
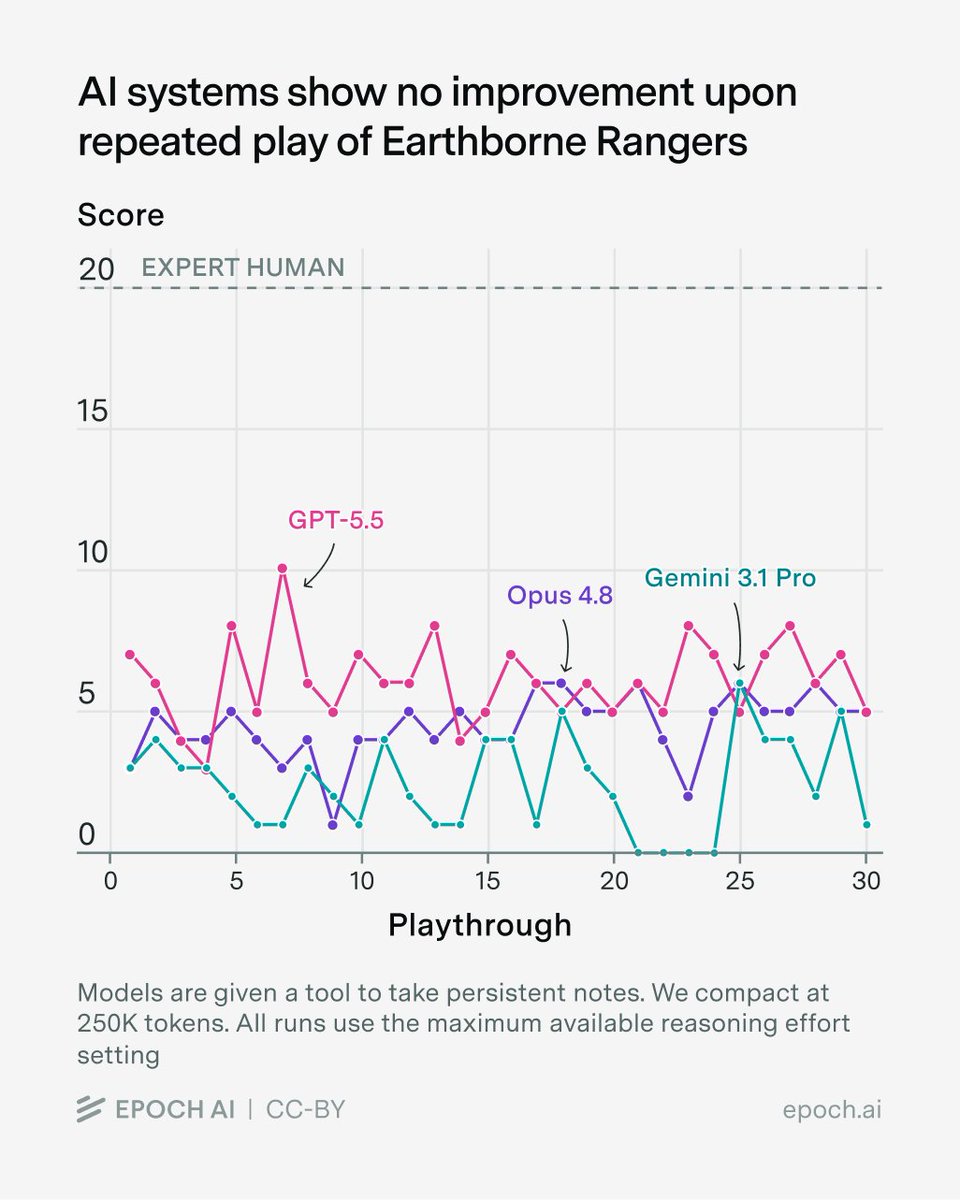
 If AI can learn on the fly, it becomes much more general-purpose. This has economic implications (learning on the job) as well as safety consequences (developing dangerous capabilities post-release). We study the ability to learn an unfamiliar game as a proxy for this dynamic.
If AI can learn on the fly, it becomes much more general-purpose. This has economic implications (learning on the job) as well as safety consequences (developing dangerous capabilities post-release). We study the ability to learn an unfamiliar game as a proxy for this dynamic.

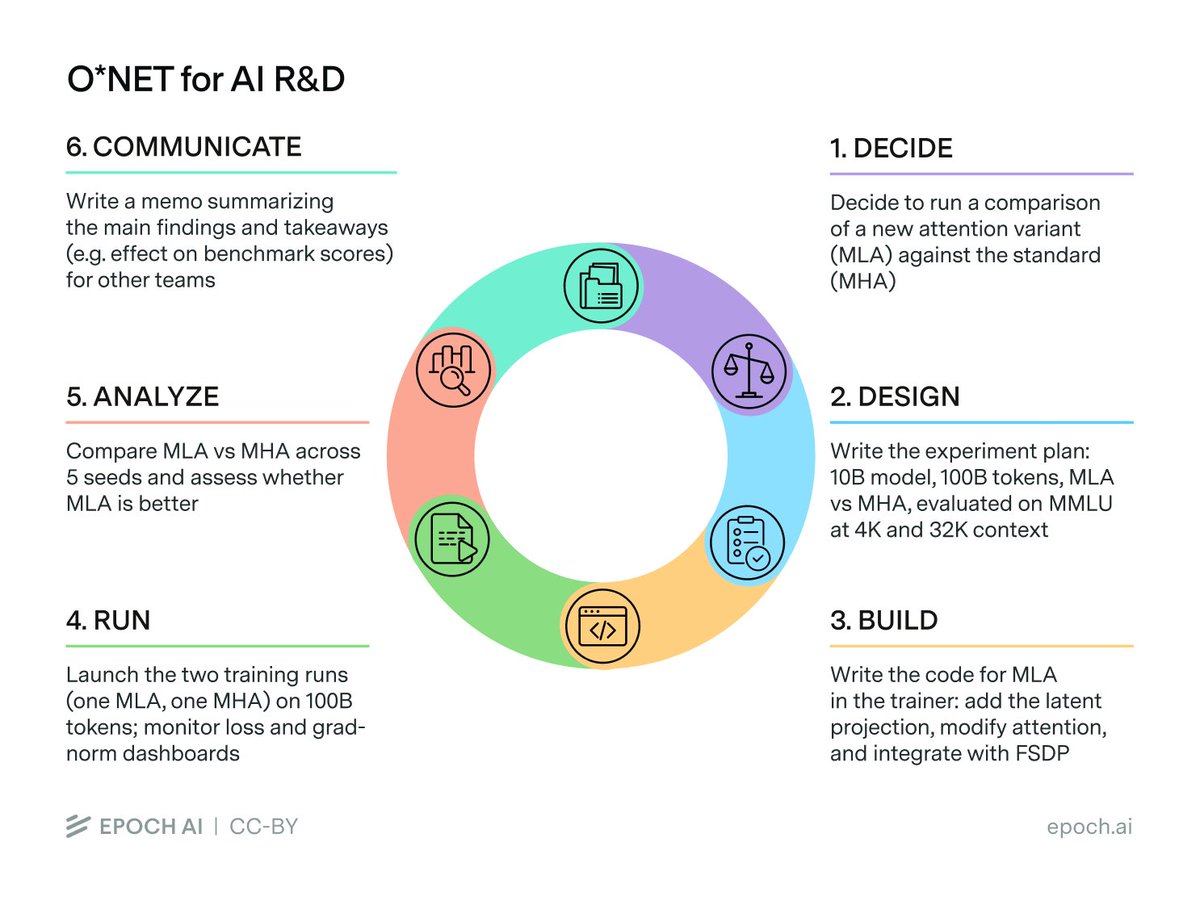 Economists often study labor markets using the O*NET database, which breaks ~1000 occupations into tasks. But these tasks are too coarse-grained to track automation in AI R&D specifically, even in occupations closest to “AI researcher”.
Economists often study labor markets using the O*NET database, which breaks ~1000 occupations into tasks. But these tasks are too coarse-grained to track automation in AI R&D specifically, even in occupations closest to “AI researcher”. 
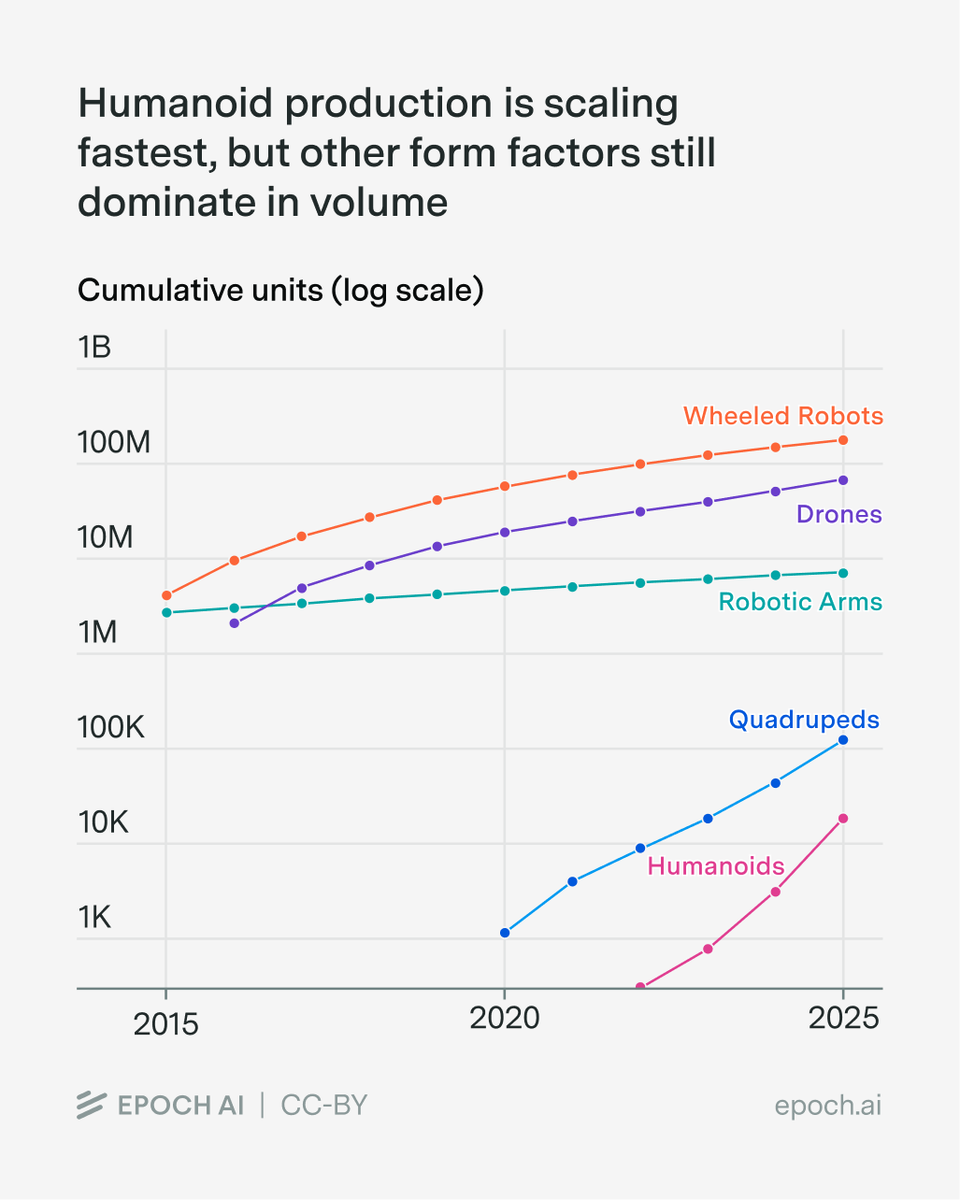 We first look at current production trends. Humanoids are growing fastest (~16K units in 2025, doubling every ~6 months) but from a small base.
We first look at current production trends. Humanoids are growing fastest (~16K units in 2025, doubling every ~6 months) but from a small base.
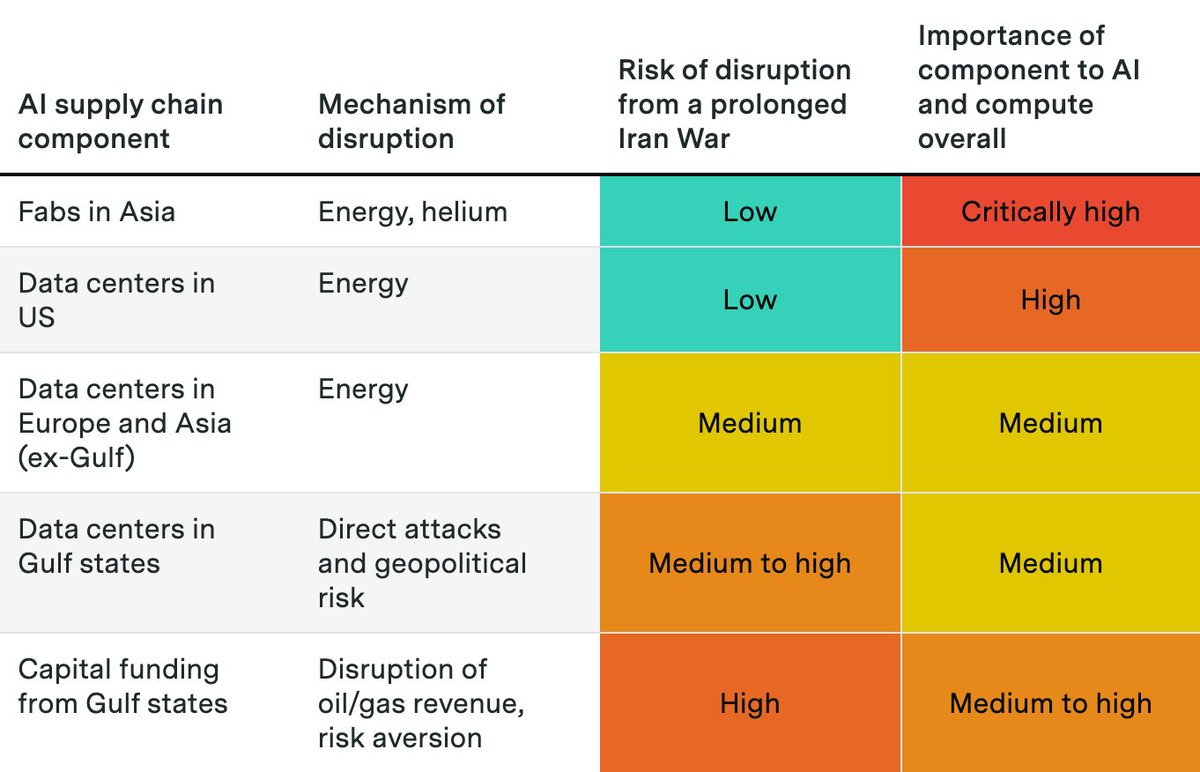 Fabrication of AI chips and memory is concentrated in Taiwan and South Korea. These fabs rely on energy from natural gas as well as helium, both disrupted by the Hormuz closure.
Fabrication of AI chips and memory is concentrated in Taiwan and South Korea. These fabs rely on energy from natural gas as well as helium, both disrupted by the Hormuz closure.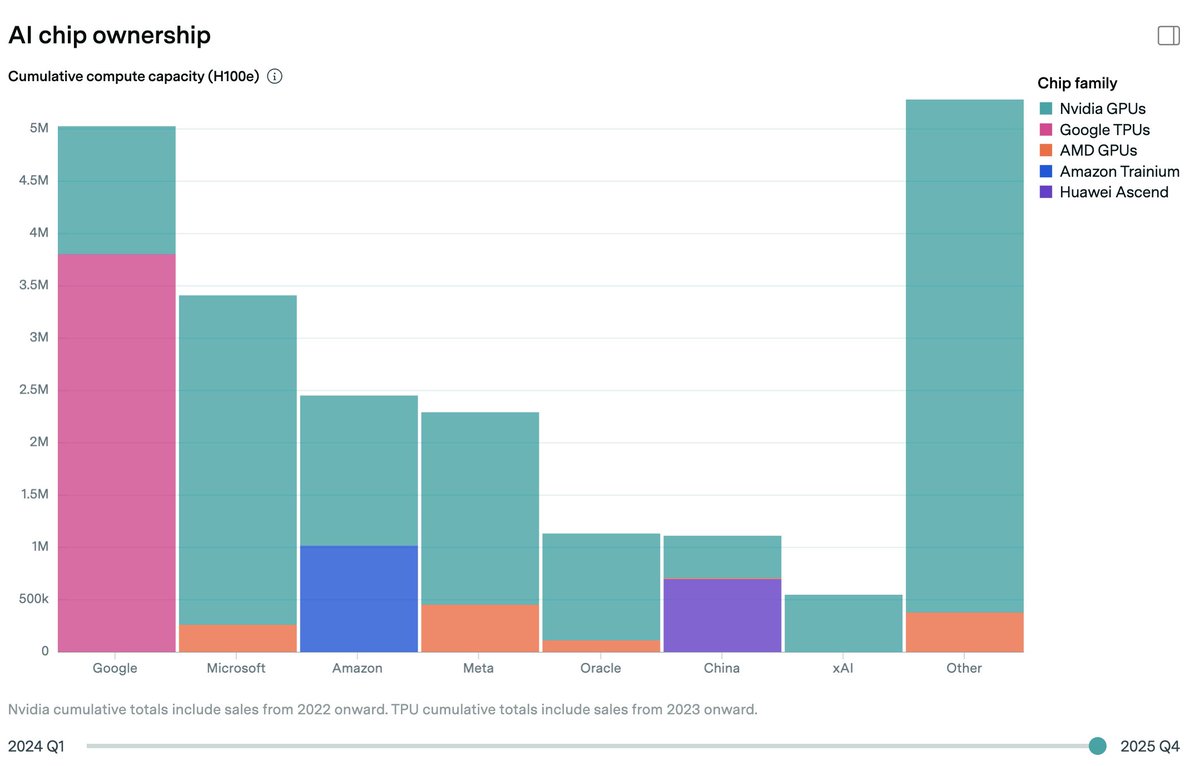 To estimate global compute ownership, we build on our previous estimates of overall AI chip sales. We then use earnings commentary from chipmakers and hyperscalers, as well as media reports and industry researcher estimates, to allocate chips across owners.
To estimate global compute ownership, we build on our previous estimates of overall AI chip sales. We then use earnings commentary from chipmakers and hyperscalers, as well as media reports and industry researcher estimates, to allocate chips across owners. 
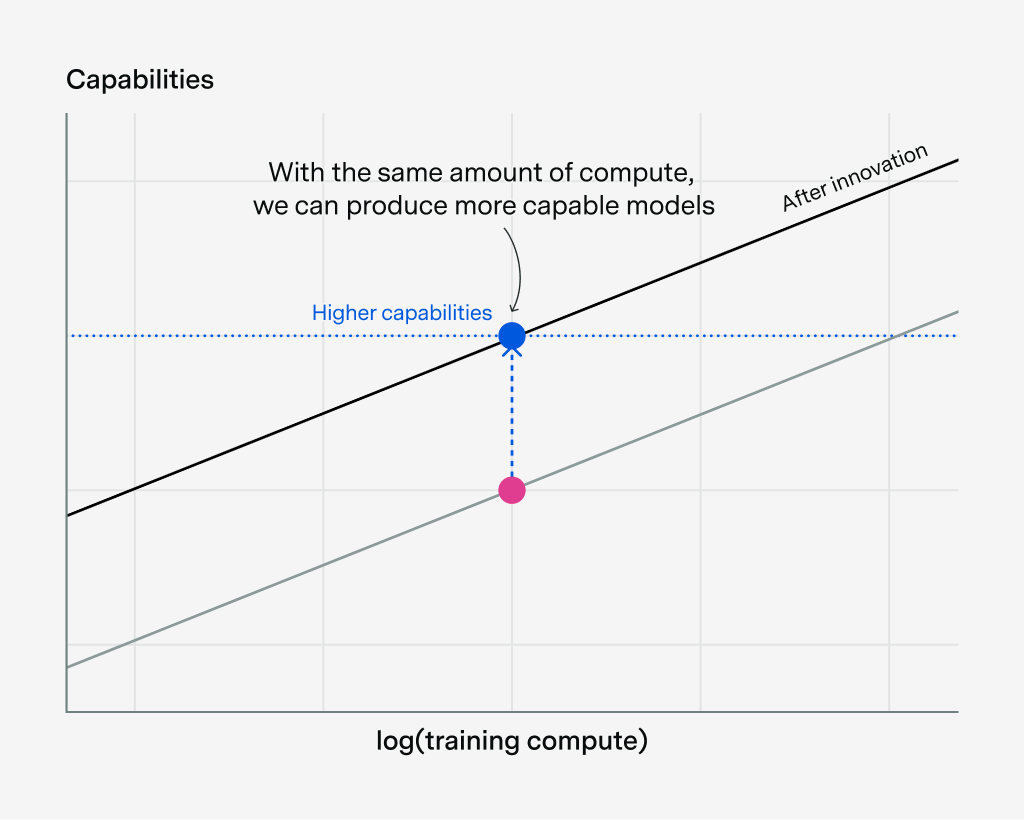 There are many ways to improve algorithms and data. For example, you could change model architectures, build better RL environments, and improve training recipes.
There are many ways to improve algorithms and data. For example, you could change model architectures, build better RL environments, and improve training recipes.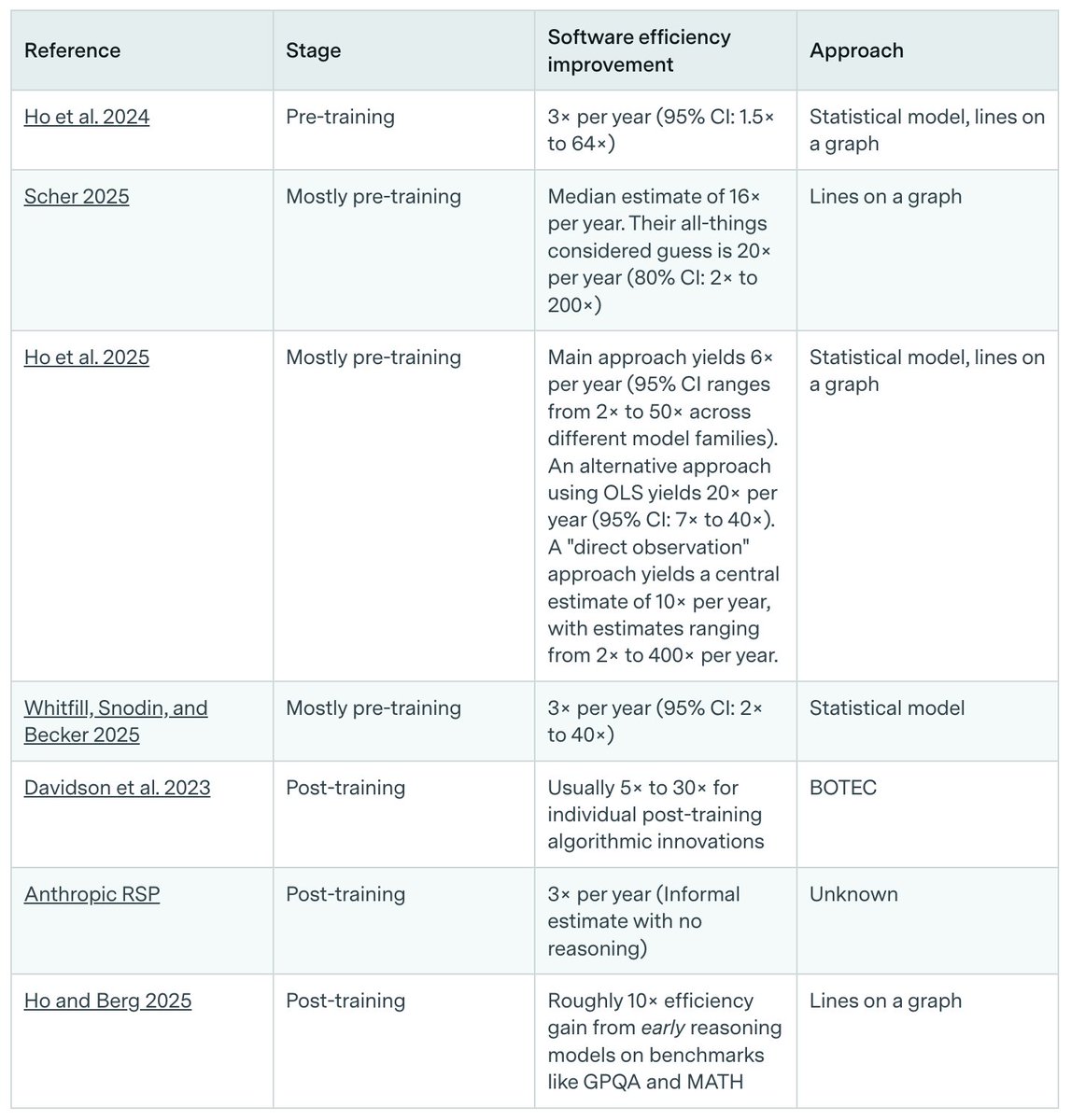 Almost all existing estimates suggest very fast progress, on the order of several times per year, though the uncertainty intervals are really wide.
Almost all existing estimates suggest very fast progress, on the order of several times per year, though the uncertainty intervals are really wide.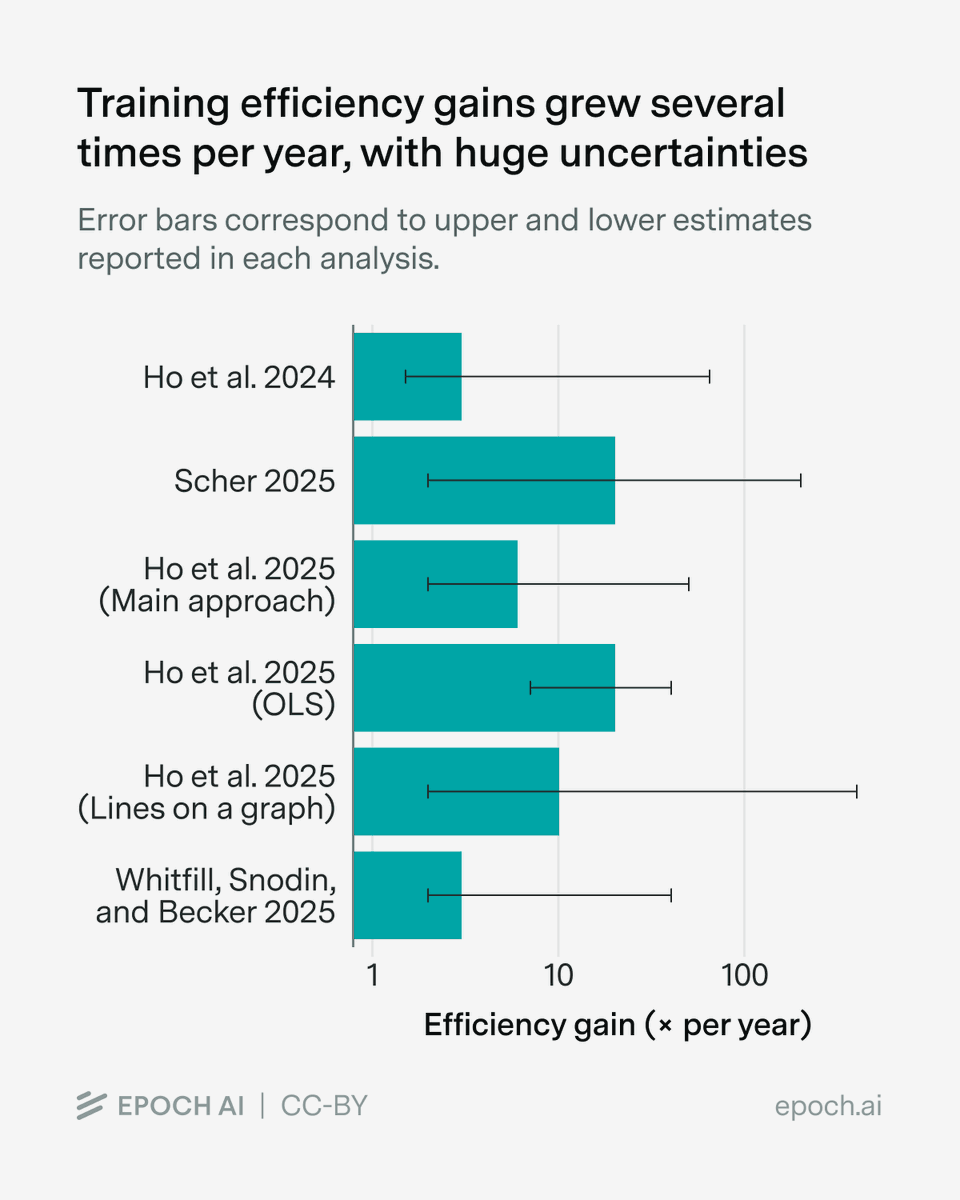
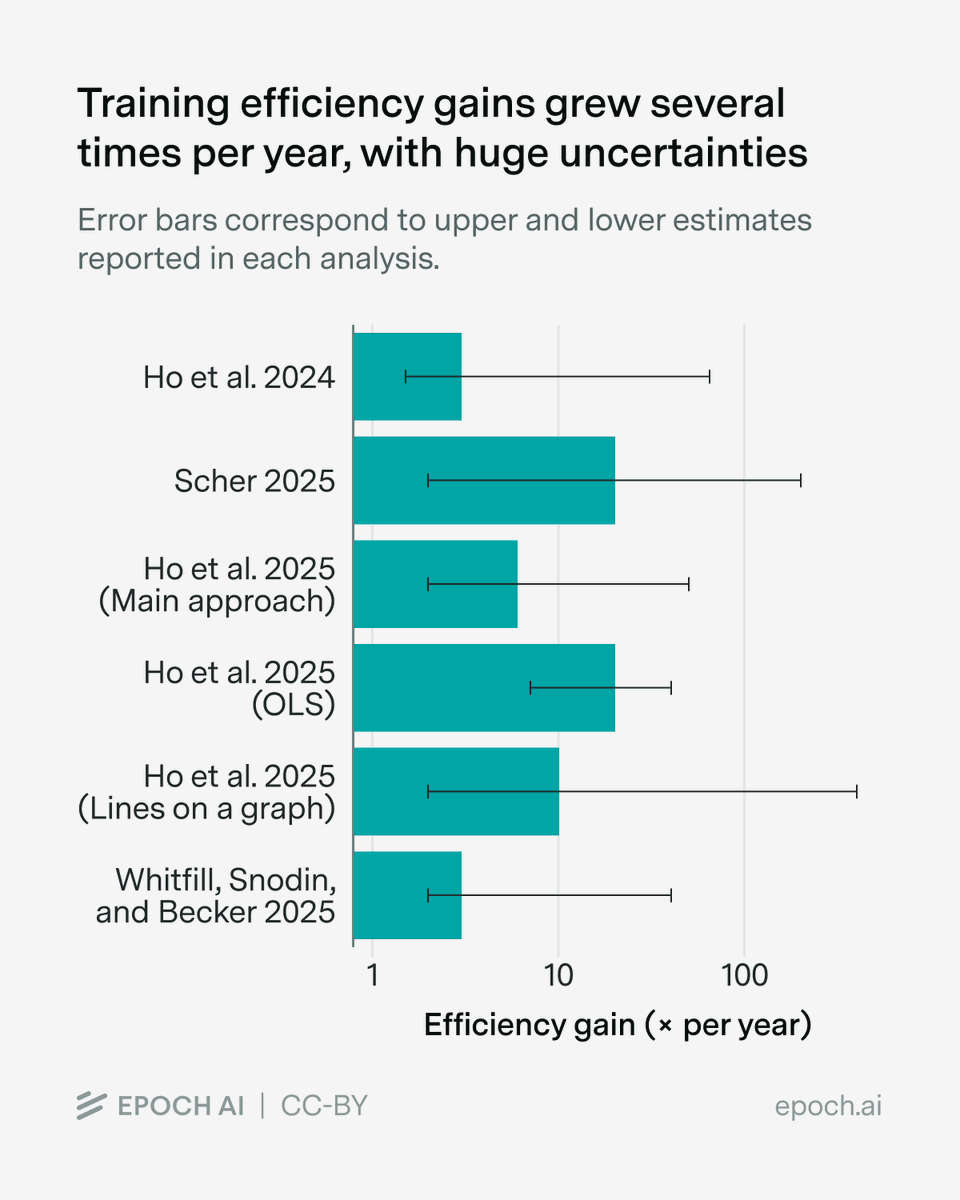 One explanation is that these improvements came not from better algorithms, but better data.
One explanation is that these improvements came not from better algorithms, but better data.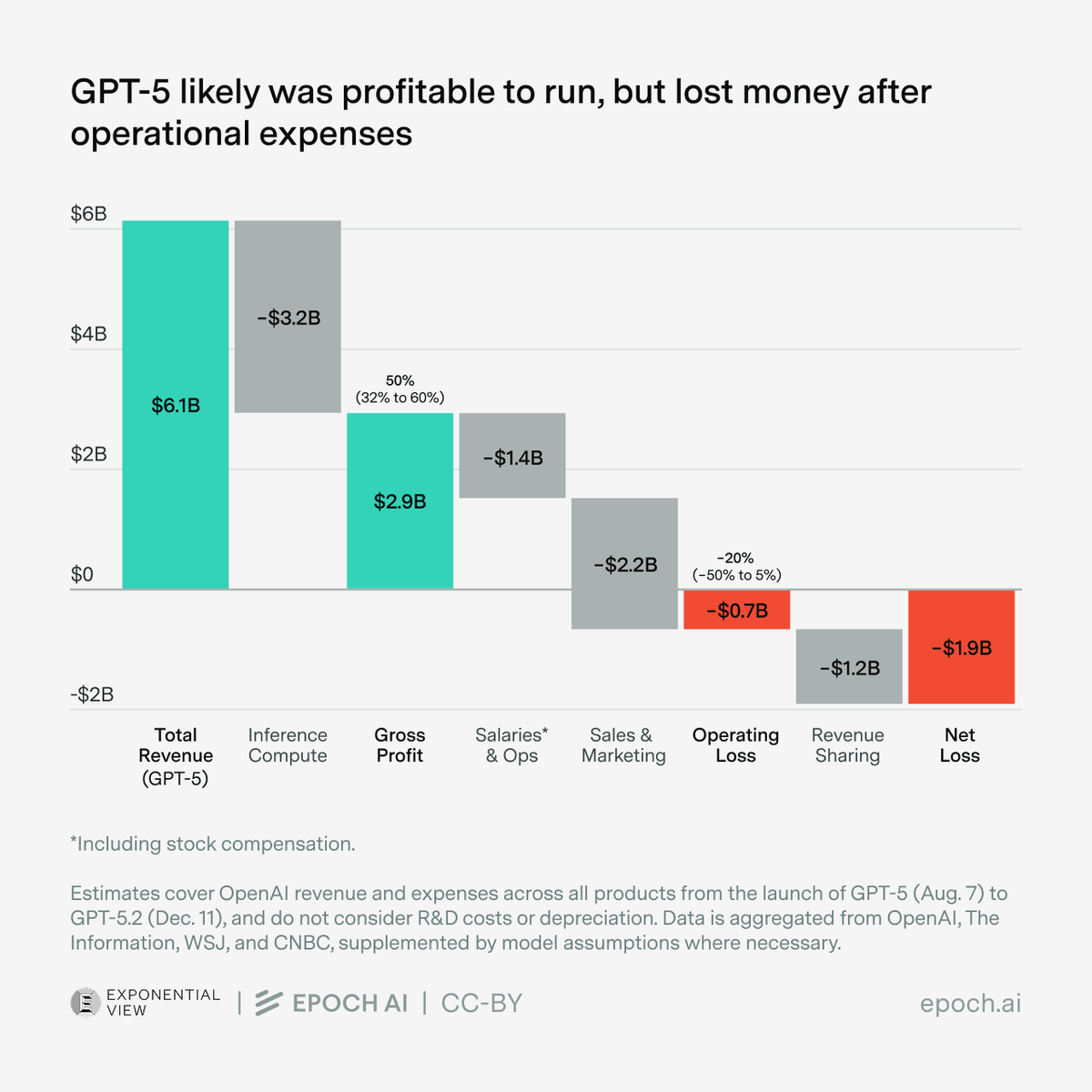 Even the gross profits from running models weren’t enough to recoup R&D costs.
Even the gross profits from running models weren’t enough to recoup R&D costs.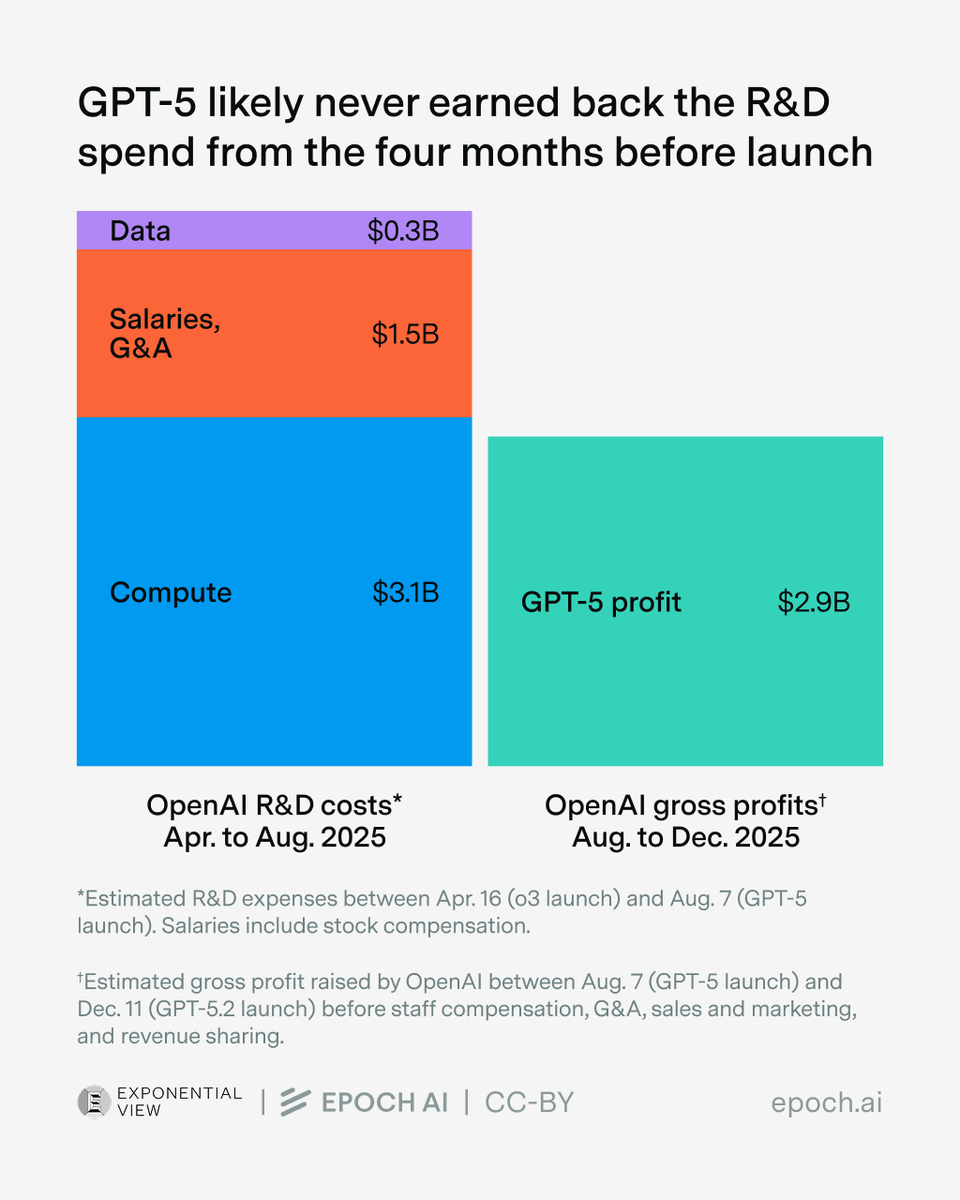
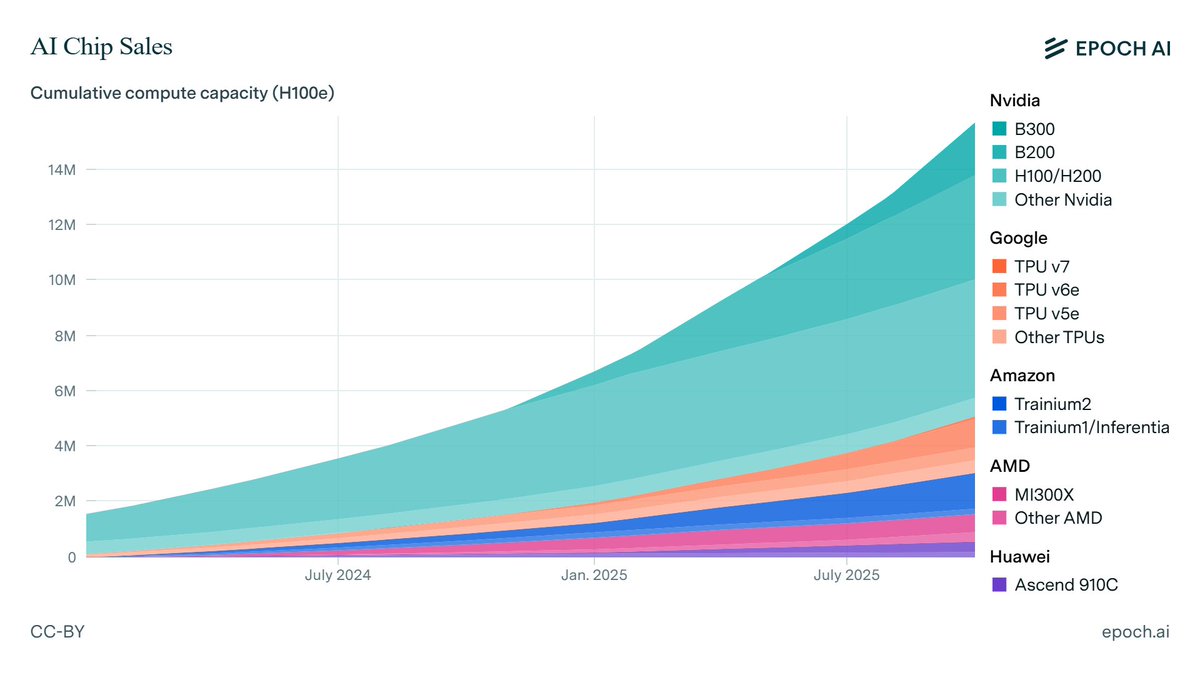 Nvidia’s B300 GPU now accounts for the majority of its revenue from AI chips, while H100s make up under 10%.
Nvidia’s B300 GPU now accounts for the majority of its revenue from AI chips, while H100s make up under 10%.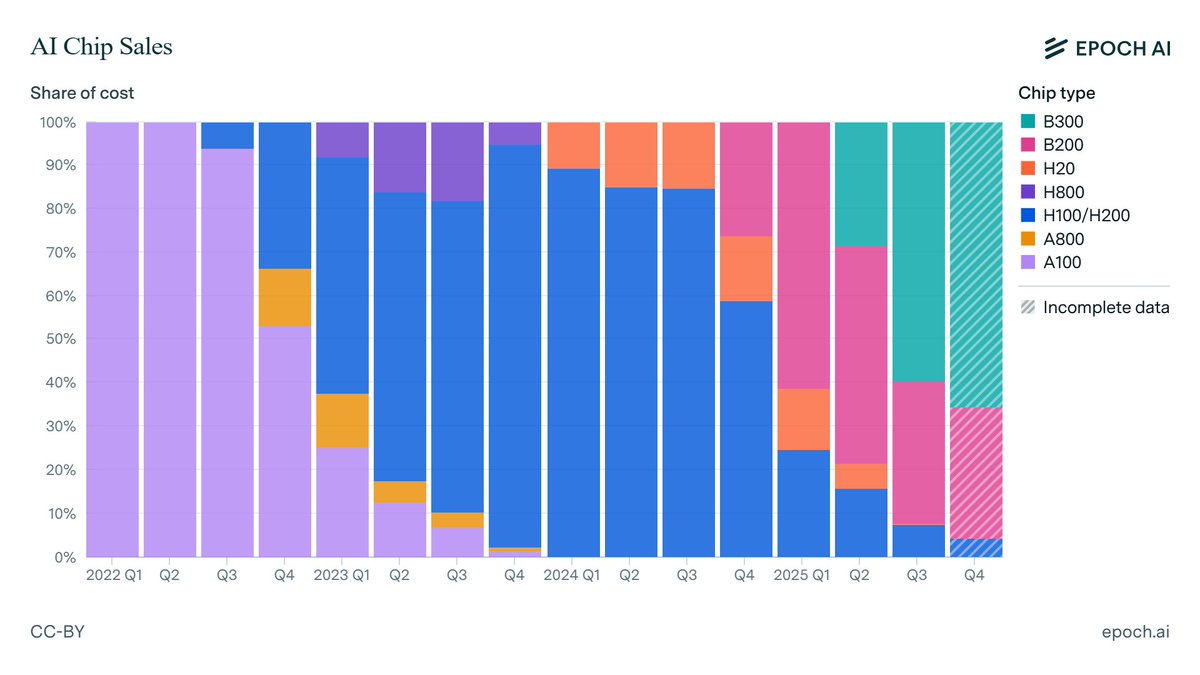
 GPT-5.2 ranks first or second on most of the benchmarks we run ourselves, including a top score on FrontierMath Tiers 1–3 and our new chess puzzles benchmark. The exception is SimpleQA Verified, where it scores notably worse than even previous GPT-5 series models.
GPT-5.2 ranks first or second on most of the benchmarks we run ourselves, including a top score on FrontierMath Tiers 1–3 and our new chess puzzles benchmark. The exception is SimpleQA Verified, where it scores notably worse than even previous GPT-5 series models. 
 AI data centers will be some of the biggest infrastructure projects in history
AI data centers will be some of the biggest infrastructure projects in history Three important takeaways:
Three important takeaways: Several data centers will soon demand 1 GW of power, starting early next year:
Several data centers will soon demand 1 GW of power, starting early next year:
 Note that this is the publicly available version of Deep Think, not the version that achieved a gold medal-equivalent score on the IMO. Google has described the publicly available Deep Think model as a “variation” of the IMO gold model.
Note that this is the publicly available version of Deep Think, not the version that achieved a gold medal-equivalent score on the IMO. Google has described the publicly available Deep Think model as a “variation” of the IMO gold model.

 Revenue:
Revenue:
 The invention of reasoning models made it possible to greatly improve performance by scaling up post-training compute. This improvement is so great that GPT-5 outperforms GPT-4.5 despite having used less training compute overall.
The invention of reasoning models made it possible to greatly improve performance by scaling up post-training compute. This improvement is so great that GPT-5 outperforms GPT-4.5 despite having used less training compute overall.
 We forecast that by 2030:
We forecast that by 2030:



 Investors are incredibly uncertain about the returns to further scaling, and overestimating the returns could cost them >$100B. So rather than going all-in today, they invest more gradually, observing the returns from incremental scaling, before reevaluating further investment.
Investors are incredibly uncertain about the returns to further scaling, and overestimating the returns could cost them >$100B. So rather than going all-in today, they invest more gradually, observing the returns from incremental scaling, before reevaluating further investment.