DeepSeek’s R1 leaps over xAI, Meta and Anthropic to be tied as the world’s #2 AI Lab and the undisputed open-weights leader
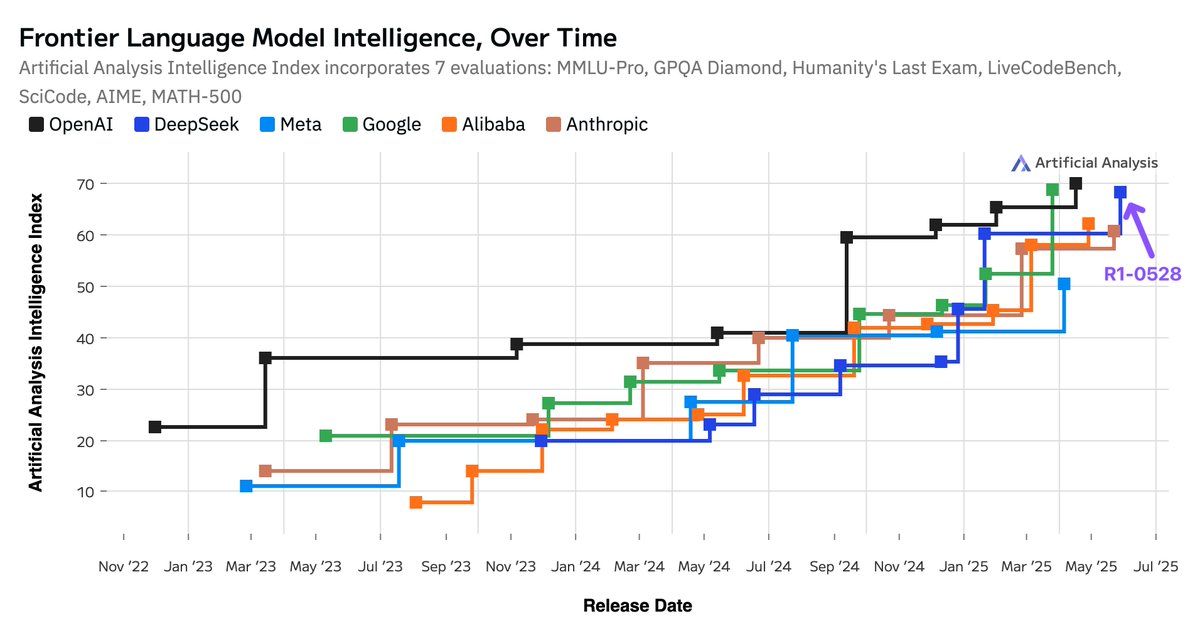
DeepSeek R1 0528 has jumped from 60 to 68 in the Artificial Analysis Intelligence Index, our index of 7 leading evaluations that we run independently across all leading models. That’s the same magnitude of increase as the difference between OpenAI’s o1 and o3 (62 to 70).
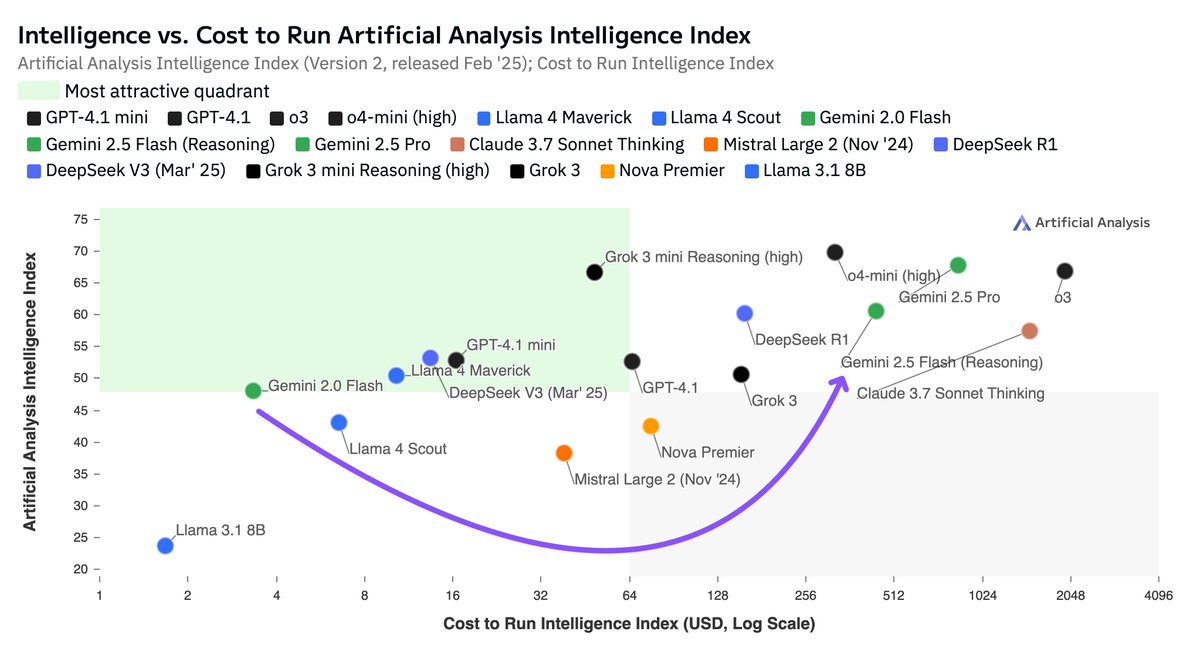
This positions DeepSeek R1 as higher intelligence than xAI’s Grok 3 mini (high), NVIDIA’s Llama Nemotron Ultra, Meta’s Llama 4 Maverick, Alibaba’s Qwen 3 253 and equal to Google’s Gemini 2.5 Pro.
Breakdown of the model’s improvement:
🧠 Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points)
🏠 No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters
🧑💻 Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3
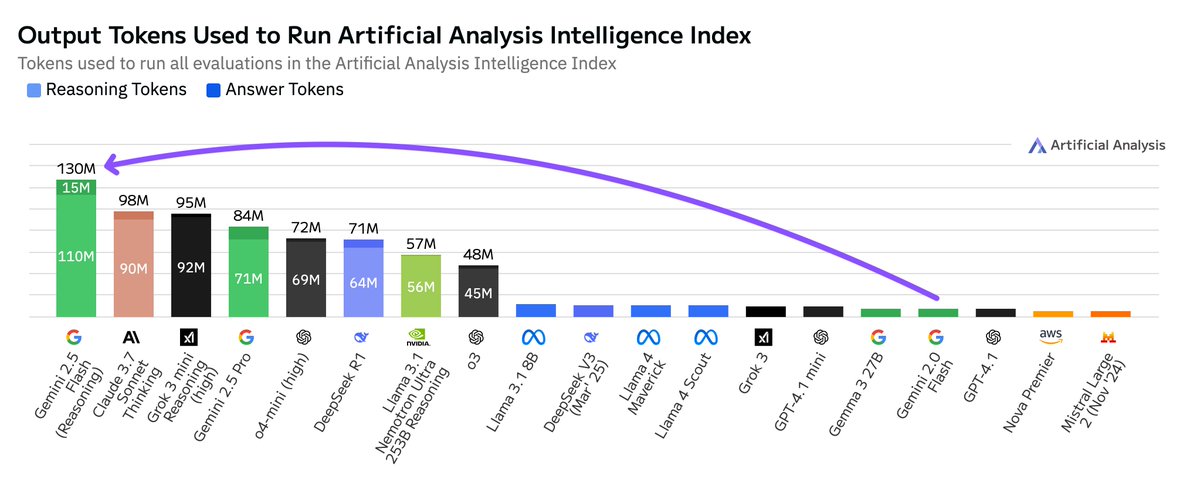
🗯️ Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528
Takeaways for AI:
👐 The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position
🇨🇳 China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index
🔄 Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs
See further analysis below 👇
DeepSeek R1 0528 has jumped from 60 to 68 in the Artificial Analysis Intelligence Index, our index of 7 leading evaluations that we run independently across all leading models. That’s the same magnitude of increase as the difference between OpenAI’s o1 and o3 (62 to 70).
This positions DeepSeek R1 as higher intelligence than xAI’s Grok 3 mini (high), NVIDIA’s Llama Nemotron Ultra, Meta’s Llama 4 Maverick, Alibaba’s Qwen 3 253 and equal to Google’s Gemini 2.5 Pro.
Breakdown of the model’s improvement:
🧠 Intelligence increases across the board: Biggest jumps seen in AIME 2024 (Competition Math, +21 points), LiveCodeBench (Code generation, +15 points), GPQA Diamond (Scientific Reasoning, +10 points) and Humanity’s Last Exam (Reasoning & Knowledge, +6 points)
🏠 No change to architecture: R1-0528 is a post-training update with no change to the V3/R1 architecture - it remains a large 671B model with 37B active parameters
🧑💻 Significant leap in coding skills: R1 is now matching Gemini 2.5 Pro in the Artificial Analysis Coding Index and is behind only o4-mini (high) and o3
🗯️ Increased token usage: R1-0528 used 99 million tokens to complete the evals in Artificial Analysis Intelligence Index, 40% more than the original R1’s 71 million tokens - ie. the new R1 thinks for longer than the original R1. This is still not the highest token usage number we have seen: Gemini 2.5 Pro is using 30% more tokens than R1-0528
Takeaways for AI:
👐 The gap between open and closed models is smaller than ever: open weights models have continued to maintain intelligence gains in-line with proprietary models. DeepSeek’s R1 release in January was the first time an open-weights model achieved the #2 position and DeepSeek’s R1 update today brings it back to the same position
🇨🇳 China remains neck and neck with the US: models from China-based AI Labs have all but completely caught up to their US counterparts, this release continues the emerging trend. As of today, DeepSeek leads US based AI labs including Anthropic and Meta in Artificial Analysis Intelligence Index
🔄 Improvements driven by reinforcement learning: DeepSeek has shown substantial intelligence improvements with the same architecture and pre-train as their original DeepSeek R1 release. This highlights the continually increasing importance of post-training, particularly for reasoning models trained with reinforcement learning (RL) techniques. OpenAI disclosed a 10x scaling of RL compute between o1 and o3 - DeepSeek have just demonstrated that so far, they can keep up with OpenAI’s RL compute scaling. Scaling RL demands less compute than scaling pre-training and offers an efficient way of achieving intelligence gains, supporting AI Labs with fewer GPUs
See further analysis below 👇

DeepSeek has maintained its status as amongst AI labs leading in frontier AI intelligence
Today’s DeepSeek R1 update is substantially more verbose in its responses (including considering reasoning tokens) than the January release. DeepSeek R1 May used 99M tokens to run the 7 evaluations in our Intelligence Index, +40% more tokens than the prior release

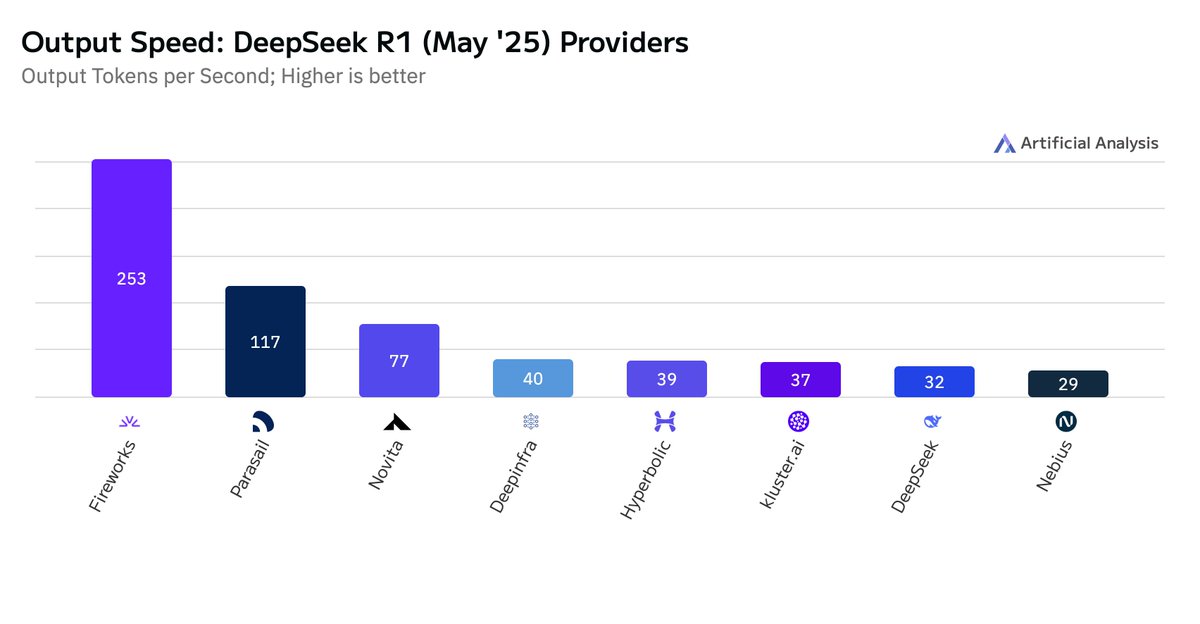
Congratulations to @FireworksAI_HQ , @parasail_io , @novita_labs , @DeepInfra , @hyperbolic_labs , @klusterai , @deepseek_ai and @nebiusai on being fast to launch endpoints
For further analysis see Artificial Analysis
Comparison to other models:
artificialanalysis.ai/models
DeepSeek R1 (May update) provider comparison:
artificialanalysis.ai/models/deepsee…
Comparison to other models:
artificialanalysis.ai/models
DeepSeek R1 (May update) provider comparison:
artificialanalysis.ai/models/deepsee…
Individual results across our independent intelligence evaluations:

• • •
Missing some Tweet in this thread? You can try to
force a refresh