
BREAKING: Apple just proved AI "reasoning" models like Claude, DeepSeek-R1, and o3-mini don't actually reason at all.
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)
They just memorize patterns really well.
Here's what Apple discovered:
(hint: we're not as close to AGI as the hype suggests)

Instead of using the same old math tests that AI companies love to brag about, Apple created fresh puzzle games.
They tested Claude Thinking, DeepSeek-R1, and o3-mini on problems these models had never seen before.
The result ↓
They tested Claude Thinking, DeepSeek-R1, and o3-mini on problems these models had never seen before.
The result ↓
All "reasoning" models hit a complexity wall where they completely collapse to 0% accuracy.
No matter how much computing power you give them, they can't solve harder problems.
No matter how much computing power you give them, they can't solve harder problems.

As problems got harder, these "thinking" models actually started thinking less.
They used fewer tokens and gave up faster, despite having unlimited budget.
They used fewer tokens and gave up faster, despite having unlimited budget.
Apple researchers even tried giving the models the exact solution algorithm.
Like handing someone step-by-step instructions to bake a cake.
The models still failed at the same complexity points.
They can't even follow directions consistently.
Like handing someone step-by-step instructions to bake a cake.
The models still failed at the same complexity points.
They can't even follow directions consistently.
The research revealed three regimes:
• Low complexity: Regular models actually win
• Medium complexity: "Thinking" models show some advantage
• High complexity: Everything breaks down completely
Most problems fall into that third category.
• Low complexity: Regular models actually win
• Medium complexity: "Thinking" models show some advantage
• High complexity: Everything breaks down completely
Most problems fall into that third category.
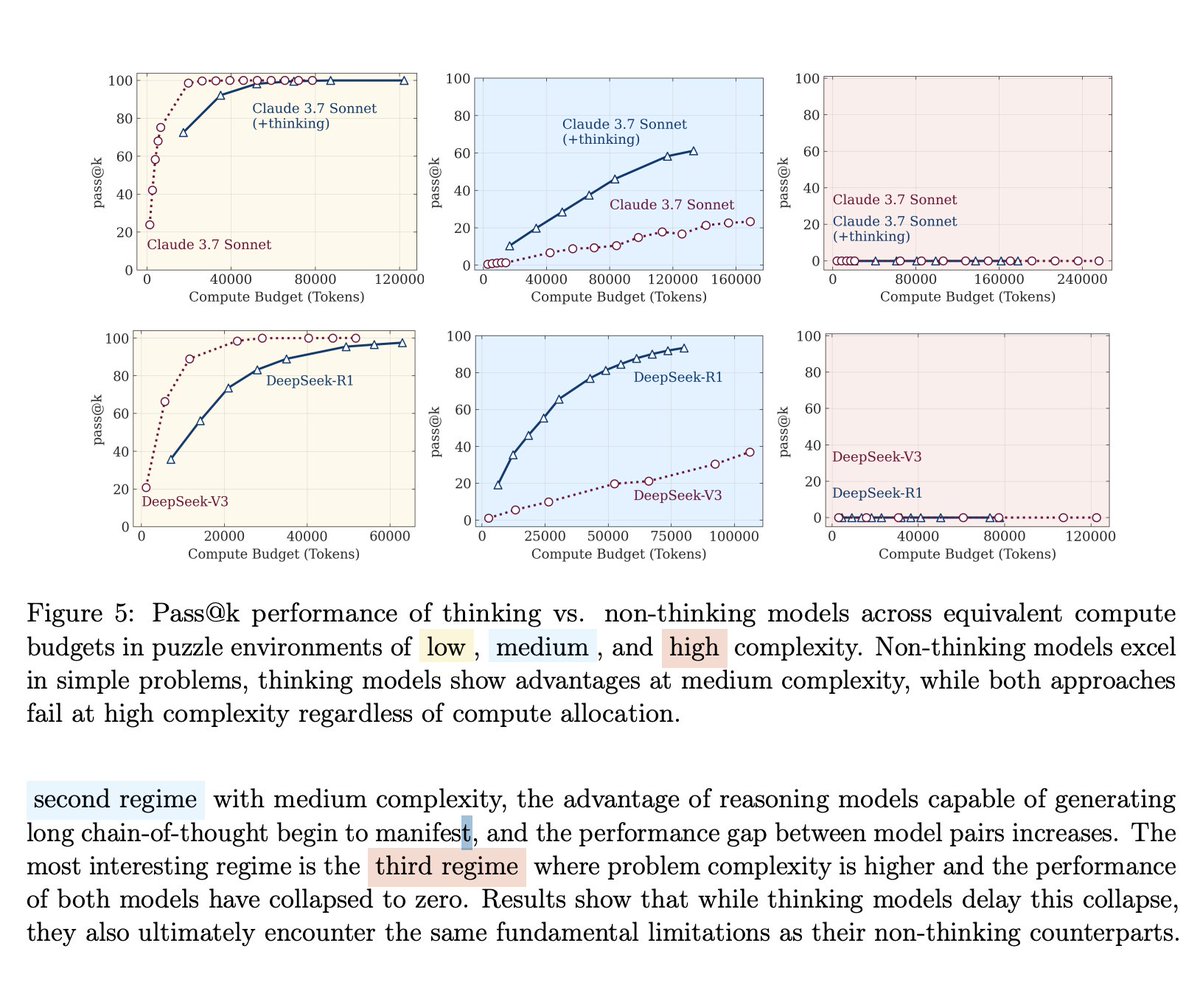
Apple discovered that these models are not reasoning at all, but instead doing sophisticated pattern matching that works great until patterns become too complex.
Then they fall apart like a house of cards.
Then they fall apart like a house of cards.
If these models were truly "reasoning," they should get better with more compute and clearer instructions.
Instead, they hit hard walls and start giving up.
Is that intelligence or memorization hitting its limits?
Instead, they hit hard walls and start giving up.
Is that intelligence or memorization hitting its limits?
This research suggests we're not as close to AGI as the hype suggests.
Current "reasoning" breakthroughs may be hitting fundamental walls that can't be solved by just adding more data or compute.
Current "reasoning" breakthroughs may be hitting fundamental walls that can't be solved by just adding more data or compute.
Models could handle 100+ moves in Tower of Hanoi puzzles but failed after just 4 moves in River Crossing puzzles.
This suggests they memorized Tower of Hanoi solutions during training but can't actually reason.
This suggests they memorized Tower of Hanoi solutions during training but can't actually reason.

While AI companies celebrate their models "thinking," Apple basically said "Everyone's celebrating fake reasoning."
The industry is chasing metrics that don't measure actual intelligence.
The industry is chasing metrics that don't measure actual intelligence.
Apple's researchers used controllable puzzle environments specifically because:
• They avoid data contamination
• They require pure logical reasoning
• They can scale complexity precisely
• They reveal where models actually break
Smart experimental design if you ask me.
• They avoid data contamination
• They require pure logical reasoning
• They can scale complexity precisely
• They reveal where models actually break
Smart experimental design if you ask me.
What do you think?
Is Apple just "coping" because they've been outpaced in AI developments over the past two years?
Or is Apple correct?
Comment below and I'll respond to all.
Is Apple just "coping" because they've been outpaced in AI developments over the past two years?
Or is Apple correct?
Comment below and I'll respond to all.
If you found this thread valuable:
1. Follow me @RubenHssd for more threads around what's happening around AI and it's implications.
2. RT the first tweet
1. Follow me @RubenHssd for more threads around what's happening around AI and it's implications.
2. RT the first tweet
https://twitter.com/1269541526/status/1931389580105925115
• • •
Missing some Tweet in this thread? You can try to
force a refresh
















