We’re releasing the Artificial Analysis AI Adoption Survey Report for H1 2025 based on >1,000 responses from developers, product managers and executives adopting AI
The Artificial Analysis AI Adoption Survey Report examines key trends in AI usage, analyzing adoption rates, primary use cases driving AI’s growth, and demand across chatbots, coding agents, LLM model families, providers, and chip companies.
A highlights version of the report is available for download on our website for a limited time.
We unpack 6 trends defining the adoption of AI for organizations in the first half of 2025:
1)⚡ AI has hit production: ~45% are using AI in production, while an additional 50% are prototyping or exploring uses with AI
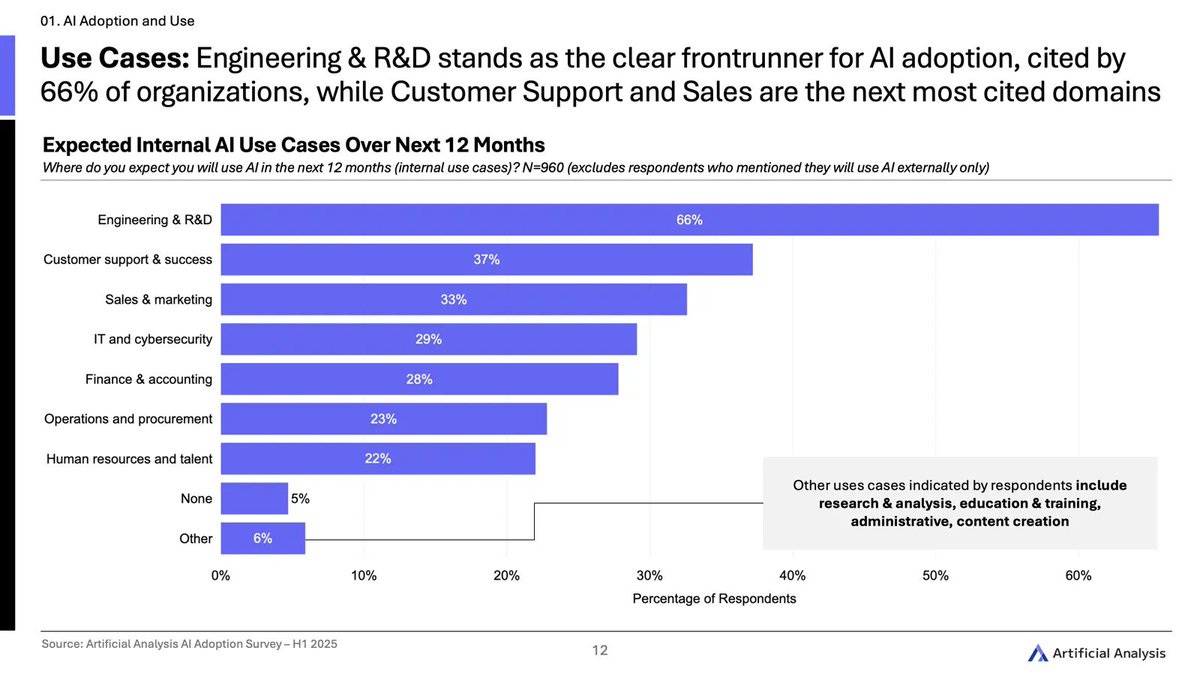
2)💡 Engineering and R&D is the clear frontrunner use case: 66% are considering AI for Engineering/R&D, well ahead of the next most popular use cases in Customer Support and Sales & Marketing
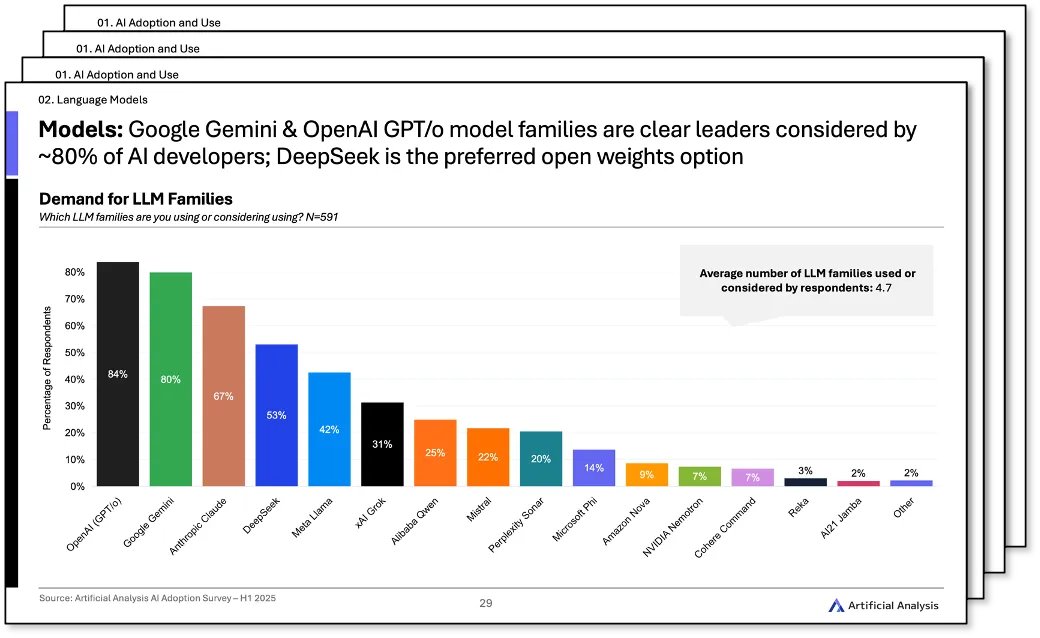
3) 📈 Google, xAI, DeepSeek gain share while Meta and Mistral lose share: ~80% are using/considering Google Gemini, 53% DeepSeek & 31% xAI Grok marking a substantial increase in demand since 2024
4) 🔄 Companies are increasingly diversifying their AI use: Average number of LLMs used/considered has increased from ~2.8 in 2024 to ~4.7 in 2025, as organizations mature their AI use cases
5) 🏗️ Organizations are taking different approaches to Build vs. Buy: 32% of respondents favor building; 27% buying and 25% a hybrid approach
6) 🇨🇳 Organizations are open to Chinese models, if hosted outside of China: 55% would be willing to use LLMs from China-based AI labs, if hosted outside of China
The survey was conducted between April and June 2025, collecting responses from 1,000+ individuals across 90+ countries.
Below we share excerpts covering select important takeaways:
The Artificial Analysis AI Adoption Survey Report examines key trends in AI usage, analyzing adoption rates, primary use cases driving AI’s growth, and demand across chatbots, coding agents, LLM model families, providers, and chip companies.
A highlights version of the report is available for download on our website for a limited time.
We unpack 6 trends defining the adoption of AI for organizations in the first half of 2025:
1)⚡ AI has hit production: ~45% are using AI in production, while an additional 50% are prototyping or exploring uses with AI
2)💡 Engineering and R&D is the clear frontrunner use case: 66% are considering AI for Engineering/R&D, well ahead of the next most popular use cases in Customer Support and Sales & Marketing
3) 📈 Google, xAI, DeepSeek gain share while Meta and Mistral lose share: ~80% are using/considering Google Gemini, 53% DeepSeek & 31% xAI Grok marking a substantial increase in demand since 2024
4) 🔄 Companies are increasingly diversifying their AI use: Average number of LLMs used/considered has increased from ~2.8 in 2024 to ~4.7 in 2025, as organizations mature their AI use cases
5) 🏗️ Organizations are taking different approaches to Build vs. Buy: 32% of respondents favor building; 27% buying and 25% a hybrid approach
6) 🇨🇳 Organizations are open to Chinese models, if hosted outside of China: 55% would be willing to use LLMs from China-based AI labs, if hosted outside of China
The survey was conducted between April and June 2025, collecting responses from 1,000+ individuals across 90+ countries.
Below we share excerpts covering select important takeaways:
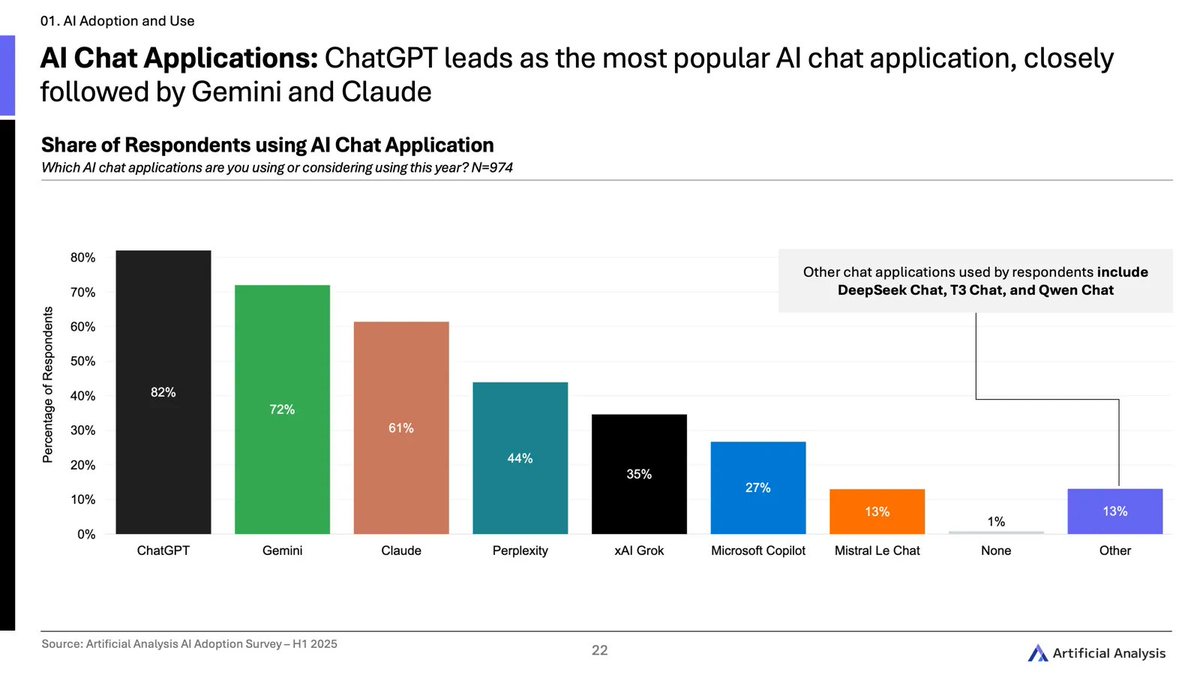
ChatGPT dominates AI chat adoption, followed by Gemini and Claude. Other notable players include Perplexity, xAI Grok and Microsoft Copilot
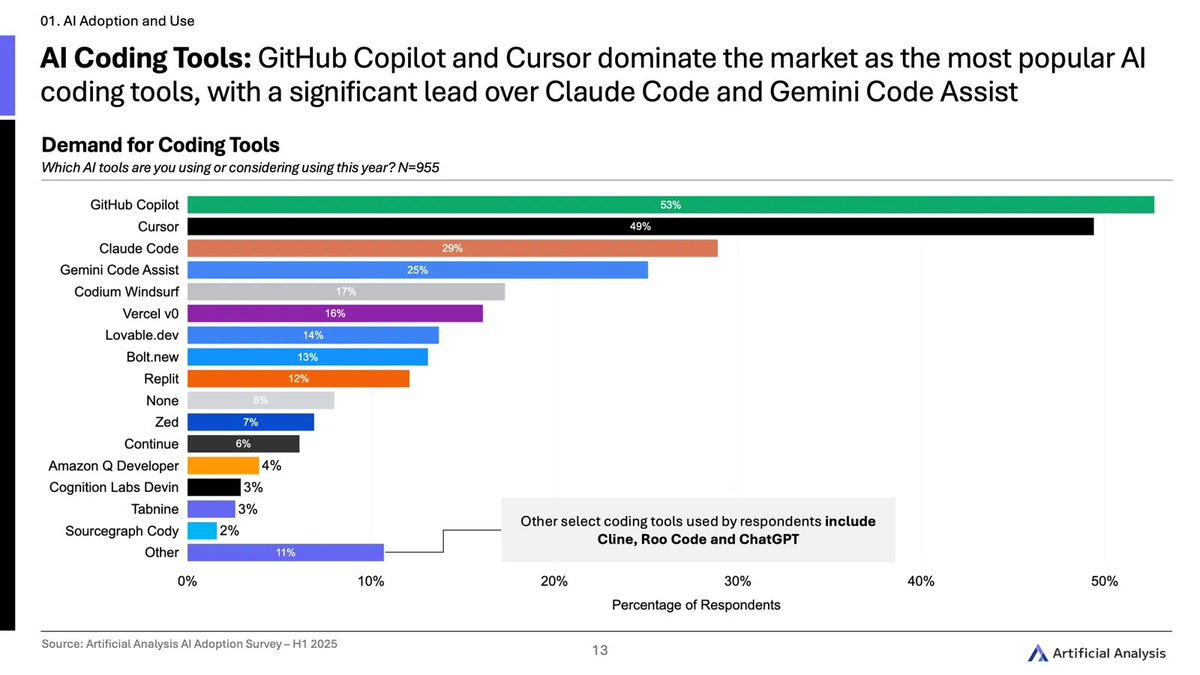
GitHub Copilot and Cursor dominate the market as the most popular AI coding tools, ahead of Claude Code and Gemini Code Assist (Note: the survey was conducted before the release of OpenAI Codex)
Most orgs will deploy AI in Engineering & R&D before Customer Support, Sales & Marketing, or IT & Cybersecurity; It’s also the top area for AI agent use
Developers consider an average of 4.7 LLM families with OpenAI GPT/o, Google Gemini and Anthropic Claude being the most popular, and DeepSeek as the top open-weights choice

The highlights version of the report is available for download on our website for a limited time.
artificialanalysis.ai
artificialanalysis.ai

• • •
Missing some Tweet in this thread? You can try to
force a refresh