We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers.
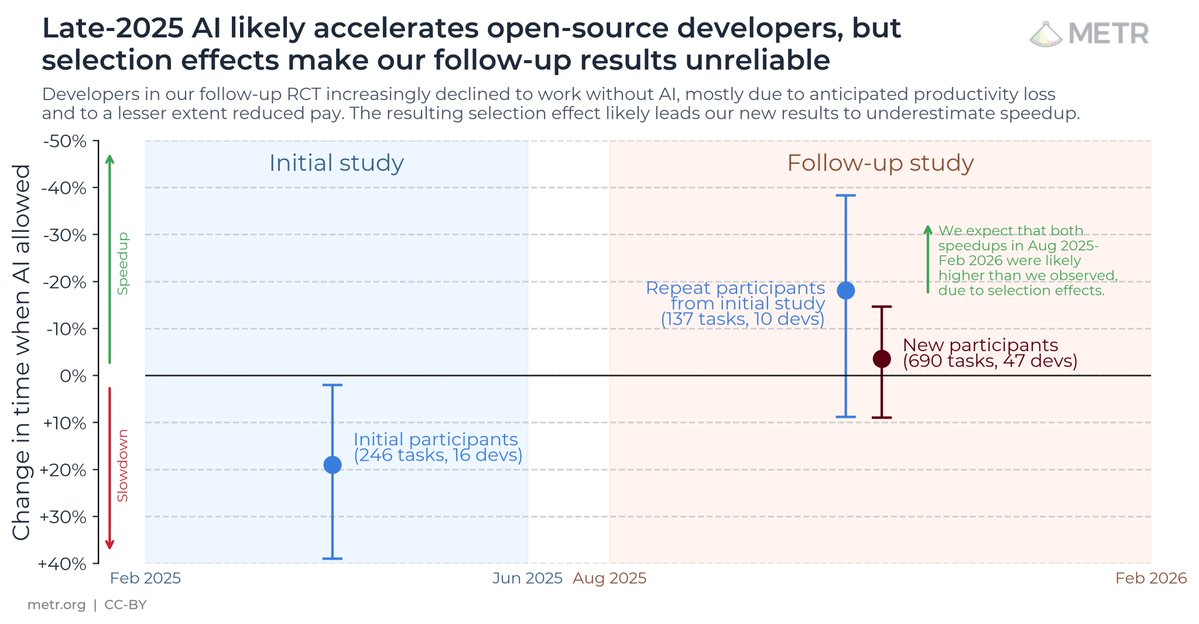
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.

We recruited 16 experienced open-source developers to work on 246 real tasks in their own repositories (avg 22k+ stars, 1M+ lines of code).
We randomly assigned each task to either allow AI (typically Cursor Pro w/ Claude 3.5/3.7) or disallow AI help.
We randomly assigned each task to either allow AI (typically Cursor Pro w/ Claude 3.5/3.7) or disallow AI help.

At the beginning of the study, developers forecasted that they would get sped up by 24%. After actually doing the work, they estimated that they had been sped up by 20%. But it turned out that they were actually slowed down by 19%.

We were surprised by this, given a) impressive AI benchmark scores, b) widespread adoption of AI tooling for software development, and c) our own recent research measuring trends in the length of tasks that agents are able to complete.
When AI is allowed, developers spend less time actively coding and searching for information, and instead spend time prompting AI, waiting on/reviewing AI outputs, and idle. We find no single reason for the slowdown—it’s driven by a combination of factors.

To better understand these factors, we investigate 20 properties of our setting, finding 5 likely contributors, and 8 mixed/unclear factors.
We also analyze to make sure the result isn’t a fluke, and find that slowdown persists across different outcome measures, estimator methodologies, and many other subsets/analyses of our data.
We also analyze to make sure the result isn’t a fluke, and find that slowdown persists across different outcome measures, estimator methodologies, and many other subsets/analyses of our data.



Why did we run this study?
AI agent benchmarks have limitations—they’re self-contained, use algorithmic scoring, and lack live human interaction. This can make it difficult to directly infer real-world impact.
If we want an early warning system for whether AI R&D is being accelerated by AI itself, or even automated, it would be useful to be able to directly measure this in real-world engineer trials, rather than relying on proxies like benchmarks or even noisier information like anecdotes.
AI agent benchmarks have limitations—they’re self-contained, use algorithmic scoring, and lack live human interaction. This can make it difficult to directly infer real-world impact.
If we want an early warning system for whether AI R&D is being accelerated by AI itself, or even automated, it would be useful to be able to directly measure this in real-world engineer trials, rather than relying on proxies like benchmarks or even noisier information like anecdotes.
So how do we reconcile our results with other sources of data on AI capabilities, like impressive benchmark results, and anecdotes/widespread adoption of AI tools?
Our RCT may underestimate capabilities for various reasons, and benchmarks and anecdotes may overestimate capabilities (likely some combination)—we discuss some possibilities in our accompanying blog post.
What do we take away?
1. It seems likely that for some important settings, recent AI tooling has not increased productivity (and may in fact decrease it).
2. Self-reports of speedup are unreliable—to understand AI’s impact on productivity, we need experiments in the wild.
1. It seems likely that for some important settings, recent AI tooling has not increased productivity (and may in fact decrease it).
2. Self-reports of speedup are unreliable—to understand AI’s impact on productivity, we need experiments in the wild.
Another implication:
It is sometimes proposed that we should monitor AI R&D acceleration inside of frontier AI labs via simple employee surveys. We’re now more pessimistic about these, given how large of a gap we observe between developer-estimated and observed speed-up.
It is sometimes proposed that we should monitor AI R&D acceleration inside of frontier AI labs via simple employee surveys. We’re now more pessimistic about these, given how large of a gap we observe between developer-estimated and observed speed-up.
What we're NOT saying:
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).
1. Our setting represents all (or potentially even most) software engineering.
2. Future models won't be better (or current models can’t be used more effectively).

We’re exploring running experiments like this in other settings—if you’re an open-source developer or company interested in understanding the impact of AI on your work, reach out to us here: forms.gle/pBsSo54VpmuQC4…
Paper: metr.org/Early_2025_AI_…
Blog: metr.org/blog/2025-07-1…
Paper: metr.org/Early_2025_AI_…
Blog: metr.org/blog/2025-07-1…
• • •
Missing some Tweet in this thread? You can try to
force a refresh