
 Grok 4.5 performs very strongly on agentic tasks including knowledge work, terminal use, and customer service. Across GDPval-AA v2, 𝜏³-Banking, and Terminal-Bench v2.1, Grok 4.5 sits in line or ahead of Claude Opus 4.8 and GPT-5.5. We’ll be evaluating it soon on AA-Briefcase, our private benchmark of long-horizon knowledge work tasks across projects.
Grok 4.5 performs very strongly on agentic tasks including knowledge work, terminal use, and customer service. Across GDPval-AA v2, 𝜏³-Banking, and Terminal-Bench v2.1, Grok 4.5 sits in line or ahead of Claude Opus 4.8 and GPT-5.5. We’ll be evaluating it soon on AA-Briefcase, our private benchmark of long-horizon knowledge work tasks across projects.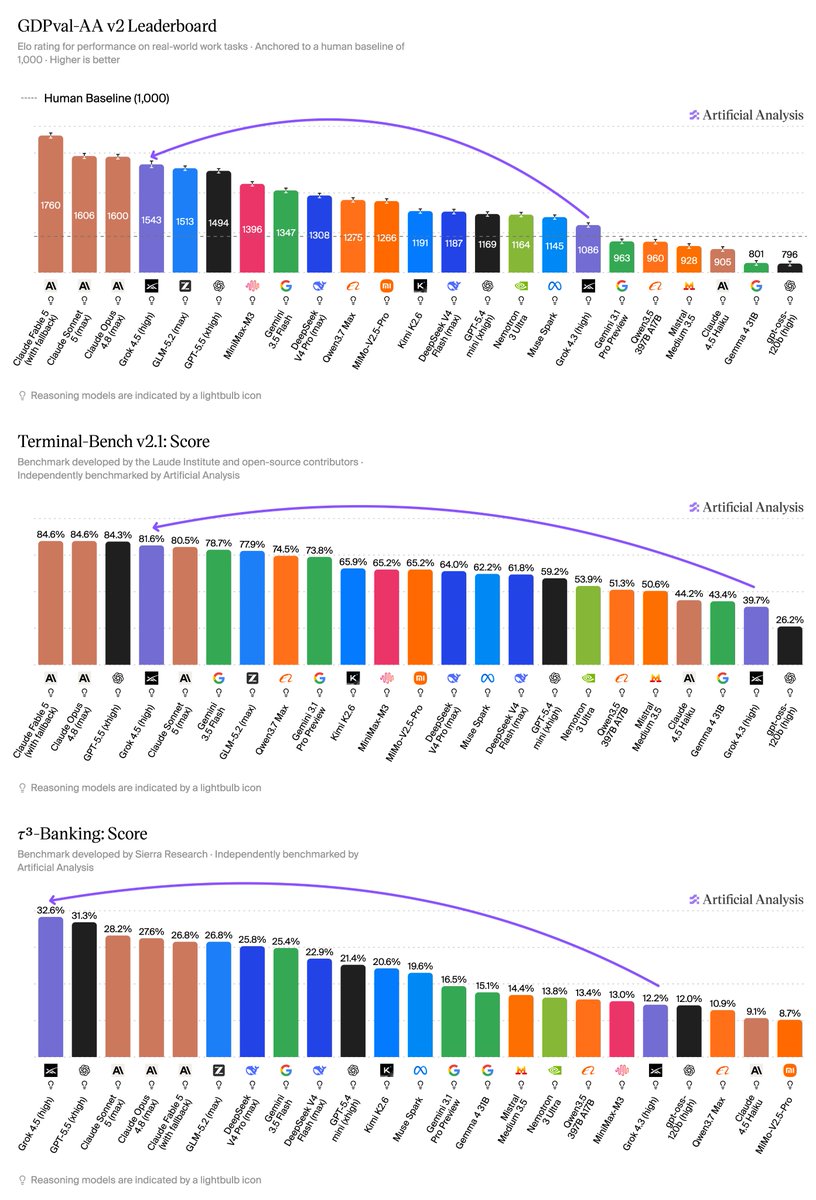
 This release shows increased cost efficiency to run the Artificial Analysis Intelligence Index, with Grok 4.3 sitting comfortably on the Pareto frontier for intelligence versus cost
This release shows increased cost efficiency to run the Artificial Analysis Intelligence Index, with Grok 4.3 sitting comfortably on the Pareto frontier for intelligence versus cost
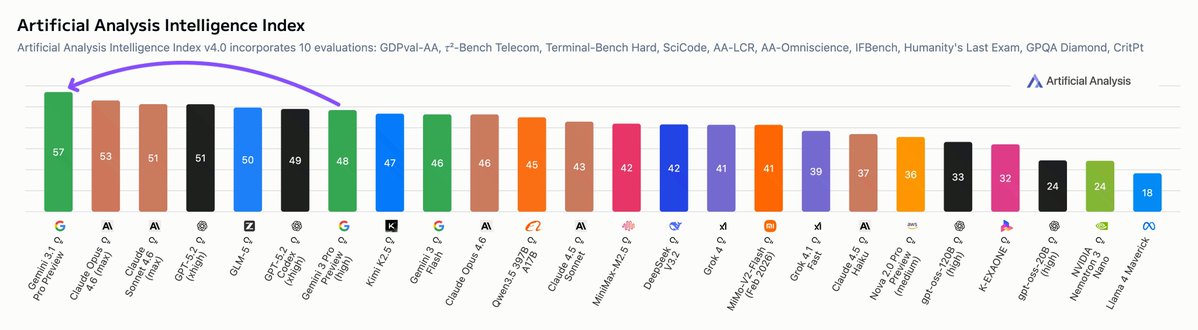 Gemini 3.1 Pro Preview improves without becoming more expensive or much more verbose, using only ~1M more tokens compared to Gemini 3 Pro Preview, representing a $72 increase in cost to run the Artificial Analysis Intelligence Index. This cost is less than half of frontier peers such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open-weights models such as GLM 5 and Kimi K2.5.
Gemini 3.1 Pro Preview improves without becoming more expensive or much more verbose, using only ~1M more tokens compared to Gemini 3 Pro Preview, representing a $72 increase in cost to run the Artificial Analysis Intelligence Index. This cost is less than half of frontier peers such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open-weights models such as GLM 5 and Kimi K2.5.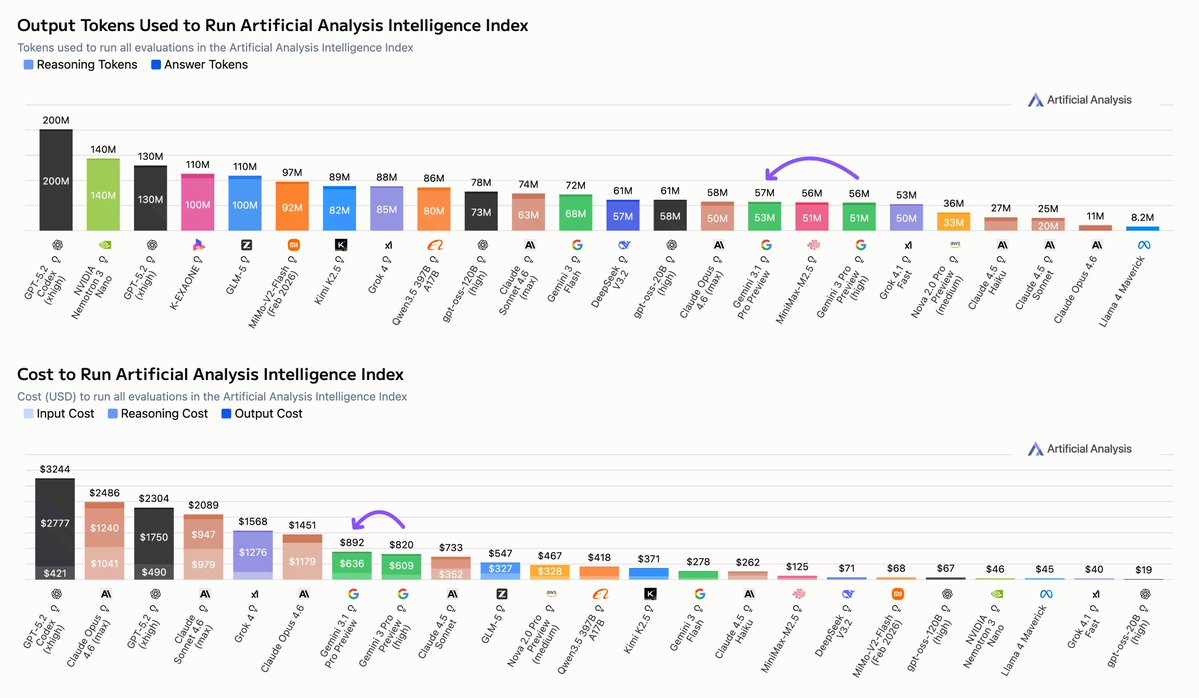
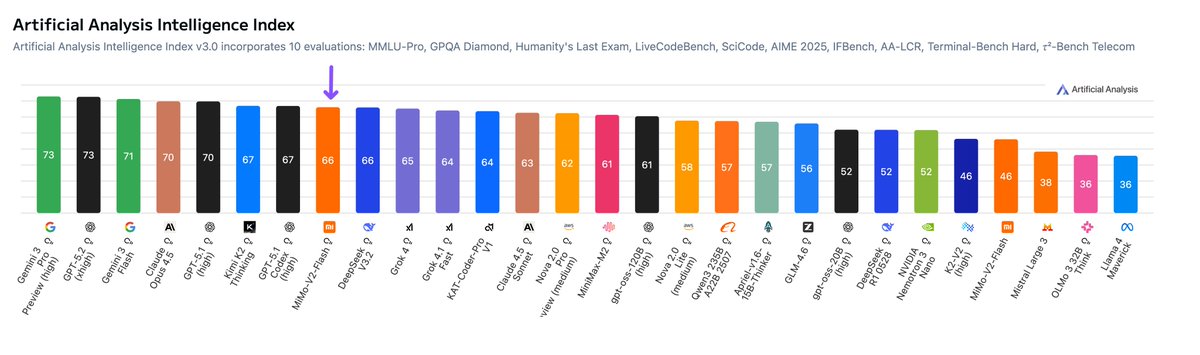 MiMo-V2-Flash demonstrates particular strength in agentic tool-use and Competition Math, scoring 95% on τ²-Bench Telecom and 96% on AIME 2025. This places it amongst the best performing models in these categories.
MiMo-V2-Flash demonstrates particular strength in agentic tool-use and Competition Math, scoring 95% on τ²-Bench Telecom and 96% on AIME 2025. This places it amongst the best performing models in these categories. 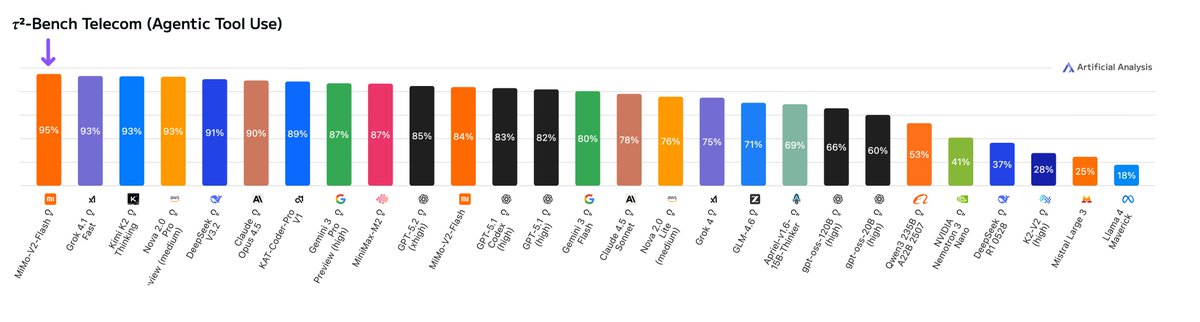
 Stirrup agents can be easily set up in just a few lines of code
Stirrup agents can be easily set up in just a few lines of code
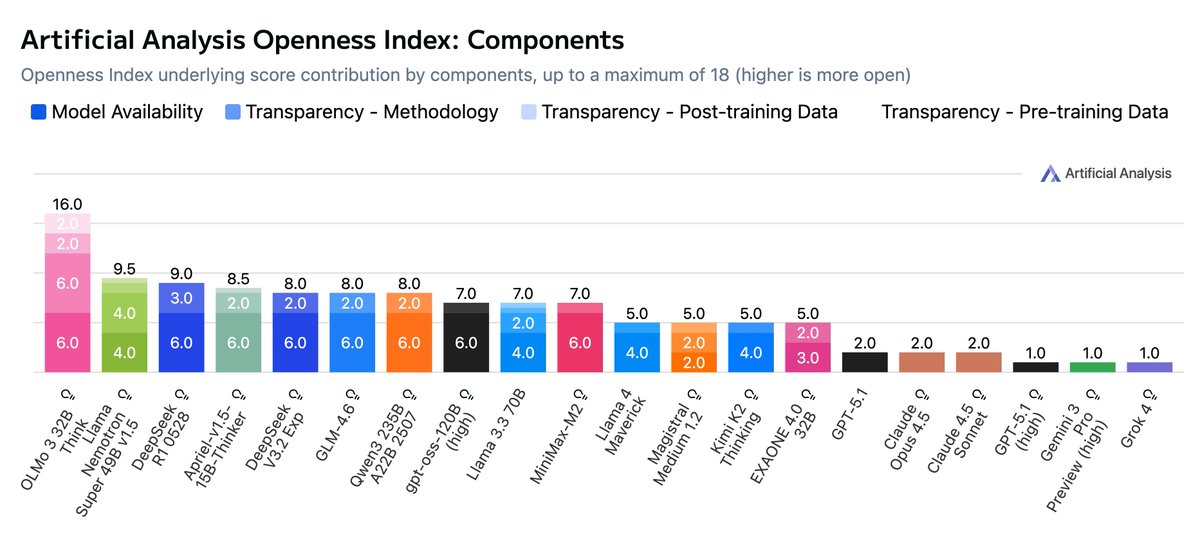 The Openness Index breaks down a total of 18 points across the four subcomponents, and we then represent the overall value on a normalized 0-100 scale. We will continue to review and iterate this framework as the model ecosystem develops and new factors emerge.
The Openness Index breaks down a total of 18 points across the four subcomponents, and we then represent the overall value on a normalized 0-100 scale. We will continue to review and iterate this framework as the model ecosystem develops and new factors emerge. 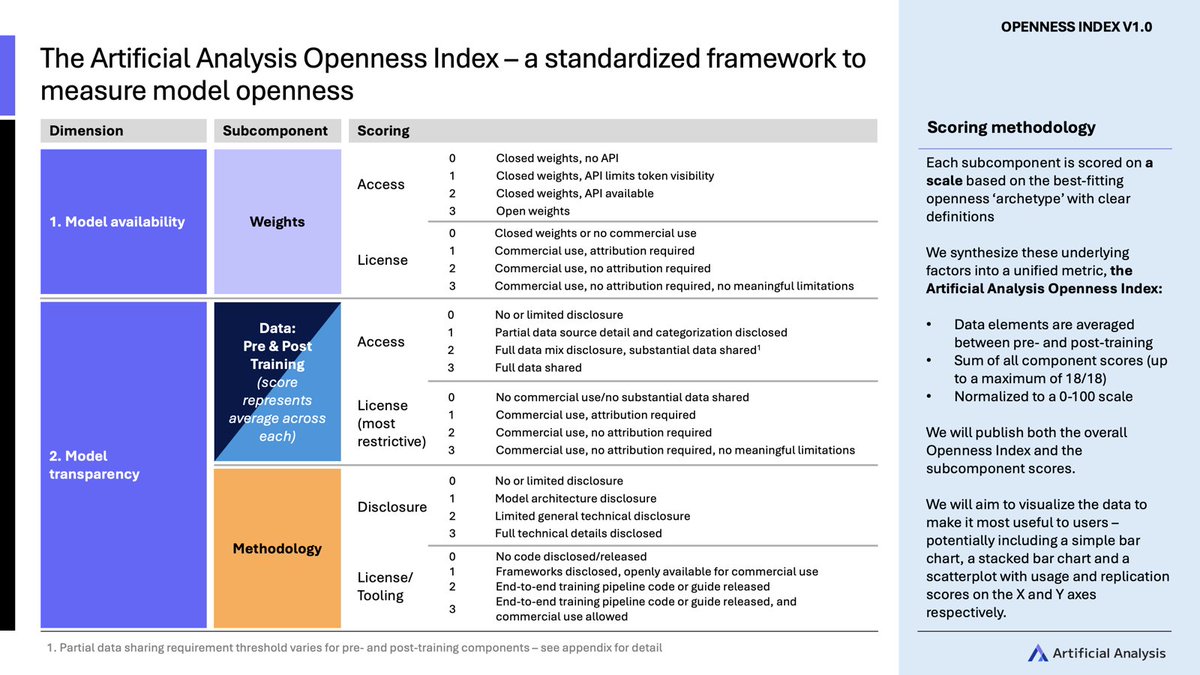
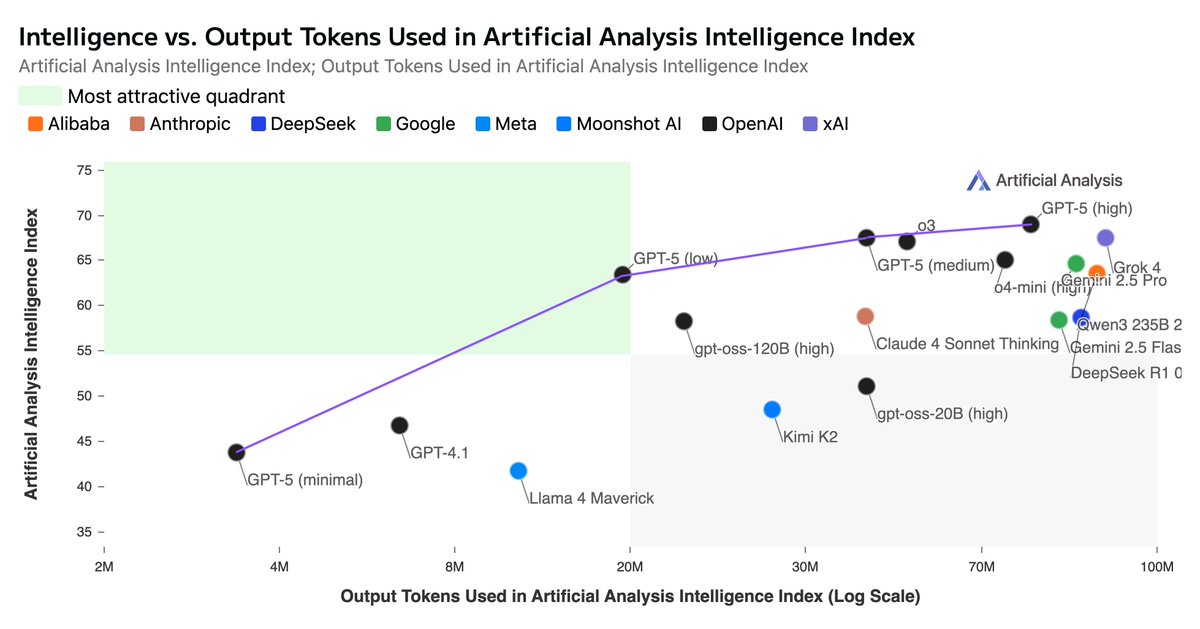
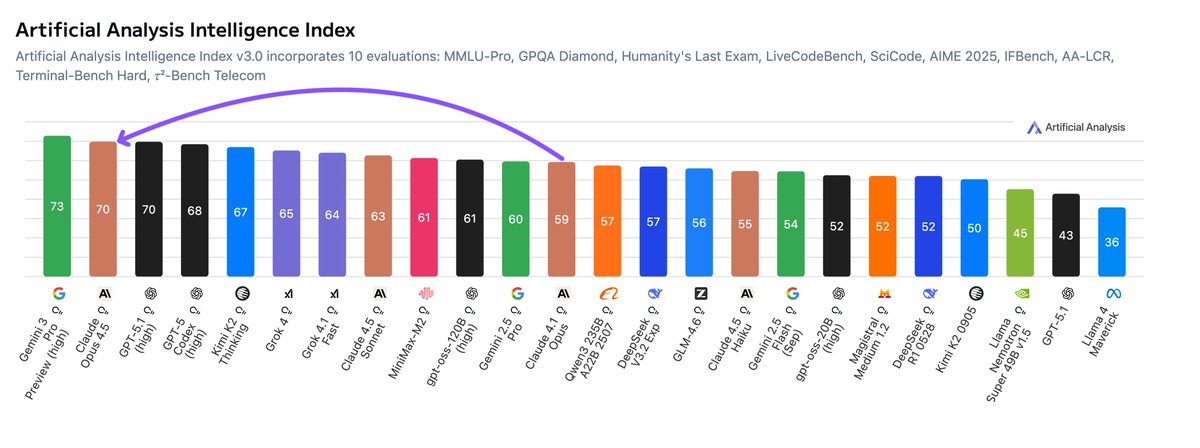 A key differentiator for the Claude models remains that they are substantially more token-efficient than all other reasoning models. Claude Opus 4.5 has significantly increased intelligence without a large increase in output tokens, differing substantially from other model families that rely on greater reasoning at inference time (i.e., more output tokens). On the Output Tokens Used in Artificial Analysis Intelligence Index vs Intelligence Index chart, Claude 4.5 Opus (Thinking) sits on the Pareto frontier.
A key differentiator for the Claude models remains that they are substantially more token-efficient than all other reasoning models. Claude Opus 4.5 has significantly increased intelligence without a large increase in output tokens, differing substantially from other model families that rely on greater reasoning at inference time (i.e., more output tokens). On the Output Tokens Used in Artificial Analysis Intelligence Index vs Intelligence Index chart, Claude 4.5 Opus (Thinking) sits on the Pareto frontier.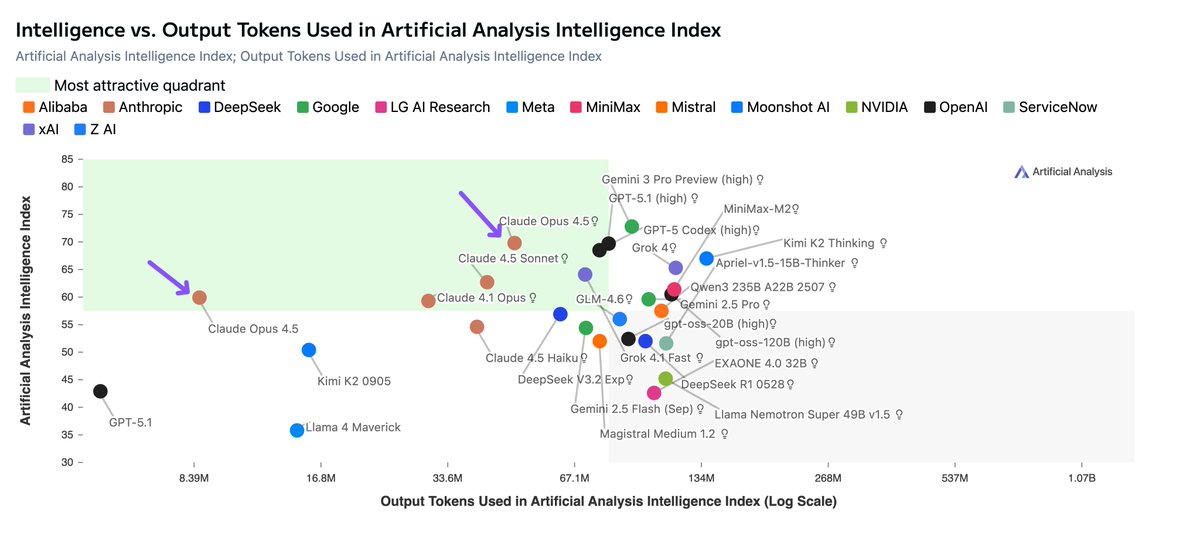
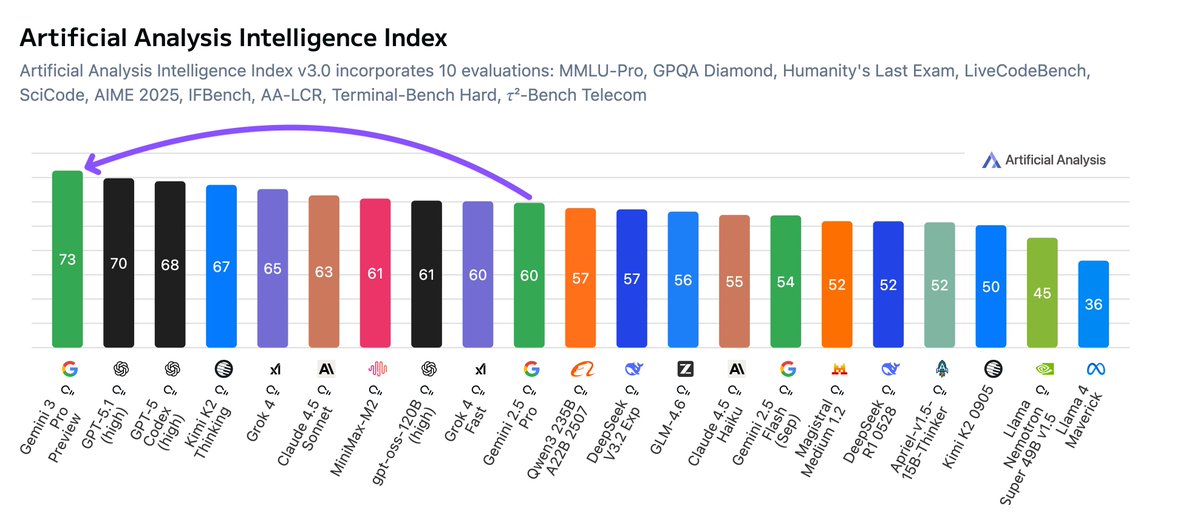 For the first time, Google has the most intelligent model, with Gemini 3 Pro Preview improving on the previous most intelligent model, OpenAI’s GPT-5.1 (high), by 3 points
For the first time, Google has the most intelligent model, with Gemini 3 Pro Preview improving on the previous most intelligent model, OpenAI’s GPT-5.1 (high), by 3 points 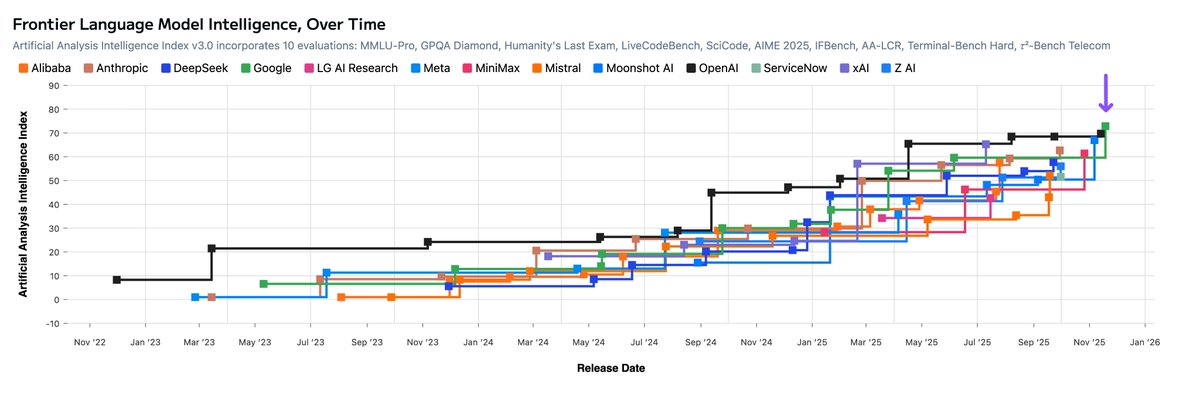
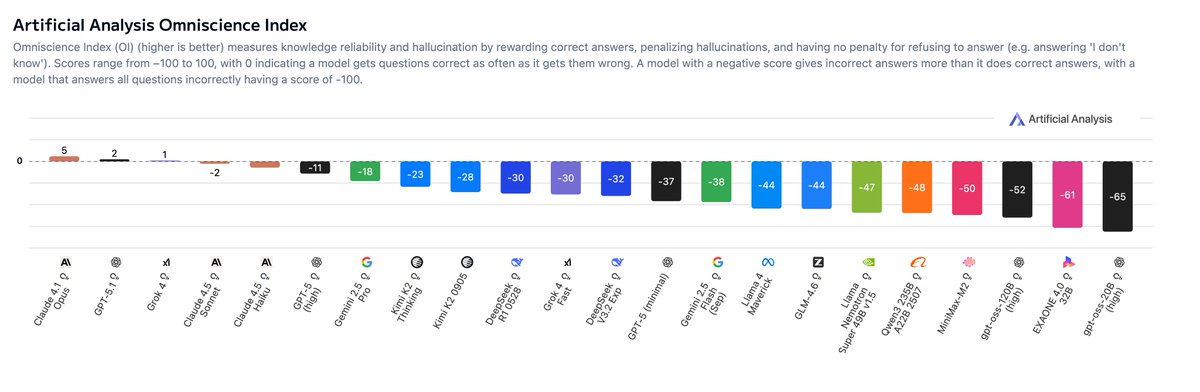 Grok 4 by @xai, GPT-5 by @OpenAI and Gemini 2.5 Pro by @GoogleDeepMind achieve the highest accuracy in AA-Omniscience. The reason they do not achieve the highest Omniscience Index due to the low hallucination rates of @AnthropicAI’s Claude models
Grok 4 by @xai, GPT-5 by @OpenAI and Gemini 2.5 Pro by @GoogleDeepMind achieve the highest accuracy in AA-Omniscience. The reason they do not achieve the highest Omniscience Index due to the low hallucination rates of @AnthropicAI’s Claude models 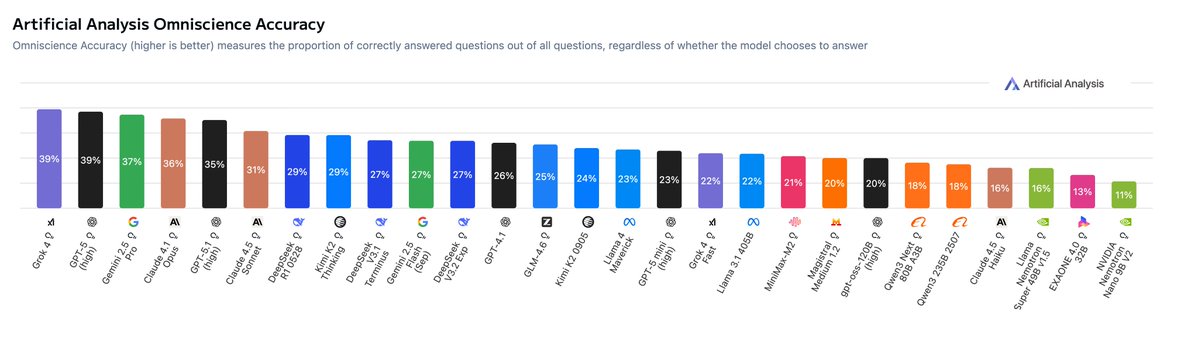
 Sample prompt on Inworld TTS 1 Max: “Your gut microbiome contains trillions of bacteria that influence digestion, immunity, and even mental health through the gut-brain axis.”
Sample prompt on Inworld TTS 1 Max: “Your gut microbiome contains trillions of bacteria that influence digestion, immunity, and even mental health through the gut-brain axis.”

 Granite 4.0 H Small’s (Non Reasoning) output token efficiency and per token pricing offers a compelling tradeoff between intelligence and Cost to Run Artificial Analysis Intelligence Index
Granite 4.0 H Small’s (Non Reasoning) output token efficiency and per token pricing offers a compelling tradeoff between intelligence and Cost to Run Artificial Analysis Intelligence Index 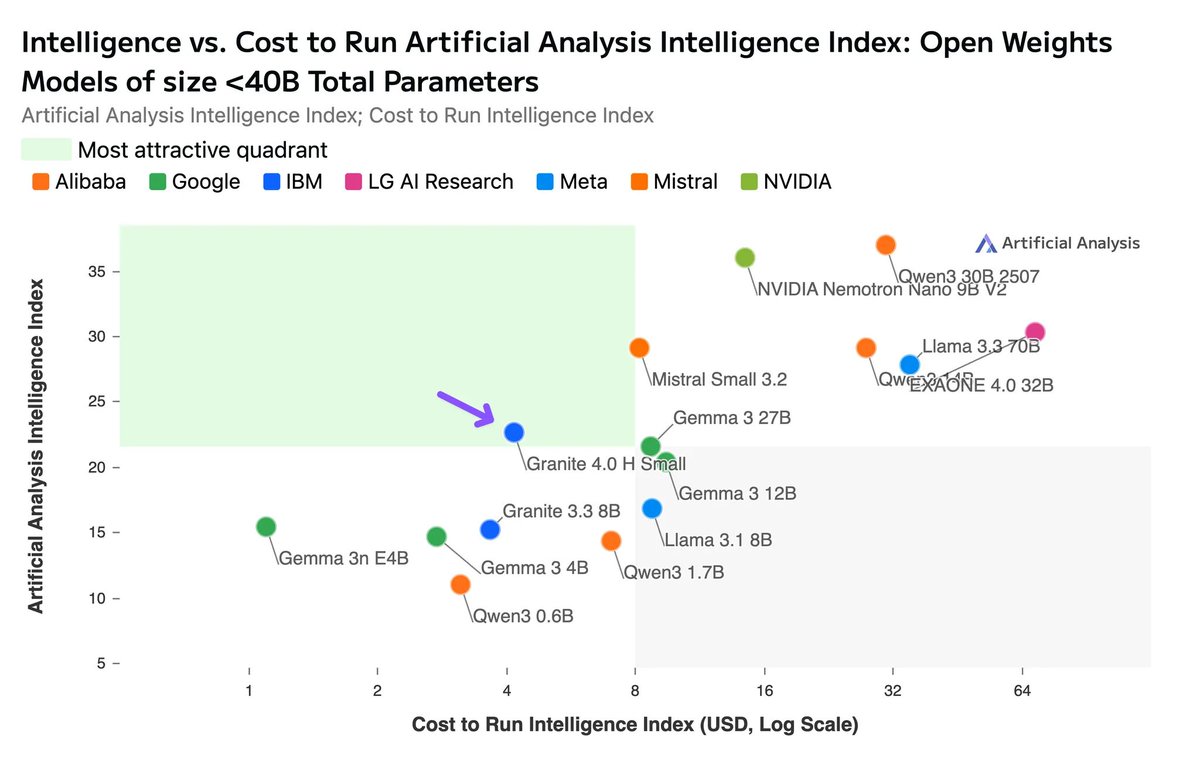
 [Prompt 1/5] Change the sign to state "SCHOOL Zone Ahead”
[Prompt 1/5] Change the sign to state "SCHOOL Zone Ahead” 
 Token usage (verbosity): GPT-5 with reasoning effort high uses 23X more tokens than with reasoning effort minimal. Though in doing so achieves substantial intelligence gains, between medium and high there is less of an uplift.
Token usage (verbosity): GPT-5 with reasoning effort high uses 23X more tokens than with reasoning effort minimal. Though in doing so achieves substantial intelligence gains, between medium and high there is less of an uplift.

 Intelligence vs. Total Parameters: gpt-oss-120B is the most intelligence model that can fit on a single H100 GPU in its native precision.
Intelligence vs. Total Parameters: gpt-oss-120B is the most intelligence model that can fit on a single H100 GPU in its native precision.
 Full suit of our independent intelligence evaluations:
Full suit of our independent intelligence evaluations: 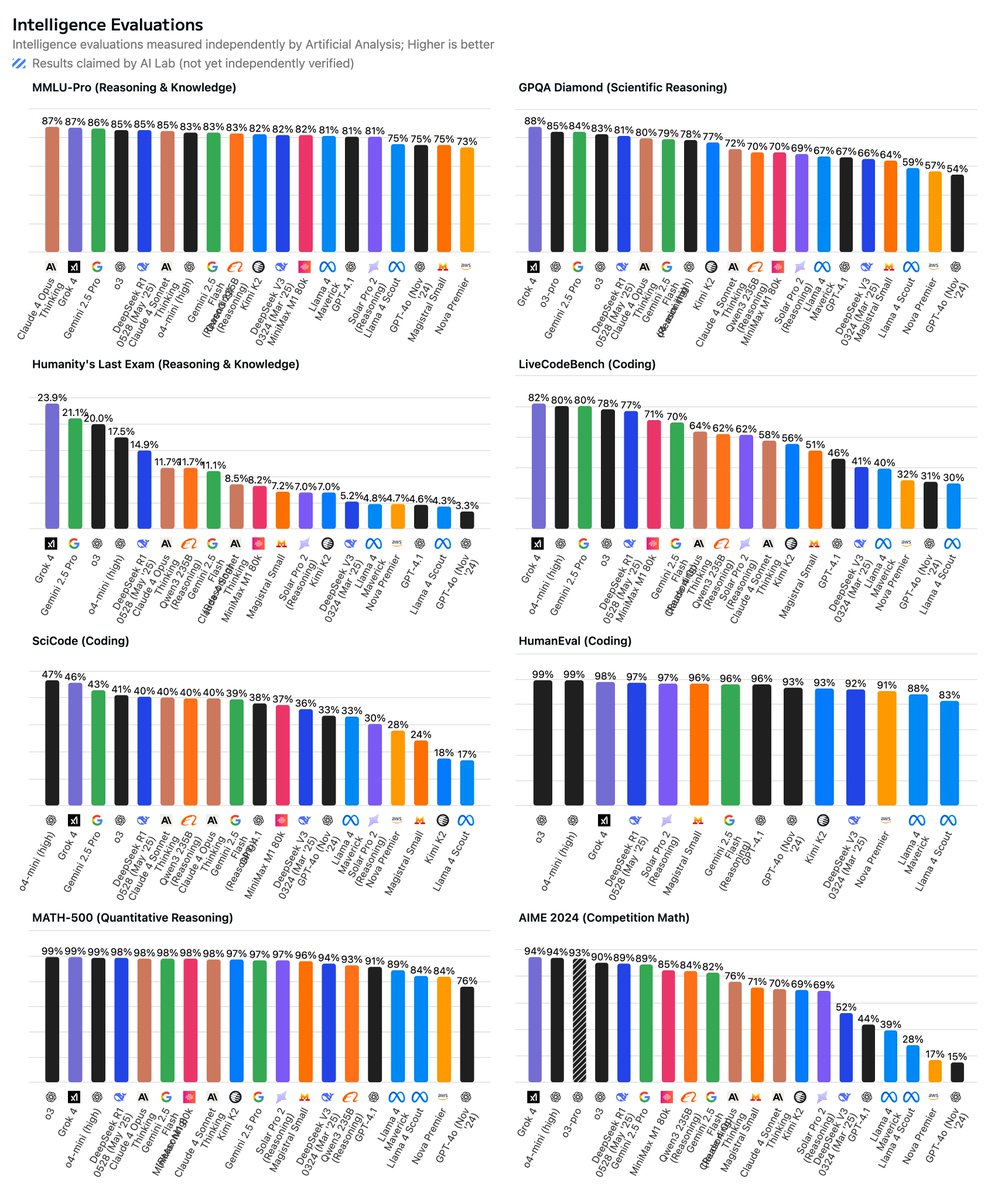
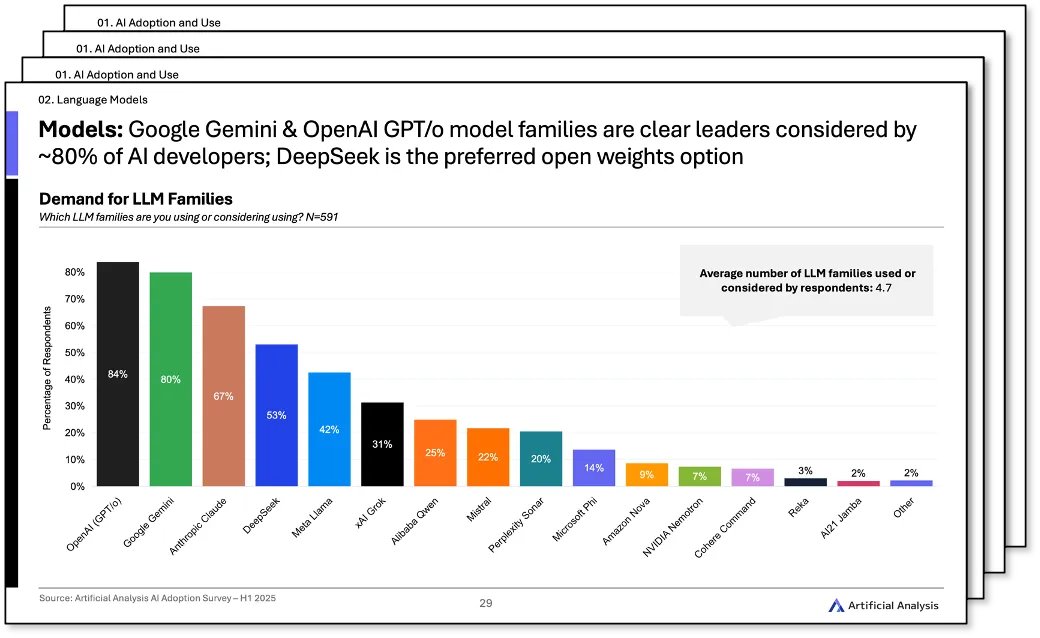 ChatGPT dominates AI chat adoption, followed by Gemini and Claude. Other notable players include Perplexity, xAI Grok and Microsoft Copilot
ChatGPT dominates AI chat adoption, followed by Gemini and Claude. Other notable players include Perplexity, xAI Grok and Microsoft Copilot 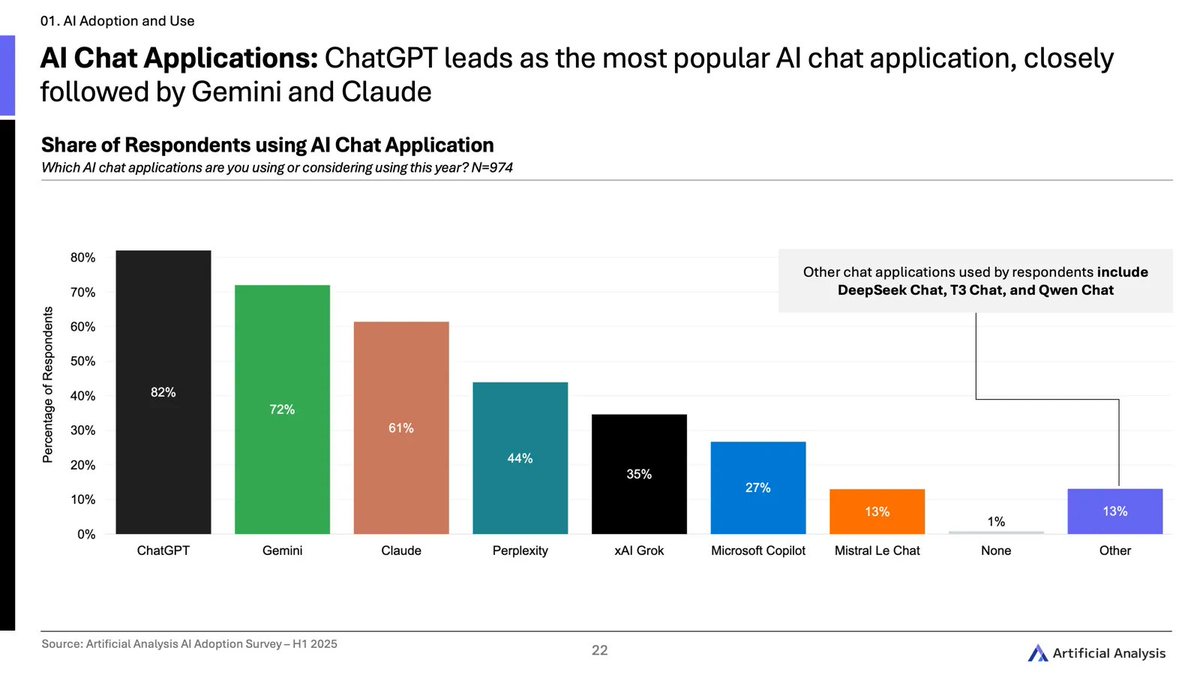
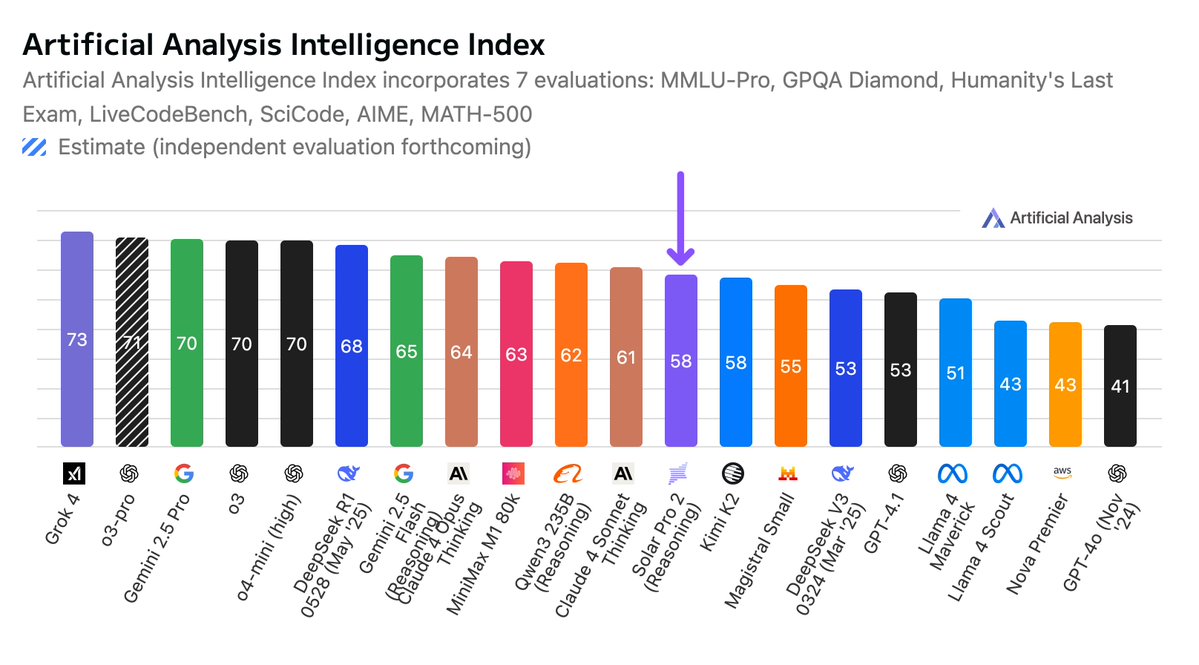
 Grok 4 scores higher in Artificial Analysis Intelligence Index than any other model. Its pricing is higher than OpenAI’s o3, Google’s Gemini 2.5 Pro and Anthropic’s Claude 4 Sonnet - but lower than Anthropic’s Claude 4 Opus and OpenAI’s o3-pro.
Grok 4 scores higher in Artificial Analysis Intelligence Index than any other model. Its pricing is higher than OpenAI’s o3, Google’s Gemini 2.5 Pro and Anthropic’s Claude 4 Sonnet - but lower than Anthropic’s Claude 4 Opus and OpenAI’s o3-pro. 

 Google has consistently been shipping intelligence increases in its Gemini Pro series
Google has consistently been shipping intelligence increases in its Gemini Pro series 
 DeepSeek has maintained its status as amongst AI labs leading in frontier AI intelligence
DeepSeek has maintained its status as amongst AI labs leading in frontier AI intelligence 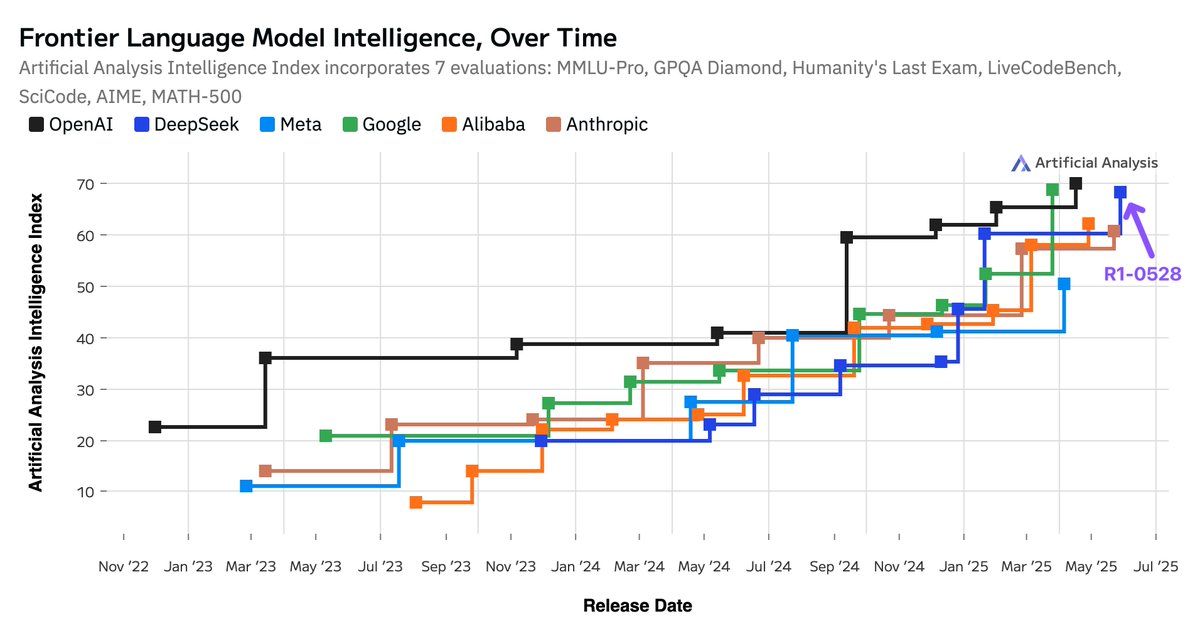
 Breakdown of token usage, pricing and end-to-end latency.
Breakdown of token usage, pricing and end-to-end latency. 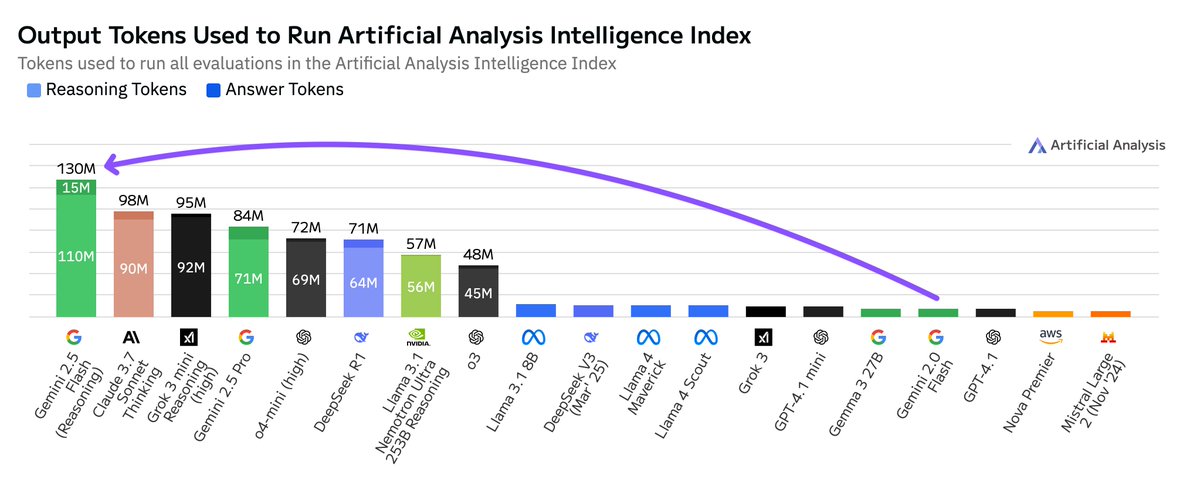

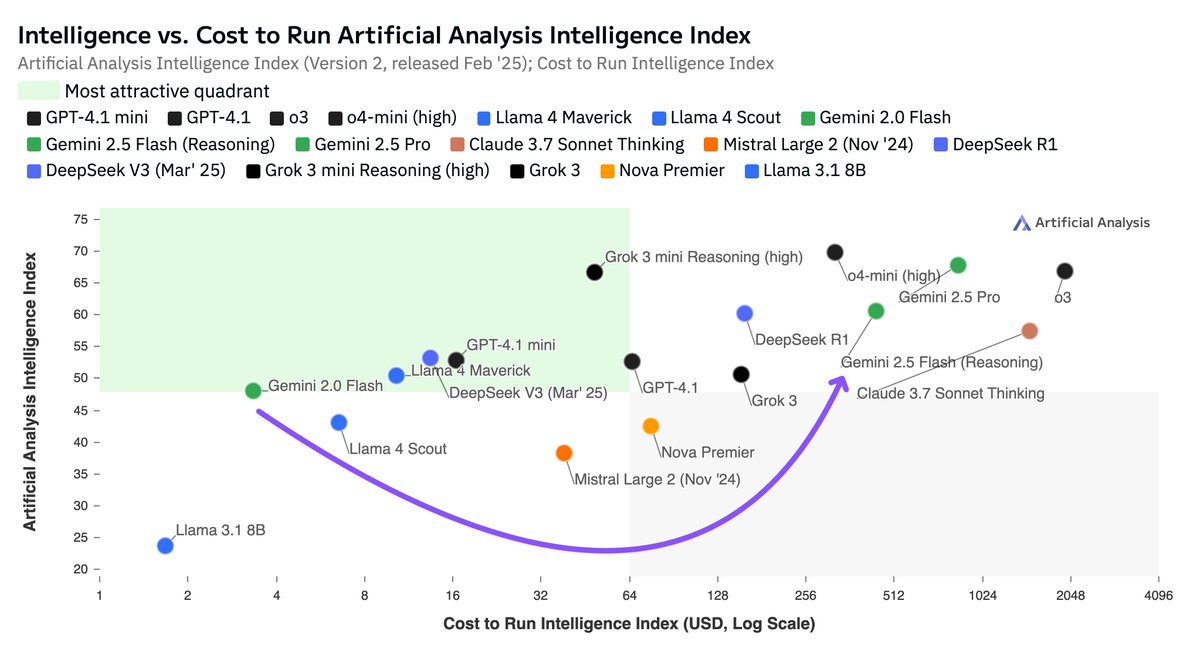

 GPT-4o (March 2025) is now the leading non-reasoning coding model, surpassing DeepSeek V3 (March 2025) and Claude 3.7 Sonnet in the Artificial Analysis Coding Index (made up of LiveCodeBench and SciCode) and is #1 in LiveCodeBench
GPT-4o (March 2025) is now the leading non-reasoning coding model, surpassing DeepSeek V3 (March 2025) and Claude 3.7 Sonnet in the Artificial Analysis Coding Index (made up of LiveCodeBench and SciCode) and is #1 in LiveCodeBench 
