After MCP, A2A, & AG-UI, there's another Agent protocol.
It's fully open-source and launched by IBM Research.
Here's a complete breakdown (with code):
It's fully open-source and launched by IBM Research.
Here's a complete breakdown (with code):

ACP is a standardized, RESTful interface for Agents to discover and coordinate with other Agents, regardless of their framework.
Just like A2A, it lets Agents communicate with Agents. There are some differences, which we shall discuss later.
Let's dive into the code first!
Just like A2A, it lets Agents communicate with Agents. There are some differences, which we shall discuss later.
Let's dive into the code first!
Here's how it works:
- Build the Agents and host them on ACP servers.
- The ACP server receives requests from the ACP Client and forwards them to the Agent.
- ACP Client itself can be an Agent to intelligently route requests to the Agents (like MCP Client does).
Check this 👇
- Build the Agents and host them on ACP servers.
- The ACP server receives requests from the ACP Client and forwards them to the Agent.
- ACP Client itself can be an Agent to intelligently route requests to the Agents (like MCP Client does).
Check this 👇
We’ll create a research summary generator, where:
- Agent 1 drafts a general topic summary (built using CrewAI)
- Agent 2 fact-checks & enhances it using web search (built using Smolagents).
Start by installing some dependencies and a local LLM using Ollama.
Check this 👇
- Agent 1 drafts a general topic summary (built using CrewAI)
- Agent 2 fact-checks & enhances it using web search (built using Smolagents).
Start by installing some dependencies and a local LLM using Ollama.
Check this 👇

In our case, we’ll have two servers, and each server will host one Agent.
Let’s define the server that will host the CrewAI Agent and its LLM.
Here's how we do it 👇
Let’s define the server that will host the CrewAI Agent and its LLM.
Here's how we do it 👇
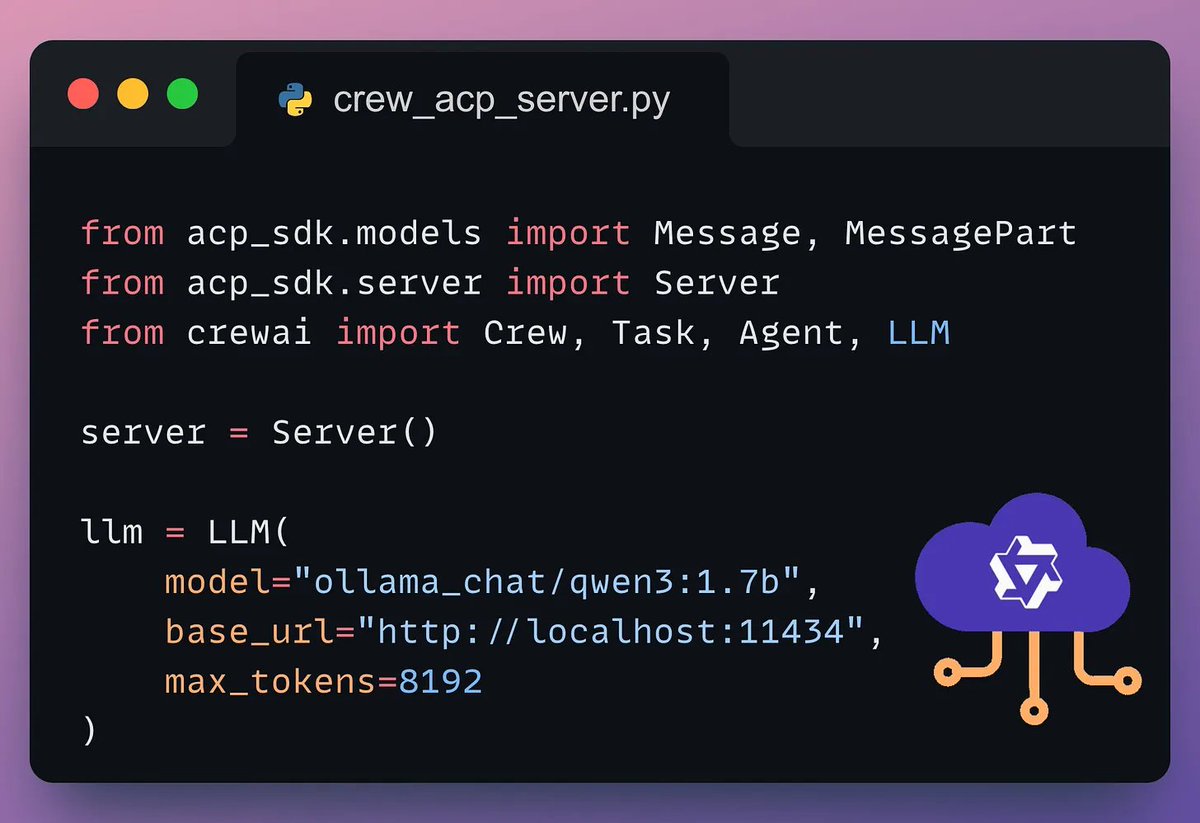
Next, we define an Agent on this server.
- Line 1 → Decorate the method.
- Line 6-21 → Build the Agent and kick off the Crew.
- Line 23 → Return the output in the expected ACP format.
- Line 26 → Serve on a REST-based ACP server running locally.
Check this 👇
- Line 1 → Decorate the method.
- Line 6-21 → Build the Agent and kick off the Crew.
- Line 23 → Return the output in the expected ACP format.
- Line 26 → Serve on a REST-based ACP server running locally.
Check this 👇

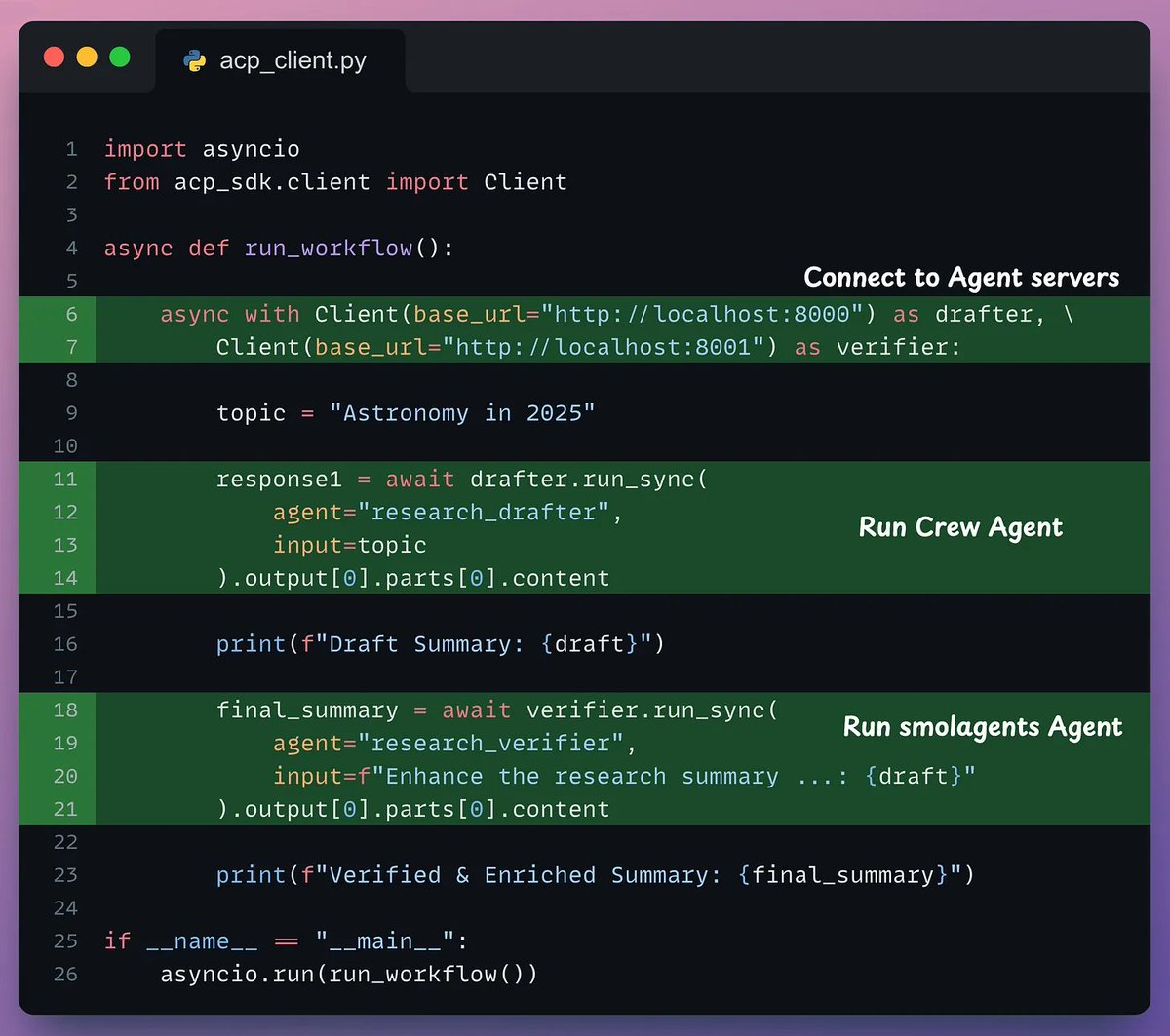
Next, repeat these steps for the 2nd server to host the Smolagents Agent and its LLM.
- Line 1-10 → Imports + define the Server & the LLM.
- Line 12 → Decorate the method.
- Line 21-28 → Define the Agent with a web search tool.
- Line 31 → Serve the Agent.
Check this 👇
- Line 1-10 → Imports + define the Server & the LLM.
- Line 12 → Decorate the method.
- Line 21-28 → Define the Agent with a web search tool.
- Line 31 → Serve the Agent.
Check this 👇
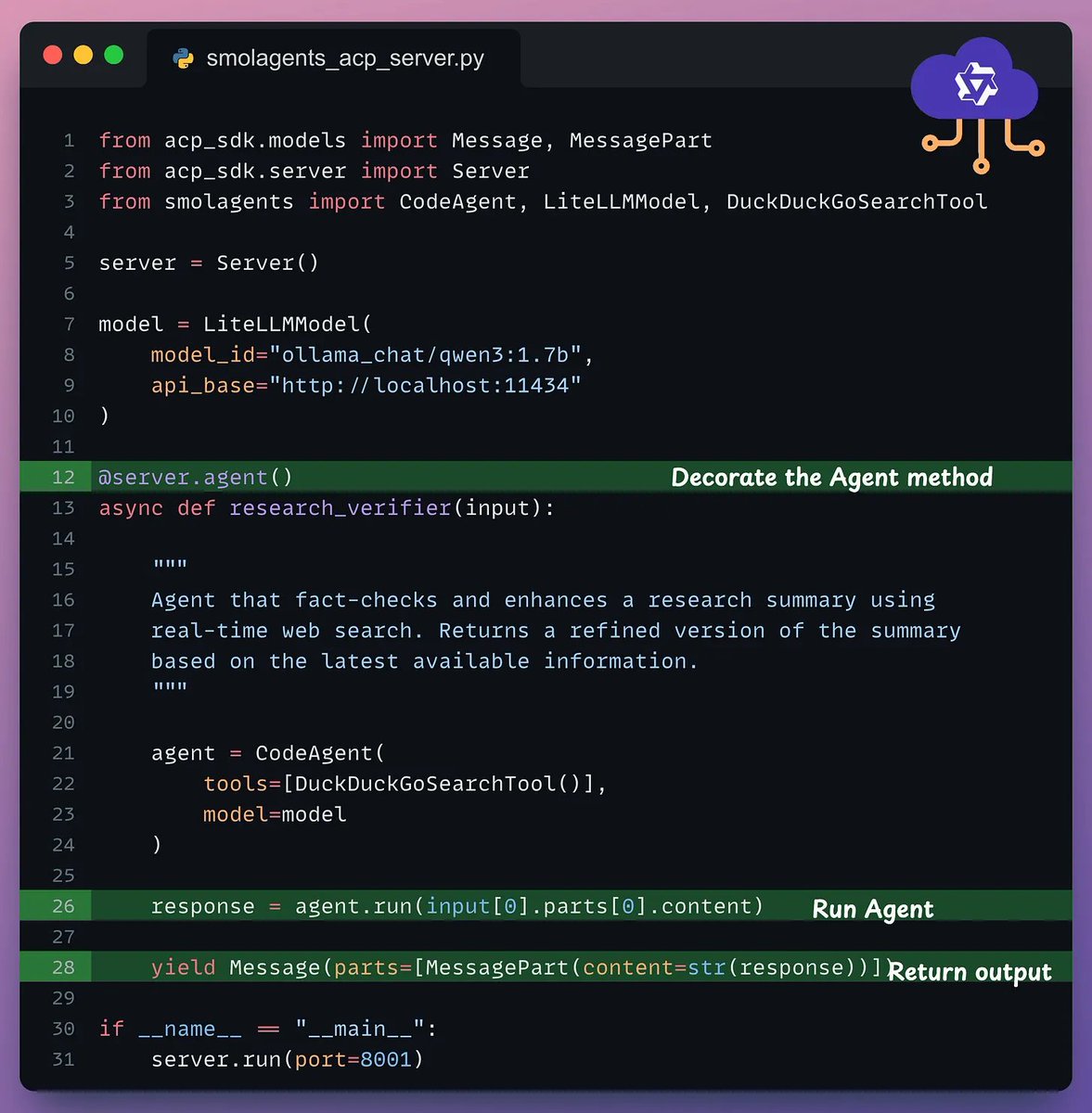
Finally, we use an ACP client to connect both agents in a workflow.
- Line 6-7 → Connect the client to both servers.
- Line 11-14 → Invoke the first agent to receive an output.
- Line 18-21 → Pass the output to the next agent for enhancement.
Check this 👇
- Line 6-7 → Connect the client to both servers.
- Line 11-14 → Invoke the first agent to receive an output.
- Line 18-21 → Pass the output to the next agent for enhancement.
Check this 👇
Almost done!
Run the two servers as follows 👇
Run the two servers as follows 👇
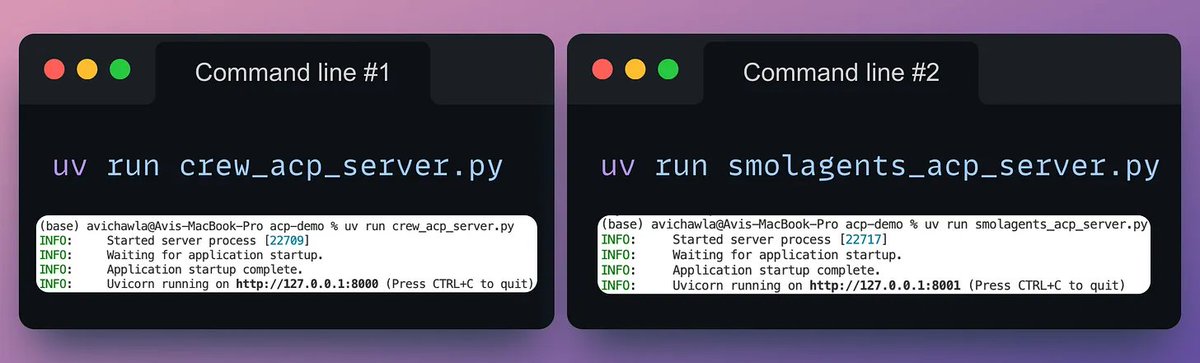
And then run the client to get an output from a system that’s powered by ACP using `uv run acp_client[.]py`
Check this 👇
Check this 👇

This demo showcases how you can use ACP to enable Agents to communicate via a standardized protocol, even if they are built using different frameworks.
How is ACP different from A2A?
- ACP is built for local-first, low-latency communication.
- A2A is optimized for web-native, cross-vendor interoperability
- ACP uses a RESTful interface, making it easier to embed in your stack.
- A2A supports more flexible, natural interactions.
- ACP excels in controlled, edge, or team-specific setups.
- A2A shines in broader cloud-based collaboration
How is ACP different from A2A?
- ACP is built for local-first, low-latency communication.
- A2A is optimized for web-native, cross-vendor interoperability
- ACP uses a RESTful interface, making it easier to embed in your stack.
- A2A supports more flexible, natural interactions.
- ACP excels in controlled, edge, or team-specific setups.
- A2A shines in broader cloud-based collaboration

That's a wrap!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
https://twitter.com/1175166450832687104/status/1946095899261972952
• • •
Missing some Tweet in this thread? You can try to
force a refresh