AI safety researcher (ex-OpenAI: danger evals, AGI readiness, etc), writing at https://t.co/XtUTLK3jEo
 Former Pentagon AI Policy Director, @MarkBeall on the stakes:
Former Pentagon AI Policy Director, @MarkBeall on the stakes: 
 Before a new model's release, Al companies commonly (though not always) run safety tests - and release the results in a "System Card."
Before a new model's release, Al companies commonly (though not always) run safety tests - and release the results in a "System Card."
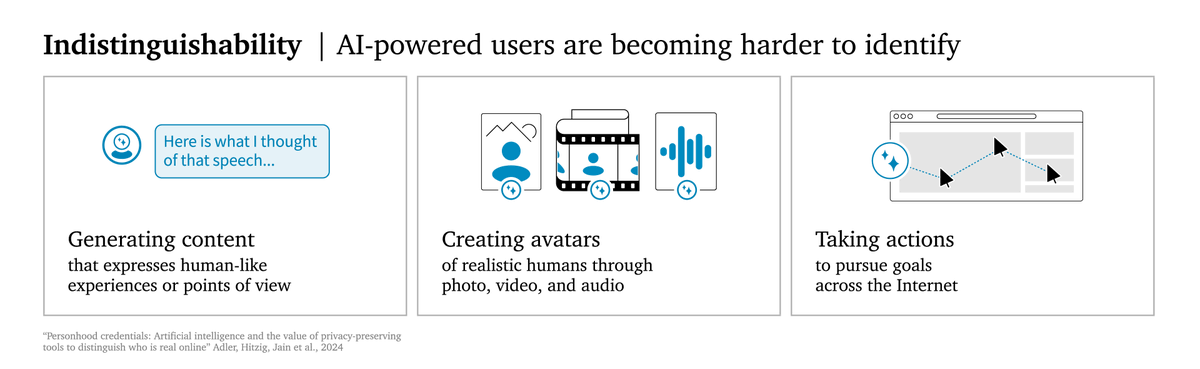
 People want to be able to trust in others online - that folks on dating apps aren’t fake accounts trying to trick or scam them. But as AI becomes more realistic, how can you be sure? Realistic photos and videos of someone might not be enough. (2/n)
People want to be able to trust in others online - that folks on dating apps aren’t fake accounts trying to trick or scam them. But as AI becomes more realistic, how can you be sure? Realistic photos and videos of someone might not be enough. (2/n)