It’s a hefty 206-page research paper, and the findings are concerning.
"LLM users consistently underperformed at neural, linguistic, and behavioral levels"
This study finds LLM dependence weakens the writer’s own neural and linguistic fingerprints. 🤔🤔
Relying only on EEG, text mining, and a cross-over session, the authors show that keeping some AI-free practice time protects memory circuits and encourages richer language even when a tool is later reintroduced.
"LLM users consistently underperformed at neural, linguistic, and behavioral levels"
This study finds LLM dependence weakens the writer’s own neural and linguistic fingerprints. 🤔🤔
Relying only on EEG, text mining, and a cross-over session, the authors show that keeping some AI-free practice time protects memory circuits and encourages richer language even when a tool is later reintroduced.

⚙️ The Experimental Setup
Fifty-four Boston-area students wrote SAT-style essays under three conditions: ChatGPT only, Google only, or brain only.
Each person completed three timed sessions with the same condition, then an optional fourth session in the opposite condition.
A 32-channel Enobio headset recorded brain signals throughout, and every keystroke, prompt, and interview answer was archived for analysis.
Fifty-four Boston-area students wrote SAT-style essays under three conditions: ChatGPT only, Google only, or brain only.
Each person completed three timed sessions with the same condition, then an optional fourth session in the opposite condition.
A 32-channel Enobio headset recorded brain signals throughout, and every keystroke, prompt, and interview answer was archived for analysis.

🧠 Brain Connectivity Results
Alpha and beta networks were strongest when no external tool was allowed, moderate with Google, and weakest with ChatGPT.
Lower coupling during LLM use signals reduced internal attention and memory rehearsal, while high parieto-frontal flow in the brain-only group matches deep semantic processing.
Alpha and beta networks were strongest when no external tool was allowed, moderate with Google, and weakest with ChatGPT.
Lower coupling during LLM use signals reduced internal attention and memory rehearsal, while high parieto-frontal flow in the brain-only group matches deep semantic processing.

📚 Linguistic Patterns
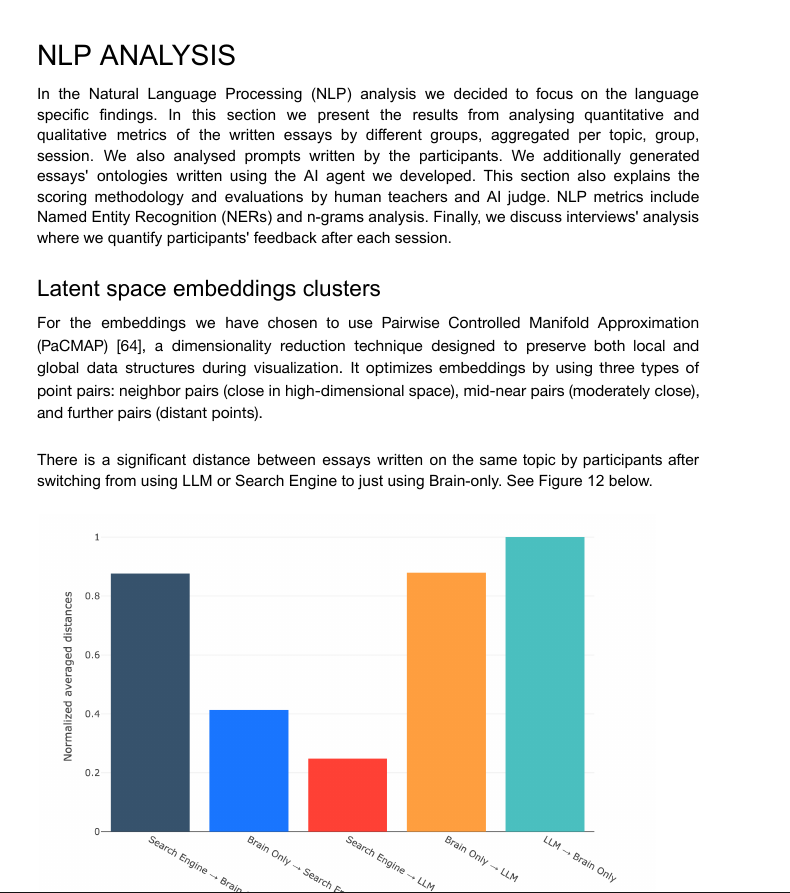
Essays produced with ChatGPT clustered tightly in embedding space and reused the same named entities, showing high textual homogeneity.
Google essays sat in the middle, influenced by search rankings, whereas brain-only essays scattered widely, reflecting individual experience and vocabulary.
Essays produced with ChatGPT clustered tightly in embedding space and reused the same named entities, showing high textual homogeneity.
Google essays sat in the middle, influenced by search rankings, whereas brain-only essays scattered widely, reflecting individual experience and vocabulary.
📝 Memory and Ownership
After writing, only 17 % of ChatGPT users could quote their own sentences, versus 89 % in the brain-only group.
ChatGPT writers also reported the weakest sense of authorship, matching EEG evidence of reduced self-monitoring hubs.
After writing, only 17 % of ChatGPT users could quote their own sentences, versus 89 % in the brain-only group.
ChatGPT writers also reported the weakest sense of authorship, matching EEG evidence of reduced self-monitoring hubs.

🔄 Crossover Effects
When habitual ChatGPT users had to write unaided, their connectivity and quoting remained low, suggesting lingering cognitive debt.
In contrast, brain-only writers who switched to ChatGPT lit up wide networks and produced richer revisions, showing that tool use after deep practice boosts, rather than blunts, engagement.
When habitual ChatGPT users had to write unaided, their connectivity and quoting remained low, suggesting lingering cognitive debt.
In contrast, brain-only writers who switched to ChatGPT lit up wide networks and produced richer revisions, showing that tool use after deep practice boosts, rather than blunts, engagement.

⚖️ Cognitive Load Implications
LLMs cut extraneous load by 32 % and extend productive time, yet they also trim germane load, so schema building suffers unless learners deliberately integrate ideas themselves.
LLMs cut extraneous load by 32 % and extend productive time, yet they also trim germane load, so schema building suffers unless learners deliberately integrate ideas themselves.

🔍 Echo-Chamber Risk
Because a probabilistic model favors agreeable continuations, ChatGPT can tighten information loops more than a search page, shrinking exposure to contrasting facts and dulling critical thought.
Hooking sentence options
Because a probabilistic model favors agreeable continuations, ChatGPT can tighten information loops more than a search page, shrinking exposure to contrasting facts and dulling critical thought.
Hooking sentence options

Percentage of participants within each group who struggled to quote anything from their essays

Percentage of participants within each group who provided a correct quote from their essays in Session

Relative reported percentage of perceived ownership of essay by the participants in comparison to the
Brain-only group
Brain-only group

• • •
Missing some Tweet in this thread? You can try to
force a refresh