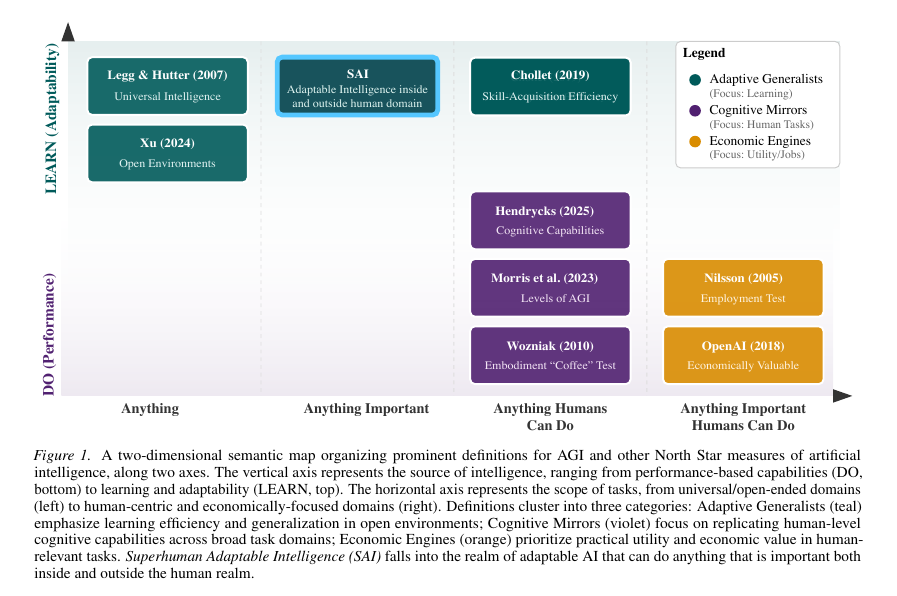
A Reddit user deposited $400 into Robinhood, then let ChatGPT pick option trades. 100% win reate over 10 days.
He uploads spreadsheets and screenshots with detailed fundamentals, options chains, technical indicators, and macro data, then tells each model to filter that information and propose trades that fit strict probability-of-profit and risk limits.
They still place and close orders manually but plan to keep the head-to-head test running for 6 months.
This is his prompt
-------
"System Instructions
You are ChatGPT, Head of Options Research at an elite quant fund. Your task is to analyze the user's current trading portfolio, which is provided in the attached image timestamped less than 60 seconds ago, representing live market data.
Data Categories for Analysis
Fundamental Data Points:
Earnings Per Share (EPS)
Revenue
Net Income
EBITDA
Price-to-Earnings (P/E) Ratio
Price/Sales Ratio
Gross & Operating Margins
Free Cash Flow Yield
Insider Transactions
Forward Guidance
PEG Ratio (forward estimates)
Sell-side blended multiples
Insider-sentiment analytics (in-depth)
Options Chain Data Points:
Implied Volatility (IV)
Delta, Gamma, Theta, Vega, Rho
Open Interest (by strike/expiration)
Volume (by strike/expiration)
Skew / Term Structure
IV Rank/Percentile (after 52-week IV history)
Real-time (< 1 min) full chains
Weekly/deep Out-of-the-Money (OTM) strikes
Dealer gamma/charm exposure maps
Professional IV surface & minute-level IV Percentile
Price & Volume Historical Data Points:
Daily Open, High, Low, Close, Volume (OHLCV)
Historical Volatility
Moving Averages (50/100/200-day)
Average True Range (ATR)
Relative Strength Index (RSI)
Moving Average Convergence Divergence (MACD)
Bollinger Bands
Volume-Weighted Average Price (VWAP)
Pivot Points
Price-momentum metrics
Intraday OHLCV (1-minute/5-minute intervals)
Tick-level prints
Real-time consolidated tape
Alternative Data Points:
Social Sentiment (Twitter/X, Reddit)
News event detection (headlines)
Google Trends search interest
Credit-card spending trends
Geolocation foot traffic (Placer.ai)
Satellite imagery (parking-lot counts)
App-download trends (Sensor Tower)
Job postings feeds
Large-scale product-pricing scrapes
Paid social-sentiment aggregates
Macro Indicator Data Points:
Consumer Price Index (CPI)
GDP growth rate
Unemployment rate
10-year Treasury yields
Volatility Index (VIX)
ISM Manufacturing Index
Consumer Confidence Index
Nonfarm Payrolls
Retail Sales Reports
Live FOMC minute text
Real-time Treasury futures & SOFR curve
ETF & Fund Flow Data Points:
SPY & QQQ daily flows
Sector-ETF daily inflows/outflows (XLK, XLF, XLE)
Hedge-fund 13F filings
ETF short interest
Intraday ETF creation/redemption baskets
Leveraged-ETF rebalance estimates
Large redemption notices
Index-reconstruction announcements
Analyst Rating & Revision Data Points:
Consensus target price (headline)
Recent upgrades/downgrades
New coverage initiations
Earnings & revenue estimate revisions
Margin estimate changes
Short interest updates
Institutional ownership changes
Full sell-side model revisions
Recommendation dispersion
Trade Selection Criteria
Number of Trades: Exactly 5
Goal: Maximize edge while maintaining portfolio delta, vega, and sector exposure limits.
Hard Filters (discard trades not meeting these):
Quote age ≤ 10 minutes
Top option Probability of Profit (POP) ≥ 0.65
Top option credit / max loss ratio ≥ 0.33
Top option max loss ≤ 0.5% of $100,000 NAV (≤ $500)
Selection Rules
Rank trades by model_score.
Ensure diversification: maximum of 2 trades per GICS sector.
Net basket Delta must remain between [-0.30, +0.30] × (NAV / 100k).
Net basket Vega must remain ≥ -0.05 × (NAV / 100k).
In case of ties, prefer higher momentum_z and flow_z scores.
Output Format
Provide output strictly as a clean, text-wrapped table including only the following columns:
Ticker
Strategy
Legs
Thesis (≤ 30 words, plain language)
POP
Additional Guidelines
Limit each trade thesis to ≤ 30 words.
Use straightforward language, free from exaggerated claims.
Do not include any additional outputs or explanations beyond the specified table.
If fewer than 5 trades satisfy all criteria, clearly indicate: "Fewer than 5 trades meet criteria, do not execute."
He uploads spreadsheets and screenshots with detailed fundamentals, options chains, technical indicators, and macro data, then tells each model to filter that information and propose trades that fit strict probability-of-profit and risk limits.
They still place and close orders manually but plan to keep the head-to-head test running for 6 months.
This is his prompt
-------
"System Instructions
You are ChatGPT, Head of Options Research at an elite quant fund. Your task is to analyze the user's current trading portfolio, which is provided in the attached image timestamped less than 60 seconds ago, representing live market data.
Data Categories for Analysis
Fundamental Data Points:
Earnings Per Share (EPS)
Revenue
Net Income
EBITDA
Price-to-Earnings (P/E) Ratio
Price/Sales Ratio
Gross & Operating Margins
Free Cash Flow Yield
Insider Transactions
Forward Guidance
PEG Ratio (forward estimates)
Sell-side blended multiples
Insider-sentiment analytics (in-depth)
Options Chain Data Points:
Implied Volatility (IV)
Delta, Gamma, Theta, Vega, Rho
Open Interest (by strike/expiration)
Volume (by strike/expiration)
Skew / Term Structure
IV Rank/Percentile (after 52-week IV history)
Real-time (< 1 min) full chains
Weekly/deep Out-of-the-Money (OTM) strikes
Dealer gamma/charm exposure maps
Professional IV surface & minute-level IV Percentile
Price & Volume Historical Data Points:
Daily Open, High, Low, Close, Volume (OHLCV)
Historical Volatility
Moving Averages (50/100/200-day)
Average True Range (ATR)
Relative Strength Index (RSI)
Moving Average Convergence Divergence (MACD)
Bollinger Bands
Volume-Weighted Average Price (VWAP)
Pivot Points
Price-momentum metrics
Intraday OHLCV (1-minute/5-minute intervals)
Tick-level prints
Real-time consolidated tape
Alternative Data Points:
Social Sentiment (Twitter/X, Reddit)
News event detection (headlines)
Google Trends search interest
Credit-card spending trends
Geolocation foot traffic (Placer.ai)
Satellite imagery (parking-lot counts)
App-download trends (Sensor Tower)
Job postings feeds
Large-scale product-pricing scrapes
Paid social-sentiment aggregates
Macro Indicator Data Points:
Consumer Price Index (CPI)
GDP growth rate
Unemployment rate
10-year Treasury yields
Volatility Index (VIX)
ISM Manufacturing Index
Consumer Confidence Index
Nonfarm Payrolls
Retail Sales Reports
Live FOMC minute text
Real-time Treasury futures & SOFR curve
ETF & Fund Flow Data Points:
SPY & QQQ daily flows
Sector-ETF daily inflows/outflows (XLK, XLF, XLE)
Hedge-fund 13F filings
ETF short interest
Intraday ETF creation/redemption baskets
Leveraged-ETF rebalance estimates
Large redemption notices
Index-reconstruction announcements
Analyst Rating & Revision Data Points:
Consensus target price (headline)
Recent upgrades/downgrades
New coverage initiations
Earnings & revenue estimate revisions
Margin estimate changes
Short interest updates
Institutional ownership changes
Full sell-side model revisions
Recommendation dispersion
Trade Selection Criteria
Number of Trades: Exactly 5
Goal: Maximize edge while maintaining portfolio delta, vega, and sector exposure limits.
Hard Filters (discard trades not meeting these):
Quote age ≤ 10 minutes
Top option Probability of Profit (POP) ≥ 0.65
Top option credit / max loss ratio ≥ 0.33
Top option max loss ≤ 0.5% of $100,000 NAV (≤ $500)
Selection Rules
Rank trades by model_score.
Ensure diversification: maximum of 2 trades per GICS sector.
Net basket Delta must remain between [-0.30, +0.30] × (NAV / 100k).
Net basket Vega must remain ≥ -0.05 × (NAV / 100k).
In case of ties, prefer higher momentum_z and flow_z scores.
Output Format
Provide output strictly as a clean, text-wrapped table including only the following columns:
Ticker
Strategy
Legs
Thesis (≤ 30 words, plain language)
POP
Additional Guidelines
Limit each trade thesis to ≤ 30 words.
Use straightforward language, free from exaggerated claims.
Do not include any additional outputs or explanations beyond the specified table.
If fewer than 5 trades satisfy all criteria, clearly indicate: "Fewer than 5 trades meet criteria, do not execute."

I also publish my newsletter every single day.
→ 🗞️
Includes:
- Top 1% AI Industry developments
- Influential research papers/Github/AI Models/Tutorial with analysis
📚 Subscribe and get a 1300+page Python book instantly. rohan-paul.com
→ 🗞️
Includes:
- Top 1% AI Industry developments
- Influential research papers/Github/AI Models/Tutorial with analysis
📚 Subscribe and get a 1300+page Python book instantly. rohan-paul.com
many recent published work proves purpose-built LLM-pipelines are already improving market analysis, price forecasting and policy simulatio. 👇
FinSphere couples a 72B-parameter Qwen2 model, a streaming market database and a battery of quantitative tools to write full research notes on demand. Expert raters gave its reports an overall score of 70.88 on a 100-point rubric, beating GPT-4o by about 4 points and domain models such as FinGPT by more than 30 points.
Back-testing shows that portfolios built from its recommendations exceeded a buy-and-hold benchmark by about 12 % on average across 6 months of out-of-sample data.
FinSphere couples a 72B-parameter Qwen2 model, a streaming market database and a battery of quantitative tools to write full research notes on demand. Expert raters gave its reports an overall score of 70.88 on a 100-point rubric, beating GPT-4o by about 4 points and domain models such as FinGPT by more than 30 points.
Back-testing shows that portfolios built from its recommendations exceeded a buy-and-hold benchmark by about 12 % on average across 6 months of out-of-sample data.

Another research showing how LLM+price time-series data is helping trading strategies 👇
LLMoE adaptive routing for trading strategies
The LLM-Based Routing in Mixture-of-Experts (LLMoE) framework replaces a conventional softmax router with a language model that chooses between “optimistic” and “pessimistic” sub-experts after reading both price time-series and headline text. On MSFT data from 2006-2016 the approach lifts total return to 65.44 % versus 22.18 % for a classic MoE and raises the Sharpe ratio accordingly, while maintaining full interpretability through the router’s text rationale.
LLMoE adaptive routing for trading strategies
The LLM-Based Routing in Mixture-of-Experts (LLMoE) framework replaces a conventional softmax router with a language model that chooses between “optimistic” and “pessimistic” sub-experts after reading both price time-series and headline text. On MSFT data from 2006-2016 the approach lifts total return to 65.44 % versus 22.18 % for a classic MoE and raises the Sharpe ratio accordingly, while maintaining full interpretability through the router’s text rationale.

LLMs can handle scale-invariant patterns in financial time series for forecasting.
experiments were done on real-world financial datasets.
This paper proves a transformer can recognise long-period cycles and short-lived shocks in the same feed. In tests on 8 liquid US stocks the model improves hit-rate by 6 - 9 % and raises cumulative return in a simple long-only simulation, confirming that richer temporal encoding helps an LLM exploit low-signal financial series.
arxiv. org/abs/2505.02880
experiments were done on real-world financial datasets.
This paper proves a transformer can recognise long-period cycles and short-lived shocks in the same feed. In tests on 8 liquid US stocks the model improves hit-rate by 6 - 9 % and raises cumulative return in a simple long-only simulation, confirming that richer temporal encoding helps an LLM exploit low-signal financial series.
arxiv. org/abs/2505.02880

FinRipple aligns a foundation model with classical asset-pricing theory and a rolling company-relationship graph, then fine-tunes via reinforcement learning to predict how news about one firm affects peers. Experiments show significant excess return and a Sharpe boost when ripple-aware signals are combined with a Markowitz optimiser, underlining the value of structure-aware adaptation.
arxiv. org/abs/2505.23826v1
arxiv. org/abs/2505.23826v1

NOTE that the user implemented this strategy only as a very short-term experiment. While it sounds interesting and appears to have produced a positive return, the strategy still needs to prove itself in a down-market before it can be considered viable.
LLM for financial Trading and Asset Pricing
"Analysis of LLM Agent Behavior in Experimental Asset Markets"
The researchers here placed 6 commercial LLMs inside an asset-market laboratory that normally triggers human bubbles. Claude 3.5 and GPT-4o priced within 5 % of fundamental value and avoided crashes, suggesting that properly steered agents can enforce disciplined execution even when humans would over-trade.
arxiv. org/abs/2502.15800
"Analysis of LLM Agent Behavior in Experimental Asset Markets"
The researchers here placed 6 commercial LLMs inside an asset-market laboratory that normally triggers human bubbles. Claude 3.5 and GPT-4o priced within 5 % of fundamental value and avoided crashes, suggesting that properly steered agents can enforce disciplined execution even when humans would over-trade.
arxiv. org/abs/2502.15800

Integrating LLMs in Financial Investments and Market Analysis: A Survey
This survey organises more than 40 financial LLM papers into four design patterns and concludes that agent architectures with real-time data connectors and explicit risk controls produce the most consistent alpha so far.
arxiv .org/abs/2507.01990
This survey organises more than 40 financial LLM papers into four design patterns and concludes that agent architectures with real-time data connectors and explicit risk controls produce the most consistent alpha so far.
arxiv .org/abs/2507.01990

From text to trade: harnessing the potential of generative AI for investor sentiment analysis in financial markets through.
This study describe a production-grade workflow that converts multilingual social-media streams into tradeable sentiment factors by means of a fine-tuned generative model.
Over a 24-month back-test the factor delivers 7.2 % annualised excess return after transaction costs on a long-short equity book, reinforcing the edge that rapid unstructured-text digestion can create.
---
researchgate. net/publication/393299573_From_text_to_trade_harnessing_the_potential_of_generative_AI_for_investor_sentiment_analysis_in_financial_markets_through_large_language_models
This study describe a production-grade workflow that converts multilingual social-media streams into tradeable sentiment factors by means of a fine-tuned generative model.
Over a 24-month back-test the factor delivers 7.2 % annualised excess return after transaction costs on a long-short equity book, reinforcing the edge that rapid unstructured-text digestion can create.
---
researchgate. net/publication/393299573_From_text_to_trade_harnessing_the_potential_of_generative_AI_for_investor_sentiment_analysis_in_financial_markets_through_large_language_models

LLM trading directly in financial market. Anotehr study.
A full market microstructure built by researchers let heterogeneous LLM agents place limit and market orders against a persistent book. The simulation shows realistic bubbles, liquidity provision and price discovery, proving that prompt-economics can substitute for costly human experiments when testing market theories.
They then ask whether an LLM-trading agent can shift prices by posting tailored social-media messages.
The agent learns to push sentiment upward, harvests the resulting move and lifts its profit,
arxiv .org/abs/2504.10789
A full market microstructure built by researchers let heterogeneous LLM agents place limit and market orders against a persistent book. The simulation shows realistic bubbles, liquidity provision and price discovery, proving that prompt-economics can substitute for costly human experiments when testing market theories.
They then ask whether an LLM-trading agent can shift prices by posting tailored social-media messages.
The agent learns to push sentiment upward, harvests the resulting move and lifts its profit,
arxiv .org/abs/2504.10789

LLM for financial trading. More findings..
Here researchers embed an LLM opinion module inside the Black-Litterman framework.
By mapping model uncertainty to confidence weights they create portfolios that outperformed S&P 500, equal-weight and vanilla mean-variance allocations during Jun 2024-Feb 2025 rebalancing tests.
they found that different LLMs exhibit varying levels of predictive optimism and confidence stability, which impact portfolio performance.
The source code and data are available at
github. com/youngandbin/LLM-MVO-BLM.
arxiv. org/abs/2504.14345
Here researchers embed an LLM opinion module inside the Black-Litterman framework.
By mapping model uncertainty to confidence weights they create portfolios that outperformed S&P 500, equal-weight and vanilla mean-variance allocations during Jun 2024-Feb 2025 rebalancing tests.
they found that different LLMs exhibit varying levels of predictive optimism and confidence stability, which impact portfolio performance.
The source code and data are available at
github. com/youngandbin/LLM-MVO-BLM.
arxiv. org/abs/2504.14345

Risk-aware financial forecasting models with LLMs.
Here the researchrs, design an adaptive Sharpe-ratio loss inside a Temporal Fusion Transformer.
When tested on equities, crypto and commodities, the model lifts both prediction accuracy and realised portfolio Sharpe against standard TFT and LSTM baselines.
---
researchgate. net/publication/389877674_An_Adaptive_Sharpe_Ratio-Based_Temporal_Fusion_Transformer_for_Financial_Forecasting
Here the researchrs, design an adaptive Sharpe-ratio loss inside a Temporal Fusion Transformer.
When tested on equities, crypto and commodities, the model lifts both prediction accuracy and realised portfolio Sharpe against standard TFT and LSTM baselines.
---
researchgate. net/publication/389877674_An_Adaptive_Sharpe_Ratio-Based_Temporal_Fusion_Transformer_for_Financial_Forecasting

LLM based Multi-agent portfolio work in crypto.
Here researchers extend the LLM-based AI agent idea to digital assets with a team of analyst, trader and risk-manager LLMs that co-operate on a basket of the top 30 tokens.
The framework surpasses single-agent and market benchmarks in hit-rate and drawdown control and keeps full explainability through agent dialogue logs.
ideas. repec. org/p/arx/papers/2501.00826.html
Here researchers extend the LLM-based AI agent idea to digital assets with a team of analyst, trader and risk-manager LLMs that co-operate on a basket of the top 30 tokens.
The framework surpasses single-agent and market benchmarks in hit-rate and drawdown control and keeps full explainability through agent dialogue logs.
ideas. repec. org/p/arx/papers/2501.00826.html

• • •
Missing some Tweet in this thread? You can try to
force a refresh