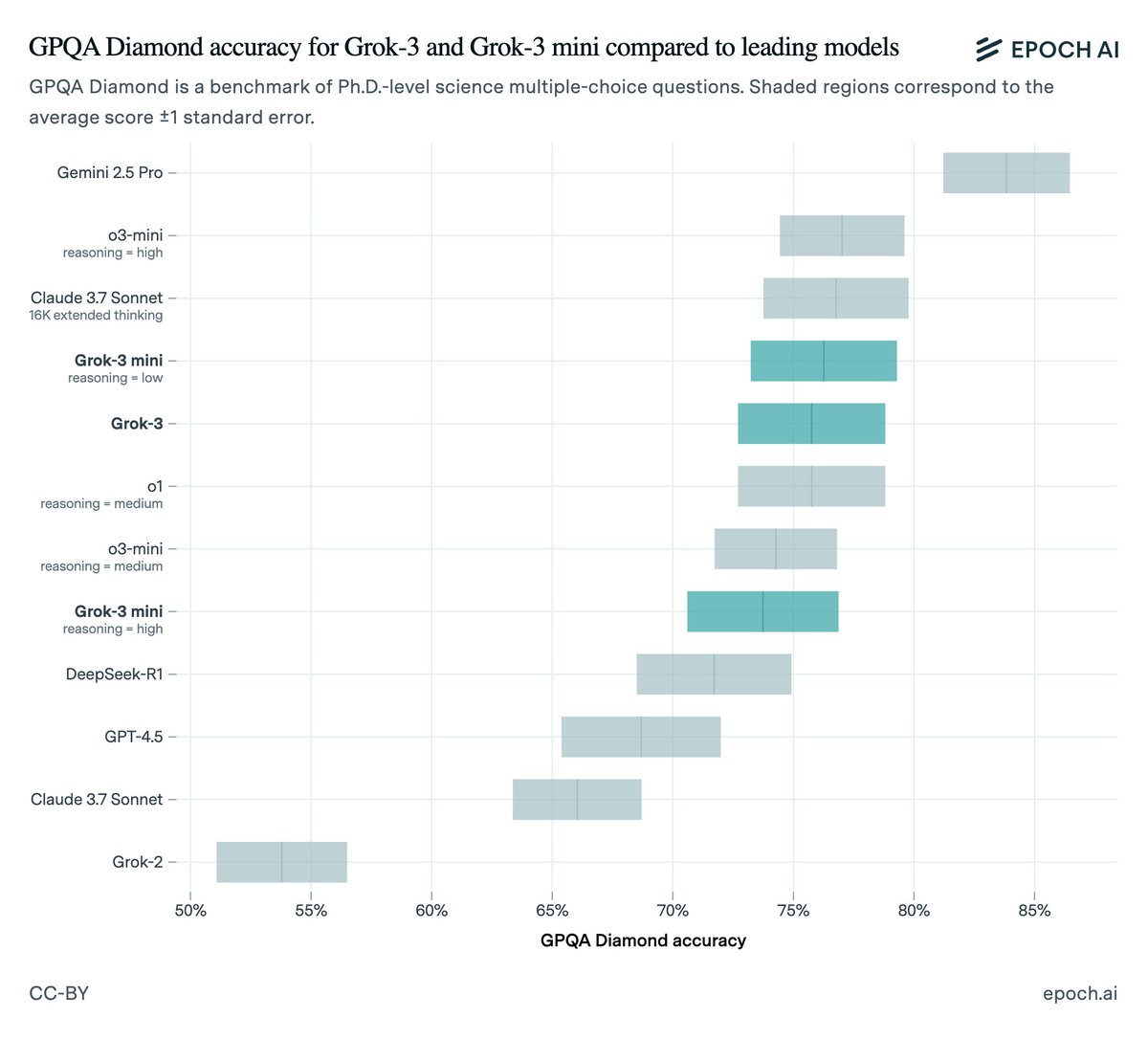
The bottlenecks to >10% GDP growth are weaker than expected, and existing $500B investments in Stargate may be tiny relative to optimal AI investment
In this week’s Gradient Update, @APotlogea and @ansonwhho explain how their work on the economics of AI brought them to this view
In this week’s Gradient Update, @APotlogea and @ansonwhho explain how their work on the economics of AI brought them to this view

@APotlogea @ansonwhho Skepticism around explosive AI growth often hinges on "Baumol effects"—bottlenecks from human-dependent tasks. But to their surprise, the most comprehensive integrated assessment model of AI to date suggests these constraints are weaker than expected
https://x.com/EpochAIResearch/status/1902802037752111569
@APotlogea @ansonwhho Contrary to their expectations, even very partial AI automation—just 30% of tasks—can lead to growth rates above 20% under best-guess parameters. Achieving explosive growth (>30%) requires around 50-70% automation, still well below full automation

@APotlogea @ansonwhho Even when Baumol effects are strengthened well beyond their best guesses, growth rates still accelerate dramatically – exceeding 10% annual growth rates, like those observed in some East Asian economies during the 20th century

@APotlogea @ansonwhho The model’s predictions are of course overly aggressive, but to their surprise, additional bottlenecks like R&D externalities, investor uncertainty, and labor reallocation frictions typically fail to prevent these huge growth accelerations
@APotlogea @ansonwhho Following these findings, they both updated towards explosive growth being more plausible than they previously appreciated
@APotlogea @ansonwhho They thus also underestimated how much the world could be underinvesting in AI. Forget $500B investments in Stargate, the model suggests that optimal AI investment could be ~$25T, allowing society to soon capture the enormous returns from automating global labor (>$50T/year)

@APotlogea @ansonwhho If the model is even close to correct, current AI investments are too conservative rather than being driven by a “bubble”, as is often proclaimed. That said, negative externalities also need to be accounted for to determine optimal investment levels, which the model does not do
@APotlogea @ansonwhho So why aren’t actual AI investments higher? It’s far from certain, but possible explanations include uncertainty about automation feasibility, regulatory concerns, taxation fears, normalcy bias or conformity, or just crucial missing considerations in the model
@APotlogea @ansonwhho Overall, this work updated both of them away from extreme skepticism, as well as away from blind bullishness in >30% growth. Dramatic growth accelerations might be harder to avoid than they expected, but the model definitely doesn’t capture all the complexities of the real world
@APotlogea @ansonwhho You can read the full post here: epoch.ai/gradient-updat…
• • •
Missing some Tweet in this thread? You can try to
force a refresh