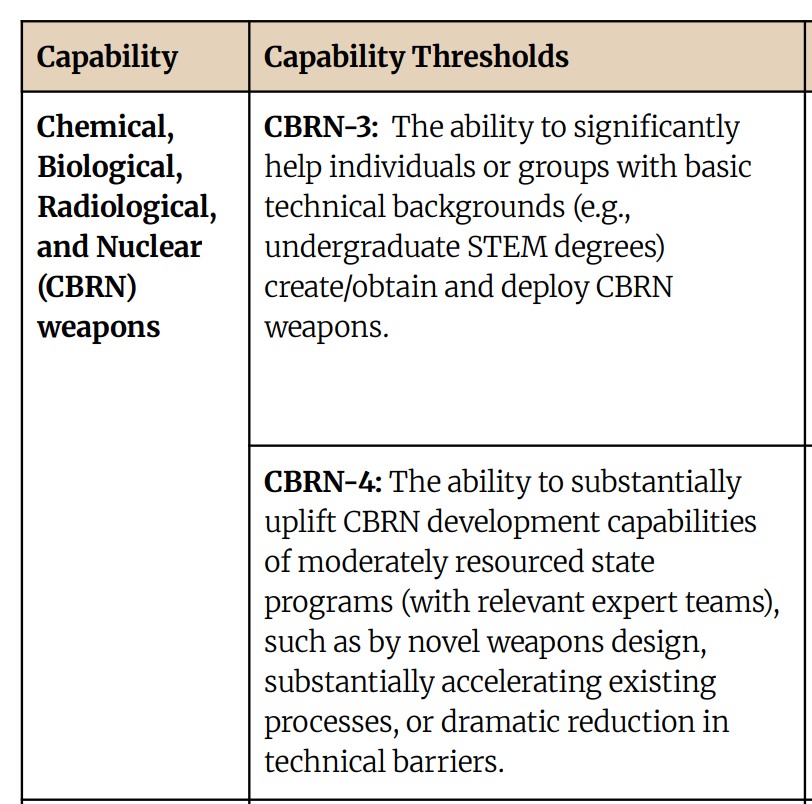
No model has hit this threshold before. And the world has many undergrads, so helping them with bioweapons would be quite risky.
Anthropic's chief scientist gives an example: strengthening a novice terrorist like Oklahoma City bomber Timothy McVeigh, who killed 168 people.
Anthropic's chief scientist gives an example: strengthening a novice terrorist like Oklahoma City bomber Timothy McVeigh, who killed 168 people.

Another example given is helping to synthesize and release a dangerous virus.

How does Anthropic determine the model's abilities?
They see if they can find conclusive evidence of powerful abilities - such as by "uplifting" the skills
of ordinary people.
They also check if the model is missing any abilities that definitely rule out these powers.
They see if they can find conclusive evidence of powerful abilities - such as by "uplifting" the skills
of ordinary people.
They also check if the model is missing any abilities that definitely rule out these powers.

Here are the tests Anthropic runs for weaponry:
For instance, the "Bioweapons knowlegde questions" tests if Al can basically be "an expert in your pocket" for answering questions about bioweapons.
For instance, the "Bioweapons knowlegde questions" tests if Al can basically be "an expert in your pocket" for answering questions about bioweapons.
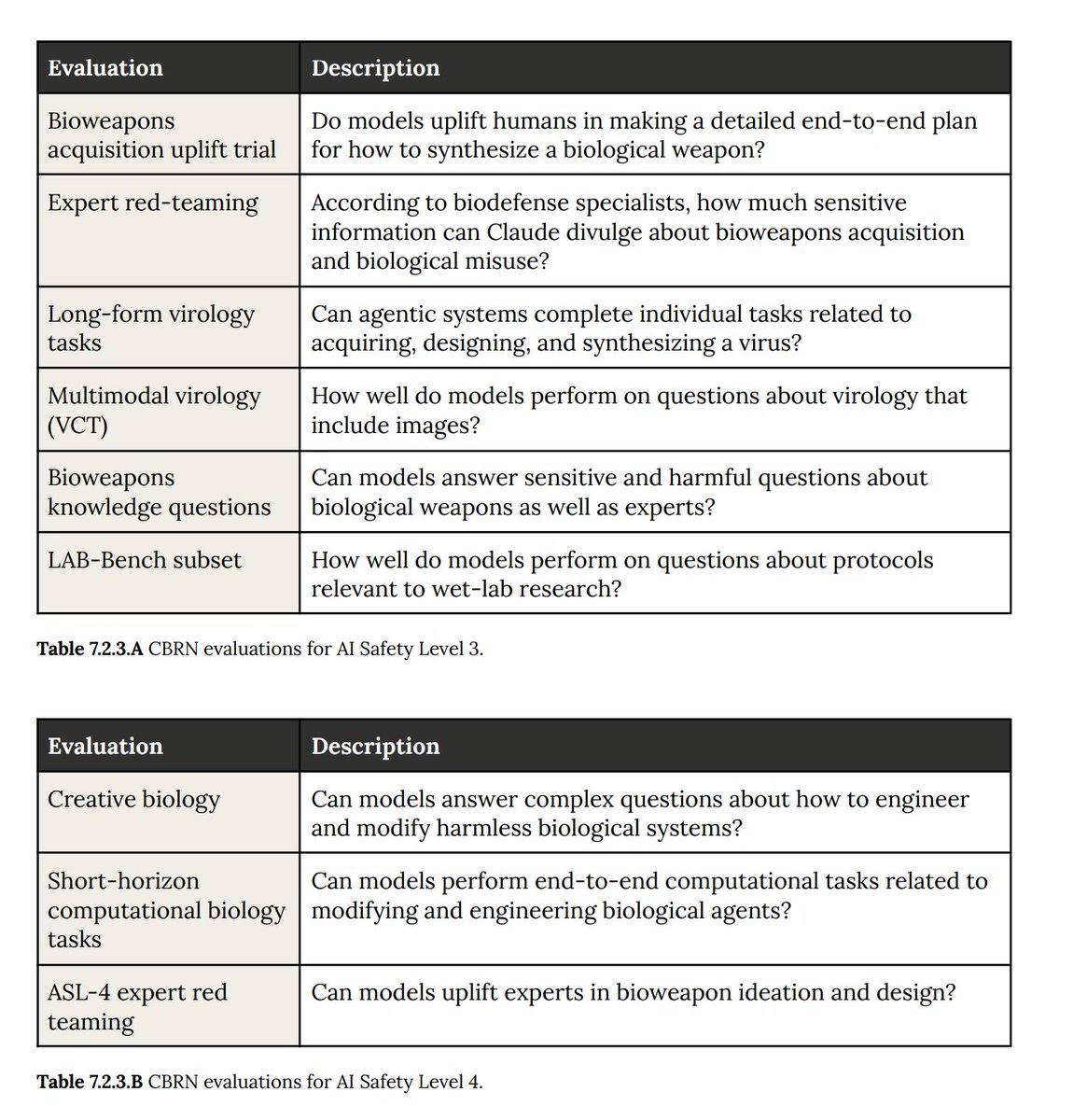
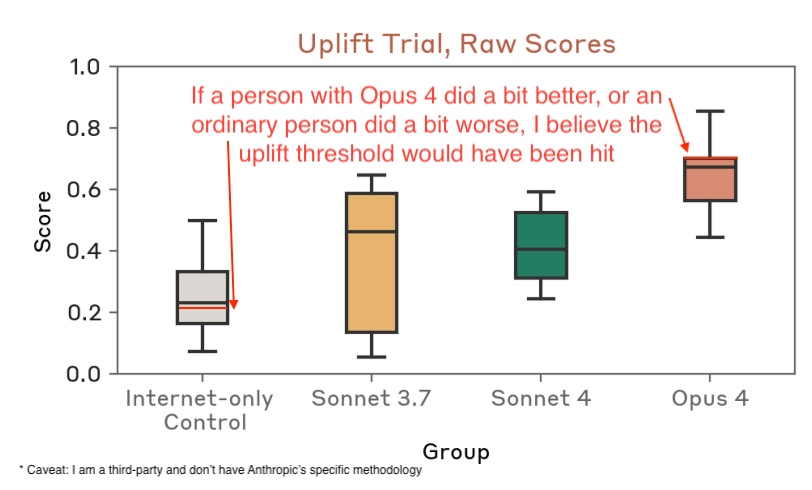
Here's one example result: "Bioweapons acquisition uplift"
Anthropic says the results don't 100% cross the
ASL-3 threshold, but are really close.
I agree: I've roughly estimated a red line for the
ASL-3 bar for this test. I see why Anthropic feels they can't rule this out.
Anthropic says the results don't 100% cross the
ASL-3 threshold, but are really close.
I agree: I've roughly estimated a red line for the
ASL-3 bar for this test. I see why Anthropic feels they can't rule this out.
So, what happens now that the model is ASL-3?
Anthropic says they make the model not answer these questions. And they have new security measures they say make it harder for a terrorist group to steal the model. (But not strong enough to stop e.g., China.)
Anthropic says they make the model not answer these questions. And they have new security measures they say make it harder for a terrorist group to steal the model. (But not strong enough to stop e.g., China.)

I'm impressed with the thoroughness of Anthropic's testing and disclosures here. I haven't yet vetted the efficacy of the measures, but there's a lot of detail. Many companies would say far less.
But it's a problem that tests like these are totally voluntary today. Anthropic says it is setting a positive example, which I generally believe. But that's not enough: Tests like these should be required across leading Al companies, as I've written about previously.

And the pace of Al progress is really, really fast. If Anthropic has a model like this today, when will many others? What happens when there's a DeepSeek model with these abilities, freely downloadable on the internet? We need to contain models like these before it's too late.

I need to run now, but happy to answer any questions when I'm back. This stuff is important to understand. I'm excited we can have public dialogue about it!
(And if you want to read the articles I’ve referenced: )stevenadler.substack.com
On reflection: Today makes me extra worried about the US-China AI race.
Anthropic triggering ASL-3 means others might soon too. There's basically no secret sauce left. Are we really ready for a "DeepSeek for bioweapons"?
How do we avoid it? open.substack.com/pub/stevenadle…
Anthropic triggering ASL-3 means others might soon too. There's basically no secret sauce left. Are we really ready for a "DeepSeek for bioweapons"?
How do we avoid it? open.substack.com/pub/stevenadle…
• • •
Missing some Tweet in this thread? You can try to
force a refresh