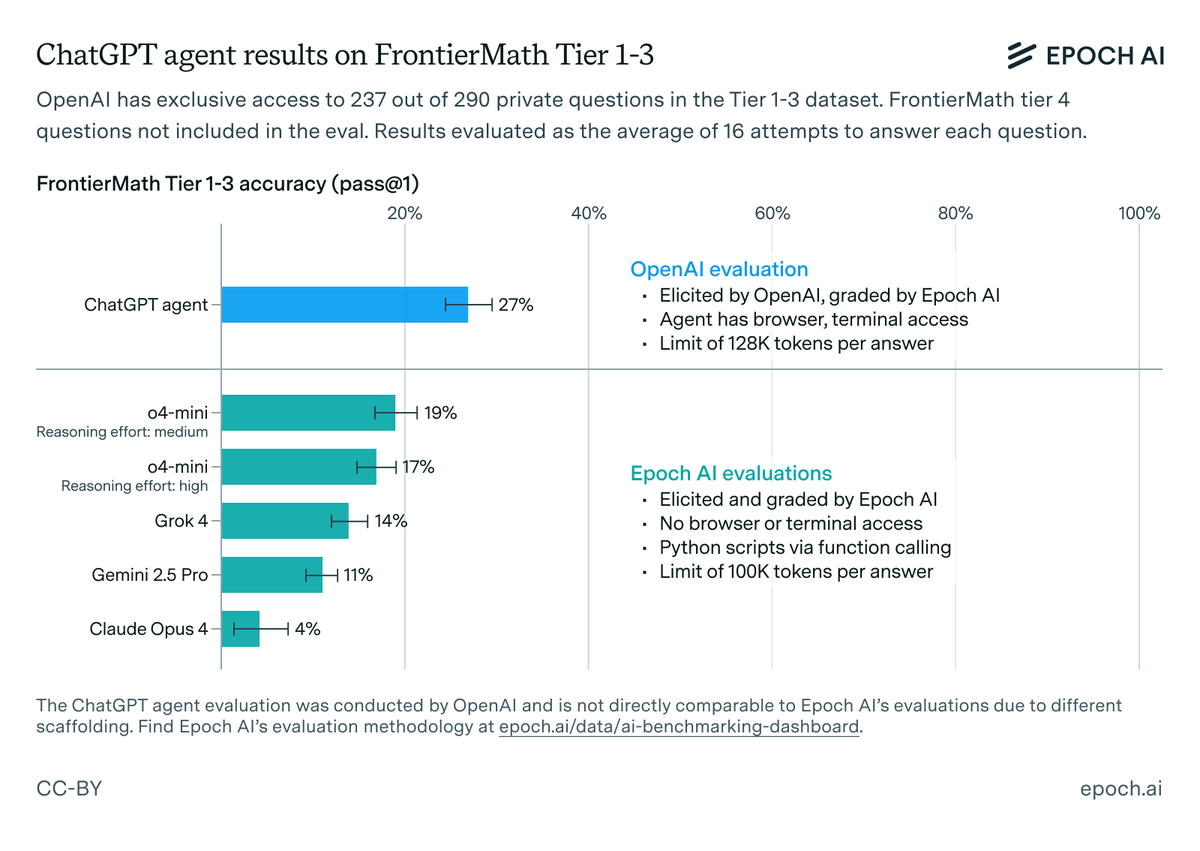
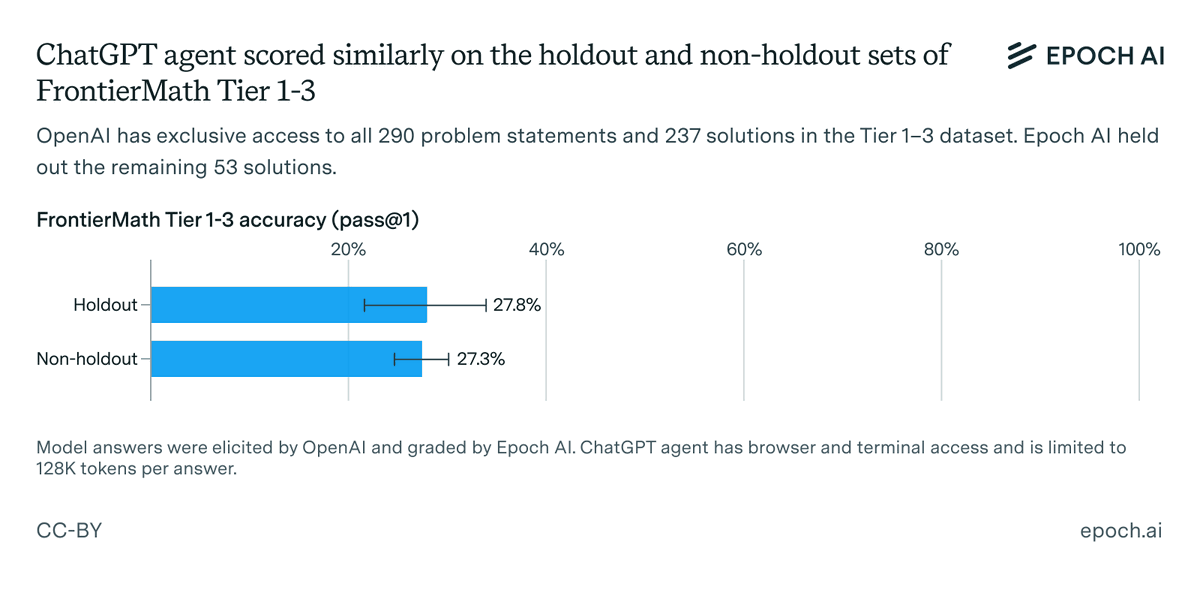
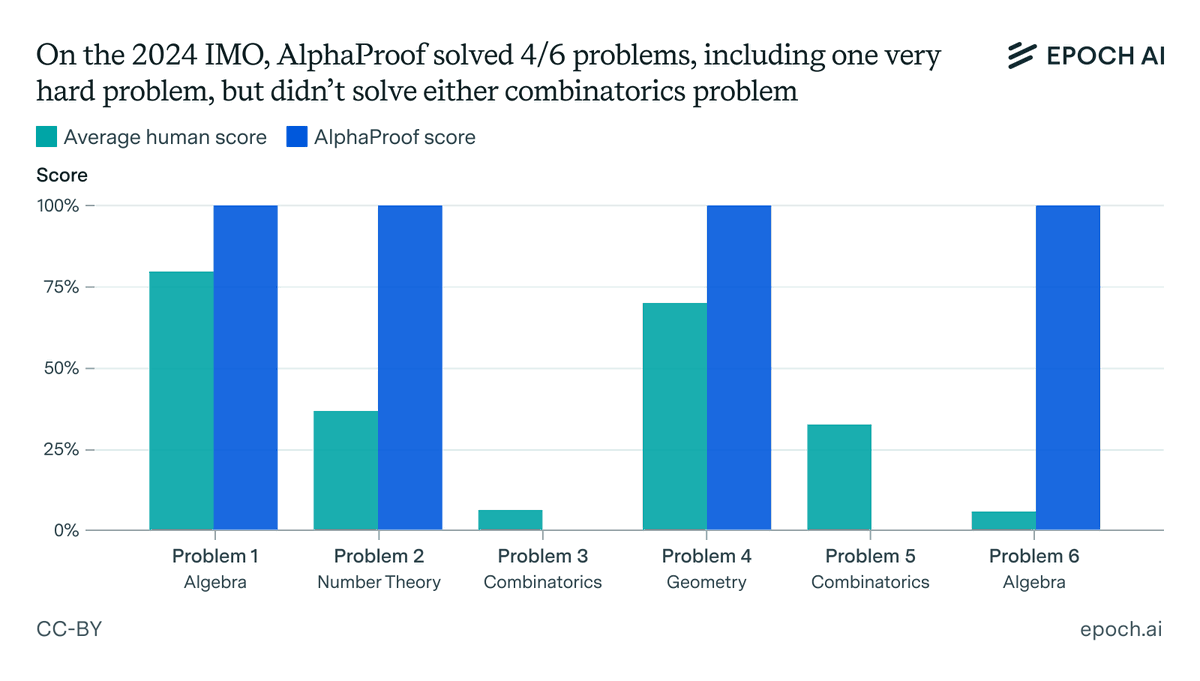
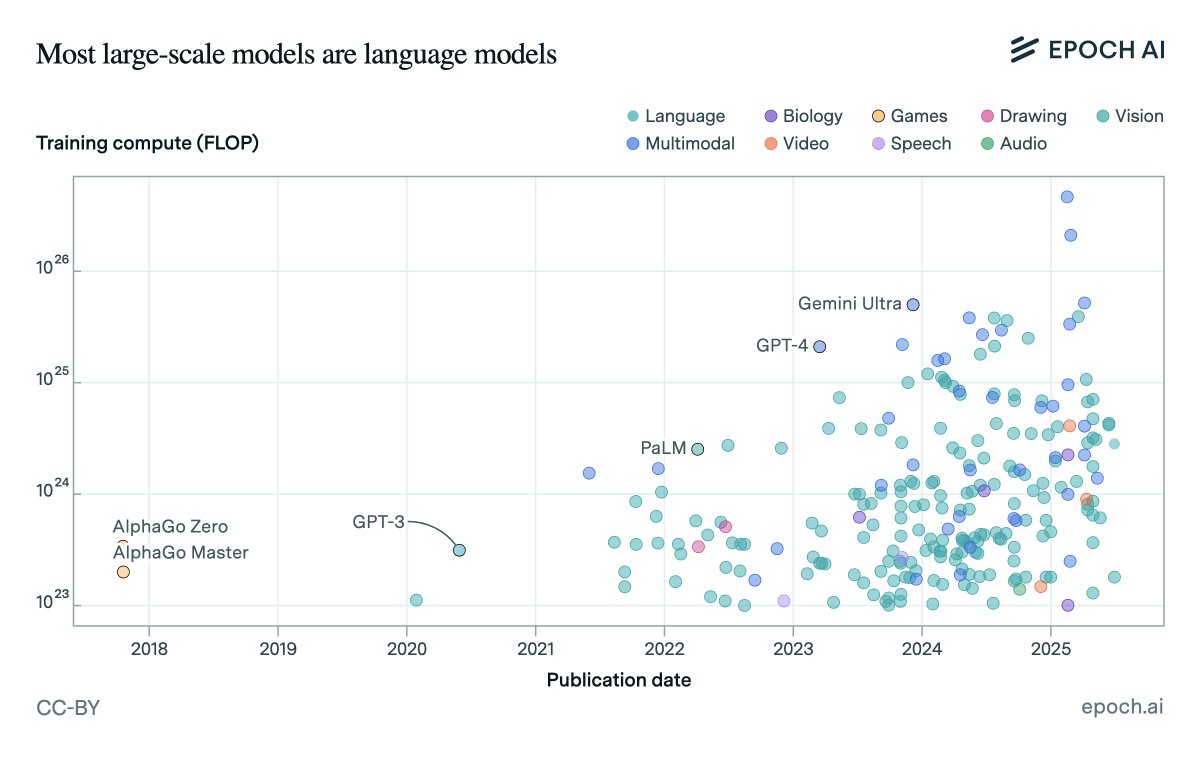
How fast has society been adopting AI?
Back in 2022, ChatGPT arguably became the fastest-growing consumer app ever, hitting 100M users in just 2 months. But the field of AI has transformed since then, and it’s time to take a new look at the numbers. 🧵
Back in 2022, ChatGPT arguably became the fastest-growing consumer app ever, hitting 100M users in just 2 months. But the field of AI has transformed since then, and it’s time to take a new look at the numbers. 🧵
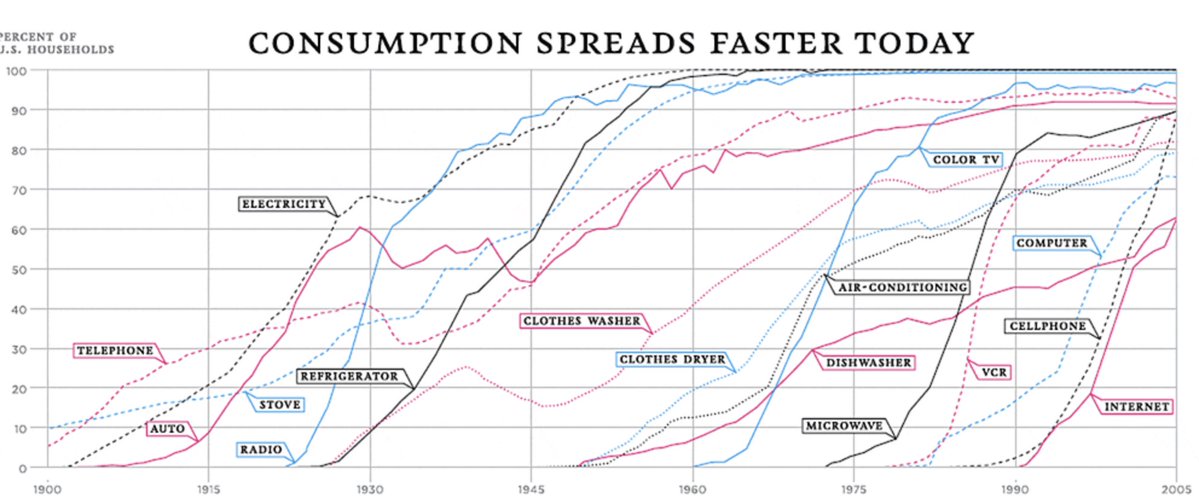
Historically, technology adoption took decades. For example, telephones took 60 years to reach 70% of US households. But tech diffuses faster and faster over time, and we should expect AI to continue this trend.
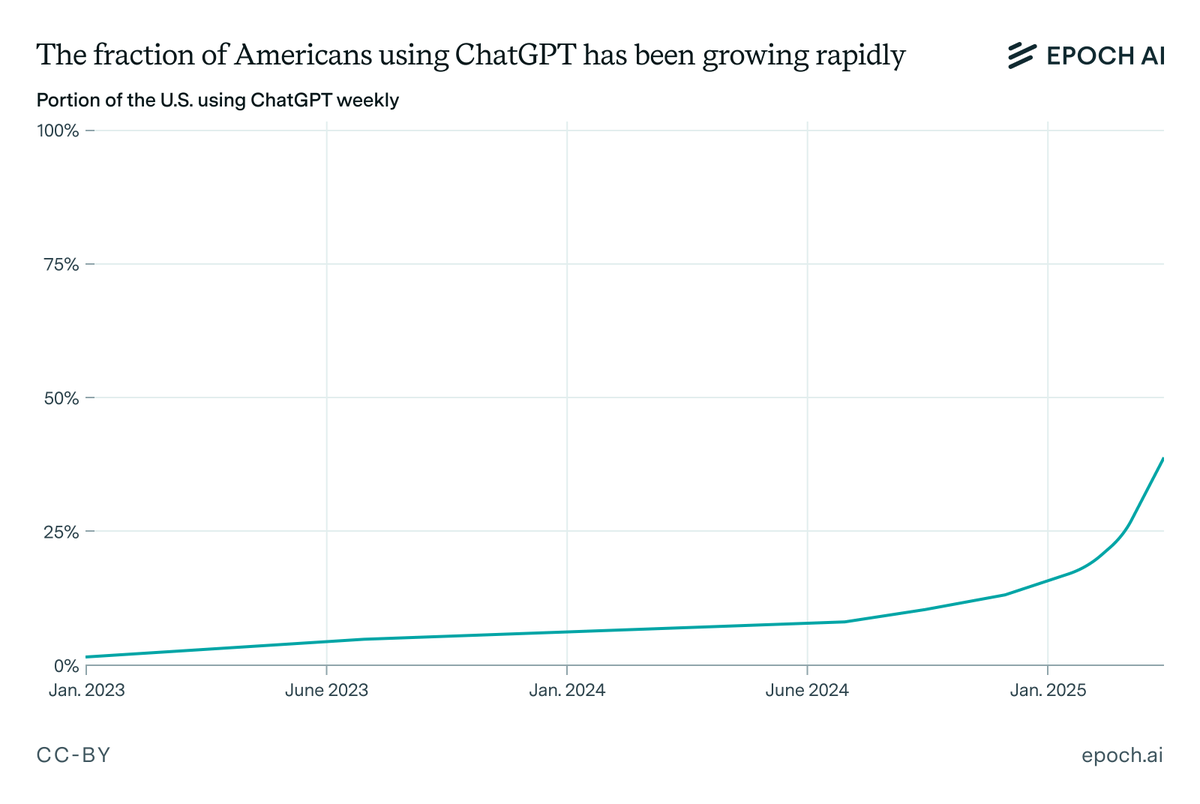
But even if we account for this trend, AI adoption seems incredibly fast. ~10% of the US used ChatGPT weekly within just 2 years, and ~30% in under 2.5 years.
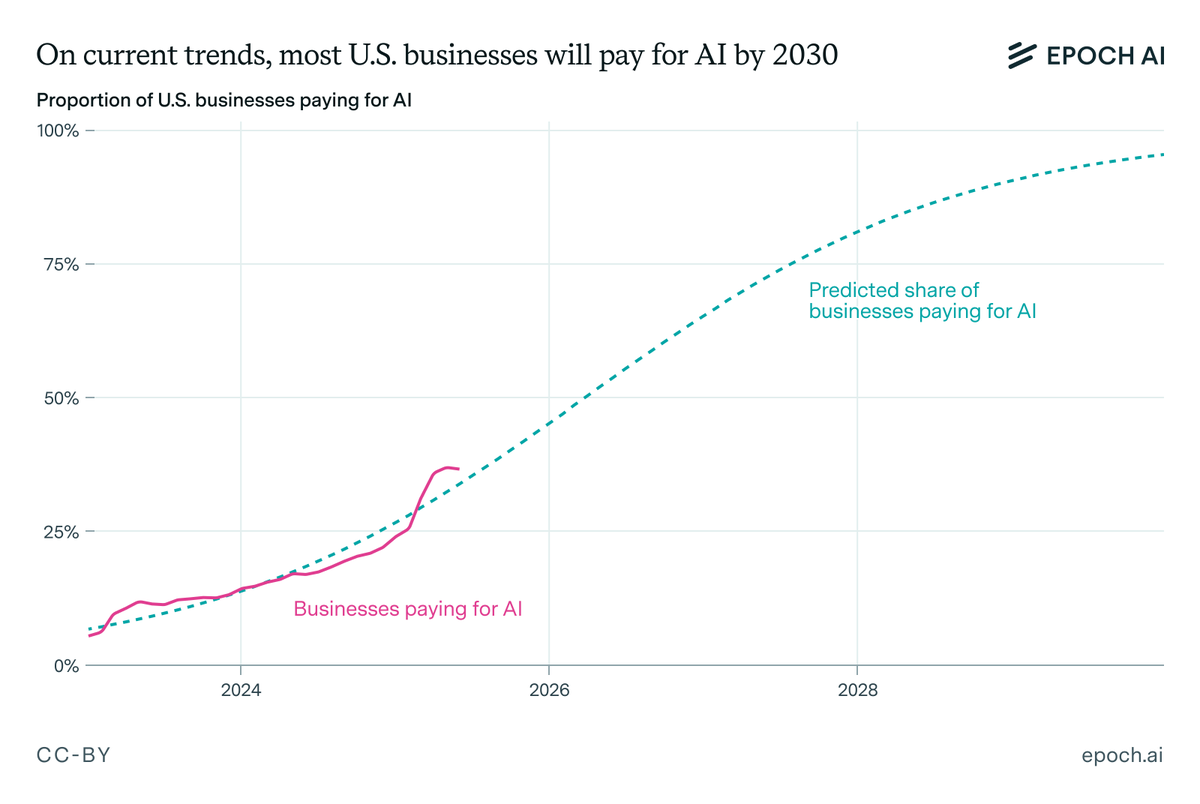
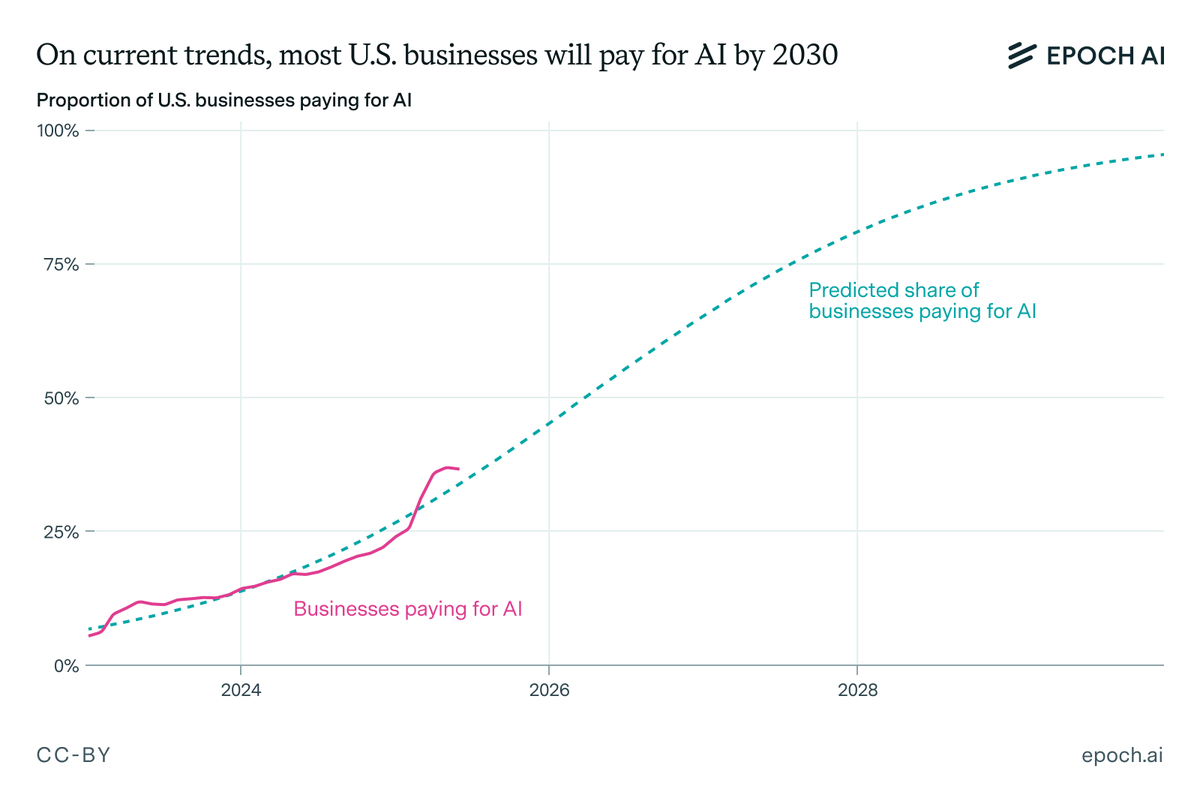
It’s not just ChatGPT. OpenAI, Anthropic, and DeepMind revenues have collectively grown by >$10B since ChatGPT’s release. Furthermore, almost ~40% of US businesses are now paying for AI tools, and this will reach ~80% by 2028 on the current trajectory.
These numbers suggest that AI systems reached the current number of users incredibly quickly, faster than almost any previous technology.
Besides the number of users, to understand the rate of AI diffusion we also need to look at how and how much AI systems are being used. Are people using frontier models more? Are they using them more intensively?
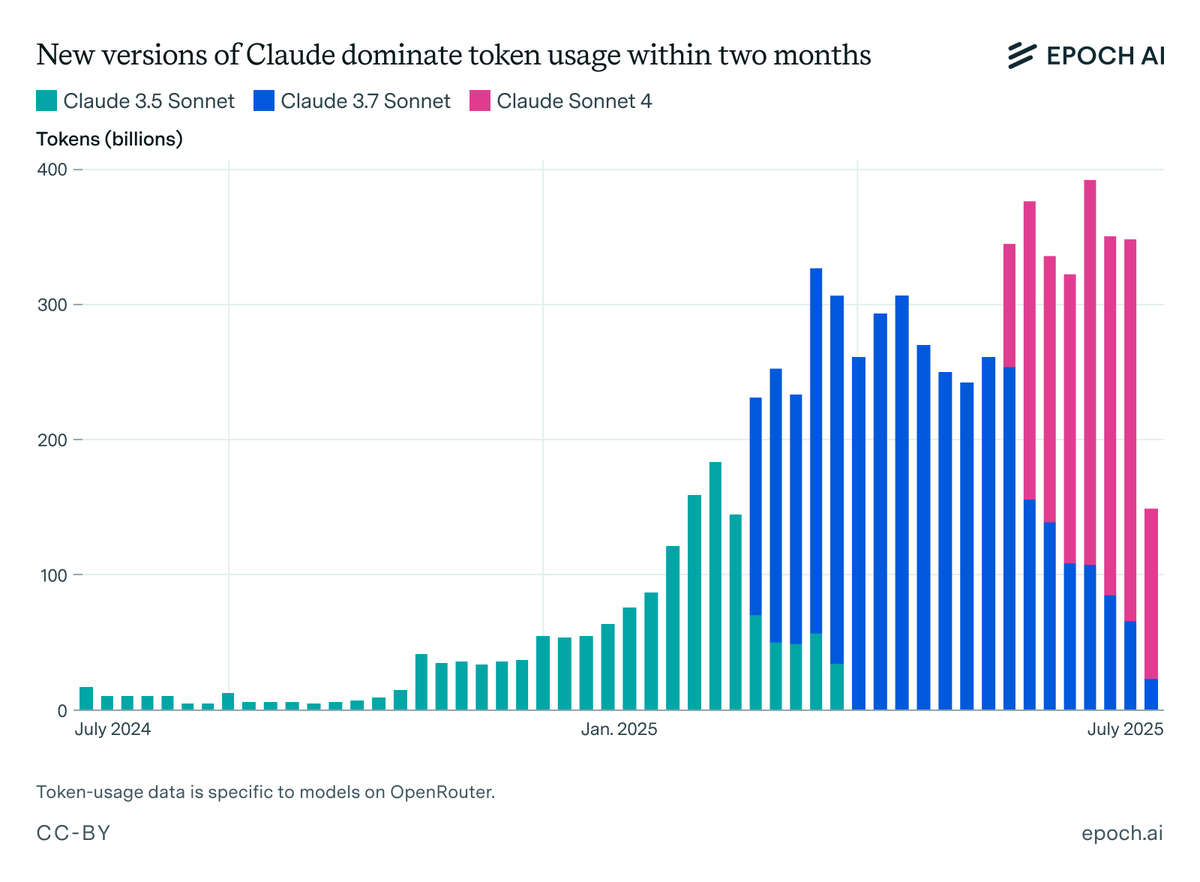
Firstly, ~95% of ChatGPT users are on the free-tier, with limited access to frontier AI. In contrast, paying users quickly adopt the best models: On OpenRouter, nearly all token usage of Claude models shifts to the latest models <2 months after release.
But despite rapid total user growth, the fraction of paid ChatGPT users hasn’t grown. If anything, it’s been declining: paid users grew ~3.3x from Jan 2024 to Apr 2025, but total users increased ~4.5x. That’s evidence against increased usage intensity.
Survey data gives mixed evidence. A Pew survey found no changes in AI interaction frequency between 2022 and 2024, whereas a Gallup poll found frequent use nearly doubled from 11% to 19% (2023-2025), though mostly among white-collar workers.
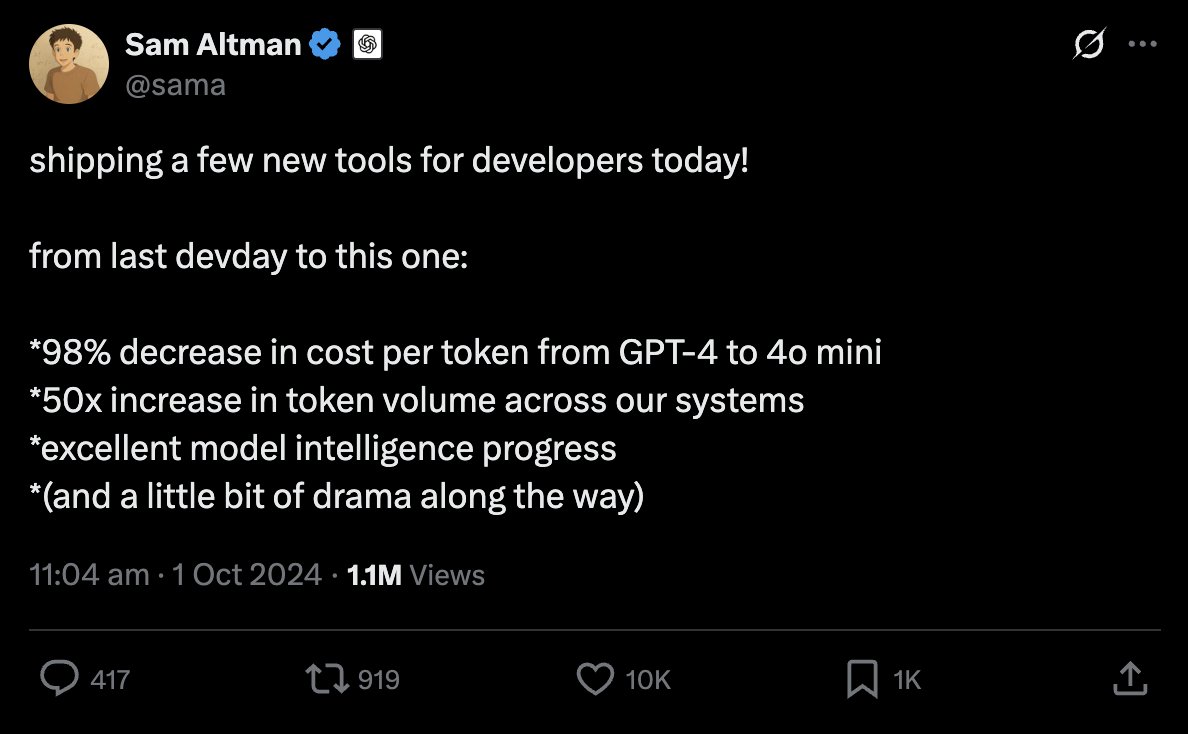
On the other hand, token usage per user has likely grown a lot. Sam Altman reported a 50x increase in OpenAI’s token volume between Nov 2023 and Oct 2024. Adjusting for user growth, that could mean up to ~20x more tokens per user.
Taking everything into account, there have likely also been substantial increases in how much individuals use AI since ChatGPT’s release, though the evidence is somewhat tricky to interpret.
This week’s Gradient Update was coauthored by @ardenaberg and @ansonwhho. You can find the full post here: epochai.substack.com/p/after-the-ch…
• • •
Missing some Tweet in this thread? You can try to
force a refresh