This is really BAD news of LLM's coding skill. ☹️
The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel.
LiveCodeBench Pro, a benchmark composed of
problems from Codeforces, ICPC, and IOI (“International Olympiad in Informatics”) that are continuously updated to reduce the likelihood
of data contamination.
The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel.
LiveCodeBench Pro, a benchmark composed of
problems from Codeforces, ICPC, and IOI (“International Olympiad in Informatics”) that are continuously updated to reduce the likelihood
of data contamination.

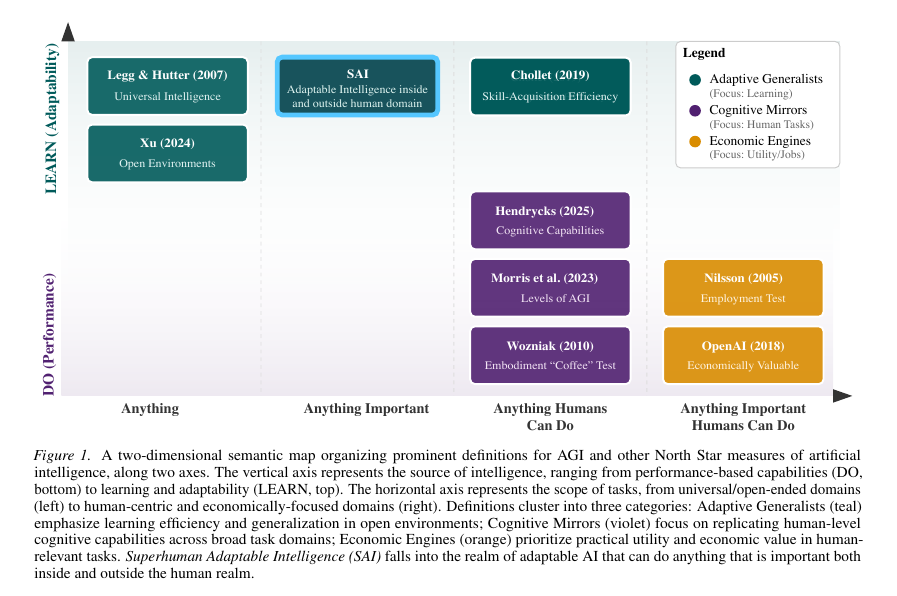
📌 The Gap Targeted
Earlier reports claimed frontier LLMs now top human grandmasters, but a cost-versus-rating plot proves otherwise.
Even the best model o4-mini-high sits near 2 100 Elo once tool calls are blocked, far from the 2 700 legend line that marks real grandmasters
Earlier reports claimed frontier LLMs now top human grandmasters, but a cost-versus-rating plot proves otherwise.
Even the best model o4-mini-high sits near 2 100 Elo once tool calls are blocked, far from the 2 700 legend line that marks real grandmasters

🗂️ Building the Benchmark
A medal-winner team harvests each Codeforces, ICPC, and IOI problem as soon as a contest ends, before editorials appear, wiping out training leakage.
They store 584 tasks and tag each one as knowledge, logic, or observation heavy, producing a balanced skill matrix .
A medal-winner team harvests each Codeforces, ICPC, and IOI problem as soon as a contest ends, before editorials appear, wiping out training leakage.
They store 584 tasks and tag each one as knowledge, logic, or observation heavy, producing a balanced skill matrix .

📊 Rating Models Fairly
Every submission is treated as a chess game against the task’s official difficulty.
A Bayesian MAP Elo fit assigns the only rating that matches human percentiles and strips out typing-speed bias
Every submission is treated as a chess game against the task’s official difficulty.
A Bayesian MAP Elo fit assigns the only rating that matches human percentiles and strips out typing-speed bias

🎯 Where Models Shine and Fail
Figure 2 shows models sail through template zones like segment trees or dynamic programming yet plunge below 1 500 Elo on game theory, greedy tricks, and messy case work .
Zero hard-tier solves confirm the cliff.
Figure 2 shows models sail through template zones like segment trees or dynamic programming yet plunge below 1 500 Elo on game theory, greedy tricks, and messy case work .
Zero hard-tier solves confirm the cliff.

🔍 Why Submissions Fail
A treemap comparison finds o3-mini commits many wrong algorithms and missed insights while humans mainly slip on implementation details.
Models also trip on samples they never run locally, something human coders catch instantly
A treemap comparison finds o3-mini commits many wrong algorithms and missed insights while humans mainly slip on implementation details.
Models also trip on samples they never run locally, something human coders catch instantly

🔁 More Tries, Better Outcomes
Letting o4-mini fire ten attempts lifts its rating by about 540 points and doubles medium-tier pass rate, but hard problems remain untouched at 0 %
Letting o4-mini fire ten attempts lifts its rating by about 540 points and doubles medium-tier pass rate, but hard problems remain untouched at 0 %

🧠 Does Reasoning Help
Adding explicit chain-of-thought boosts combinatorics by up to 1 400 Elo and lifts knowledge tags, yet barely moves observation tags such as greedy or ad-hoc, hinting current reasoning traces miss the aha moment
Adding explicit chain-of-thought boosts combinatorics by up to 1 400 Elo and lifts knowledge tags, yet barely moves observation tags such as greedy or ad-hoc, hinting current reasoning traces miss the aha moment

💰 Terminal Power Matters
The authors estimate around 400 Elo of the published 2 700 score comes from terminal access that lets a model compile, unit-test, and brute-force patterns during inference
The authors estimate around 400 Elo of the published 2 700 score comes from terminal access that lets a model compile, unit-test, and brute-force patterns during inference

I also publish my newsletter every single day.
→ 🗞️
Includes:
- Top 1% AI Industry developments
- Influential research papers with analysis
📚 Subscribe and get a 1300+page Python book instantly. rohan-paul.com
→ 🗞️
Includes:
- Top 1% AI Industry developments
- Influential research papers with analysis
📚 Subscribe and get a 1300+page Python book instantly. rohan-paul.com
• • •
Missing some Tweet in this thread? You can try to
force a refresh