
Compiling in real-time, the race towards AGI.
The Largest Show on X for AI.
🗞️ Get my daily AI analysis newsletter to your email 👉 https://t.co/6LBxO8215l
 63% of U.S. adults say AI is advancing too quickly, compared with 19% who think the pace is right, 16% who are unsure, and just 2% who think it is moving too slowly.
63% of U.S. adults say AI is advancing too quickly, compared with 19% who think the pace is right, 16% who are unsure, and just 2% who think it is moving too slowly. 
 This visual maps different AI goals to show how adaptable intelligence completely beats older performance ideas.
This visual maps different AI goals to show how adaptable intelligence completely beats older performance ideas.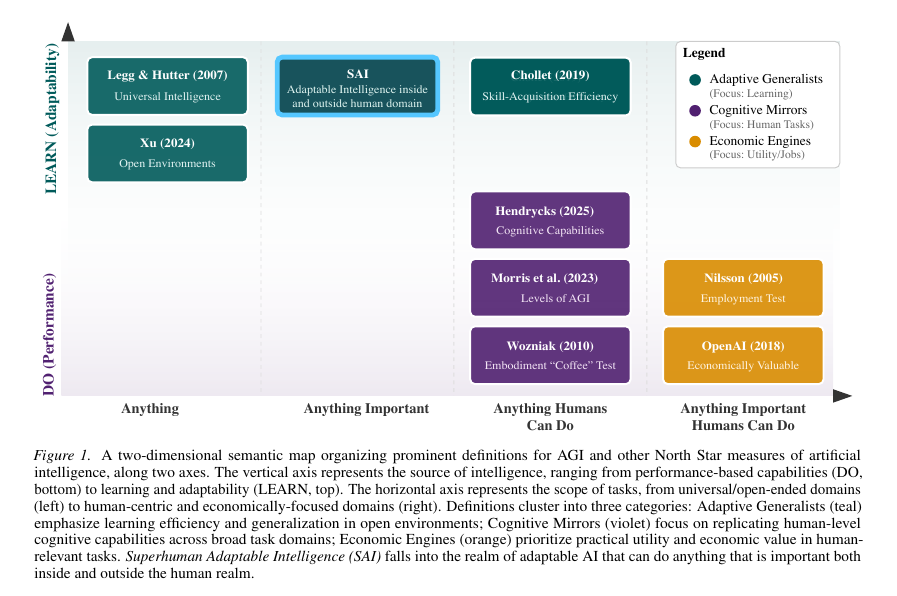
 war.gov/News/Releases/…
war.gov/News/Releases/…
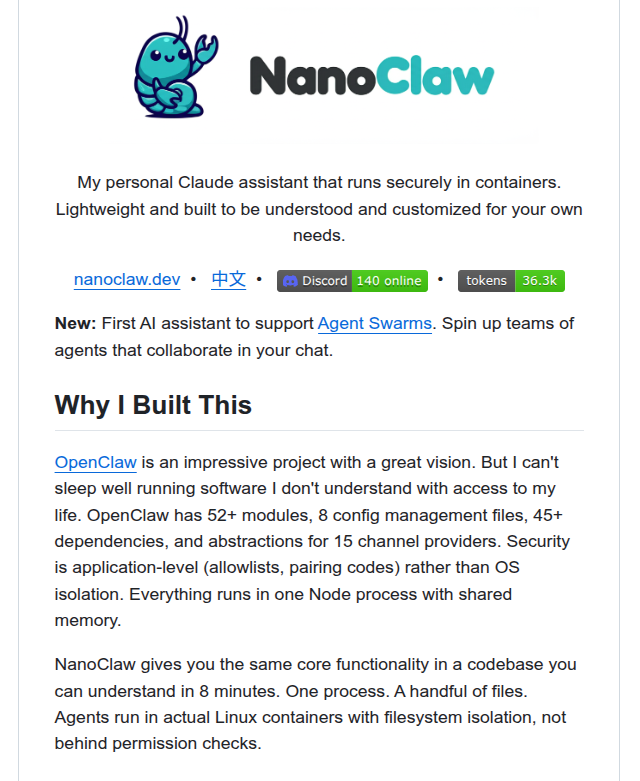 github.com/qwibitai/nanoc…
github.com/qwibitai/nanoc…
 🧵 2. The diagram compares a standard Transformer attention block on the right with the “hybrid” replacement block on the left.
🧵 2. The diagram compares a standard Transformer attention block on the right with the “hybrid” replacement block on the left.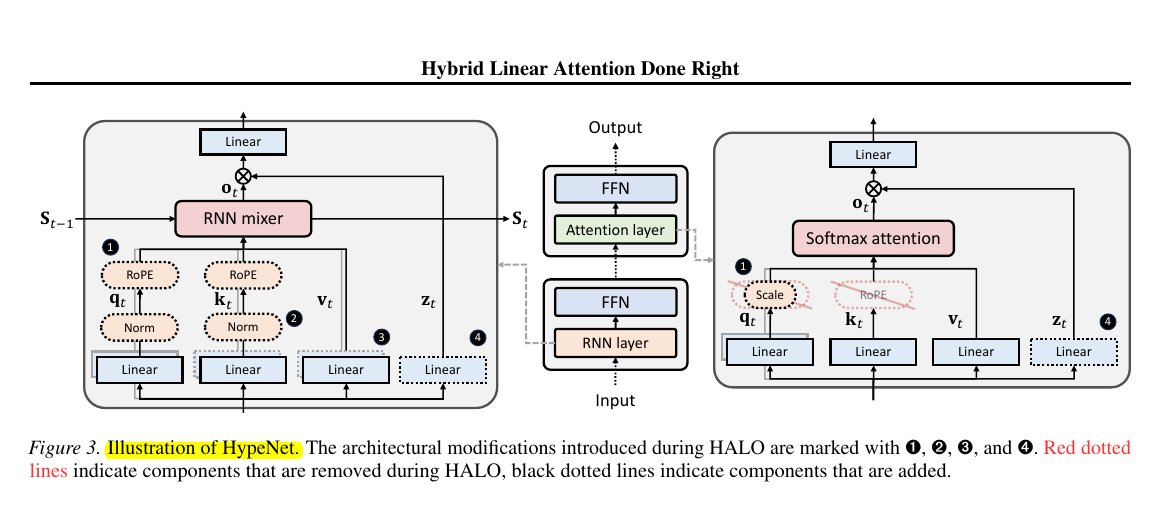
 🧩 The core problem
🧩 The core problem
 🧠 The idea
🧠 The idea
 This image compares 3 ways to build the shortcut path that carries information around a layer in a transformer.
This image compares 3 ways to build the shortcut path that carries information around a layer in a transformer.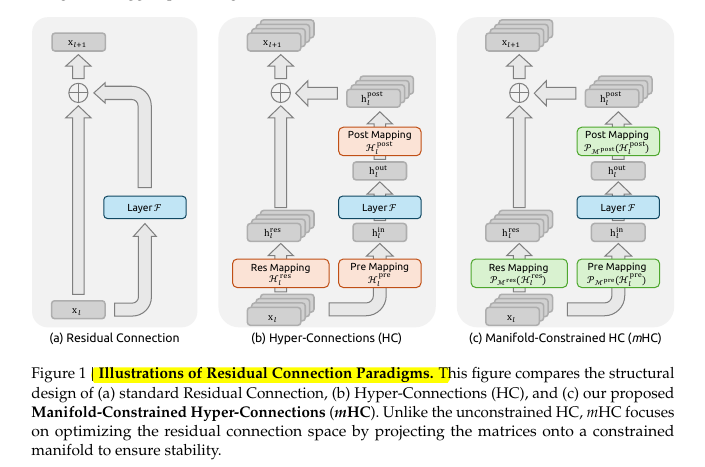
 Overview of the evolution of code large language models (Code-LLMs) and related ecosystems from 2021 to 2025.
Overview of the evolution of code large language models (Code-LLMs) and related ecosystems from 2021 to 2025. 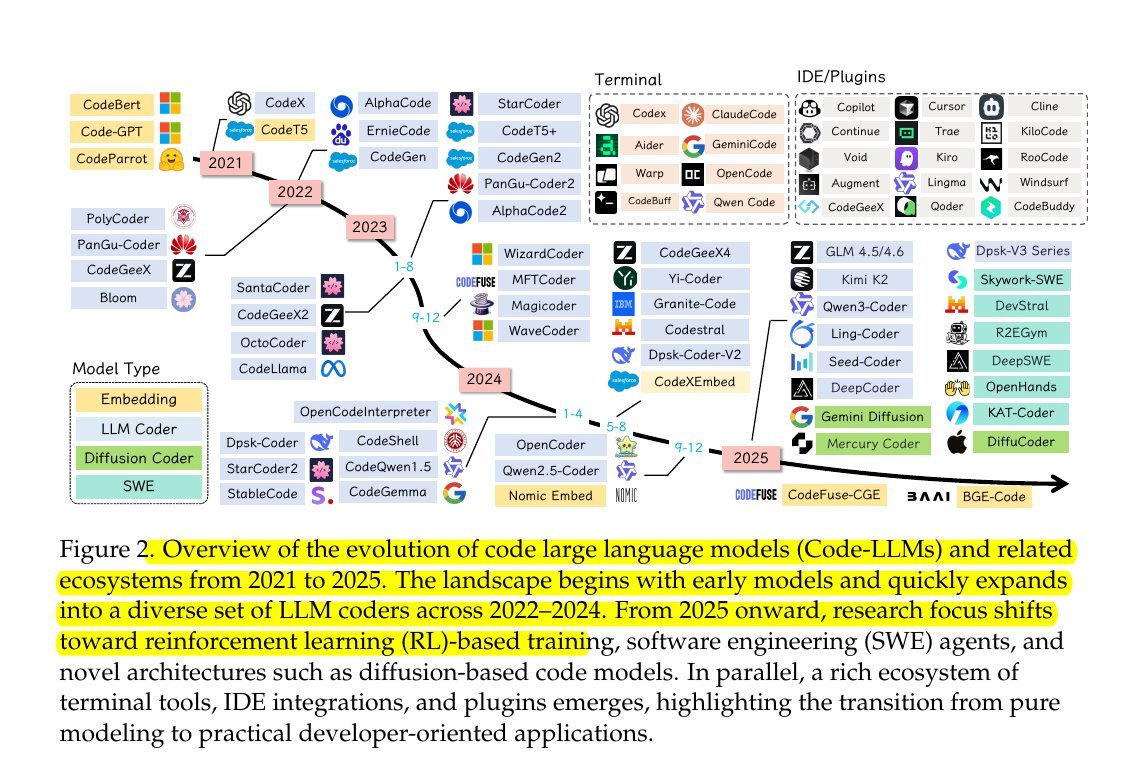
 Overview of the evolution of code large language models (Code-LLMs) and related ecosystems from 2021 to 2025.
Overview of the evolution of code large language models (Code-LLMs) and related ecosystems from 2021 to 2025. 


 🧵2/n. ⚙️ The Core Concepts
🧵2/n. ⚙️ The Core Concepts
 2. AI spending is significant in historical terms
2. AI spending is significant in historical terms 
 🧵2/n. ⚙️ The Core Concepts
🧵2/n. ⚙️ The Core Concepts
 🧵2/n. The 3 steps used to train Trading-R1.
🧵2/n. The 3 steps used to train Trading-R1.
 🧵2/n. ⚙️ The Core Concepts
🧵2/n. ⚙️ The Core Concepts
 Average accuracy and range across 10 runs for five different tones
Average accuracy and range across 10 runs for five different tones 
 🧵2/n. In summary how LIMI (Less Is More for Intelligent Agency) can score so high with just 78 examples.
🧵2/n. In summary how LIMI (Less Is More for Intelligent Agency) can score so high with just 78 examples.
 🧵2/n. ⚙️ The Core Idea
🧵2/n. ⚙️ The Core Idea