Today, we're announcing a preview of ARC-AGI-3, the Interactive Reasoning Benchmark with the widest gap between easy for humans and hard for AI
We’re releasing:
* 3 games (environments)
* $10K agent contest
* AI agents API
Starting scores - Frontier AI: 0%, Humans: 100%
We’re releasing:
* 3 games (environments)
* $10K agent contest
* AI agents API
Starting scores - Frontier AI: 0%, Humans: 100%

Every game environment is novel, unique, and only requires core-knowledge priors
No language, trivia, or specialized knowledge is needed to beat the games
* Play: three.arcprize.org
* Compete: arcprize.org/arc-agi/3/
* Build: three.arcprize.org/docs
No language, trivia, or specialized knowledge is needed to beat the games
* Play: three.arcprize.org
* Compete: arcprize.org/arc-agi/3/
* Build: three.arcprize.org/docs
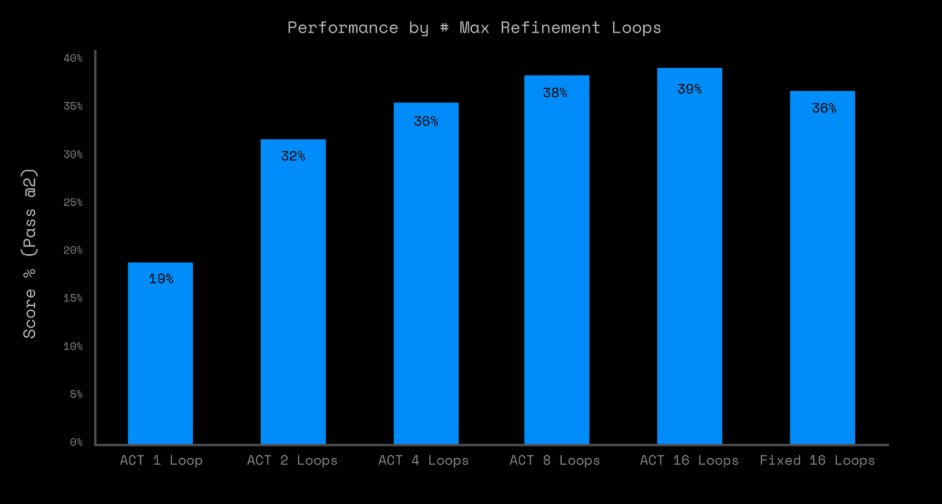
Your ability to efficiently adapt to novelty defines your intelligence, not your performance on a single-skill
Harder puzzles don’t prove smarter AI, but rather its ability to learn new rules does
ARC Prize exists to operationalize that insight
Harder puzzles don’t prove smarter AI, but rather its ability to learn new rules does
ARC Prize exists to operationalize that insight
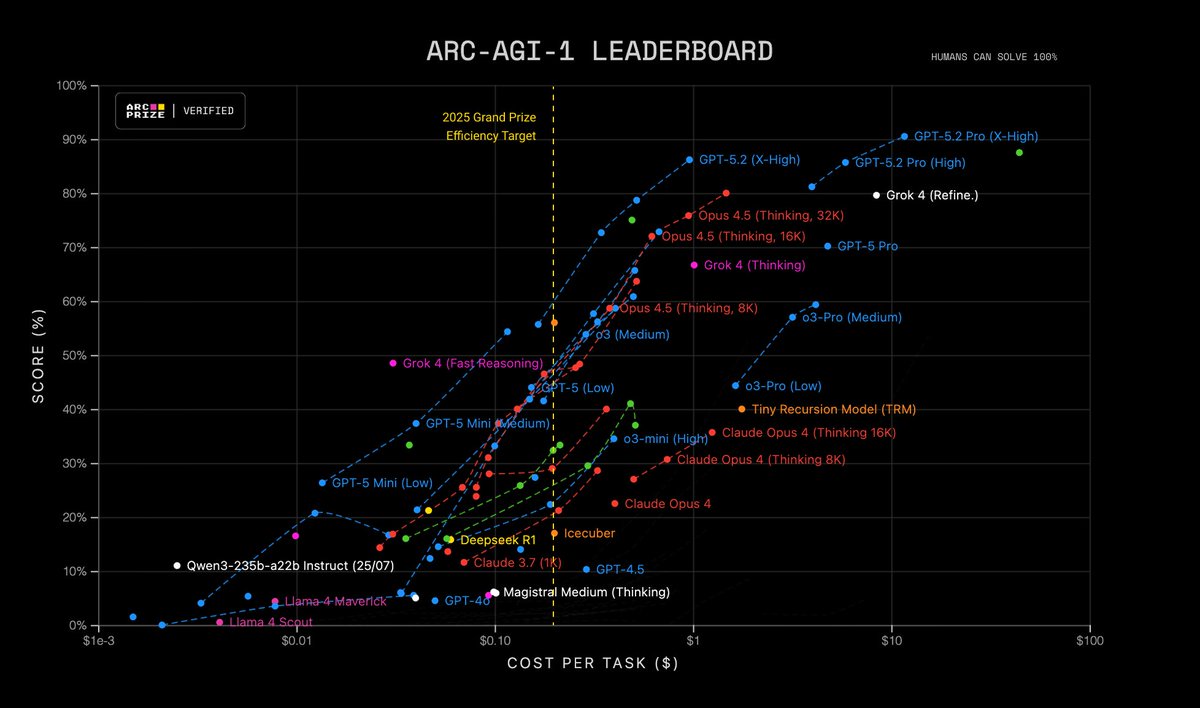
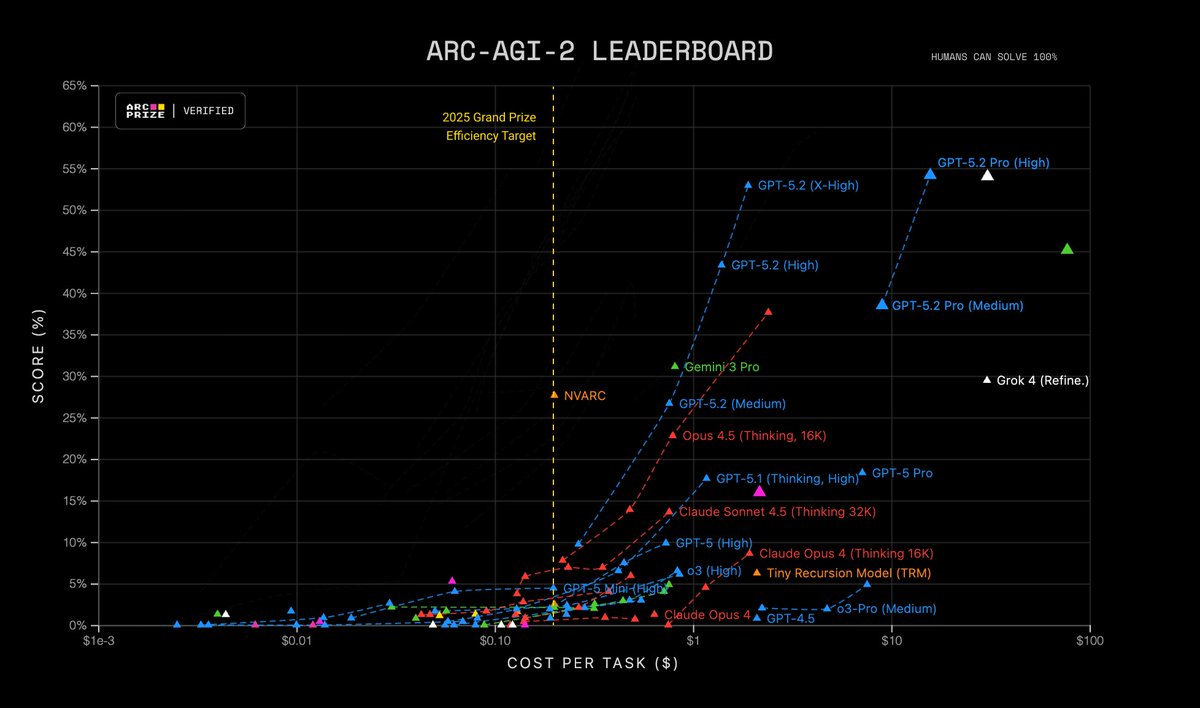
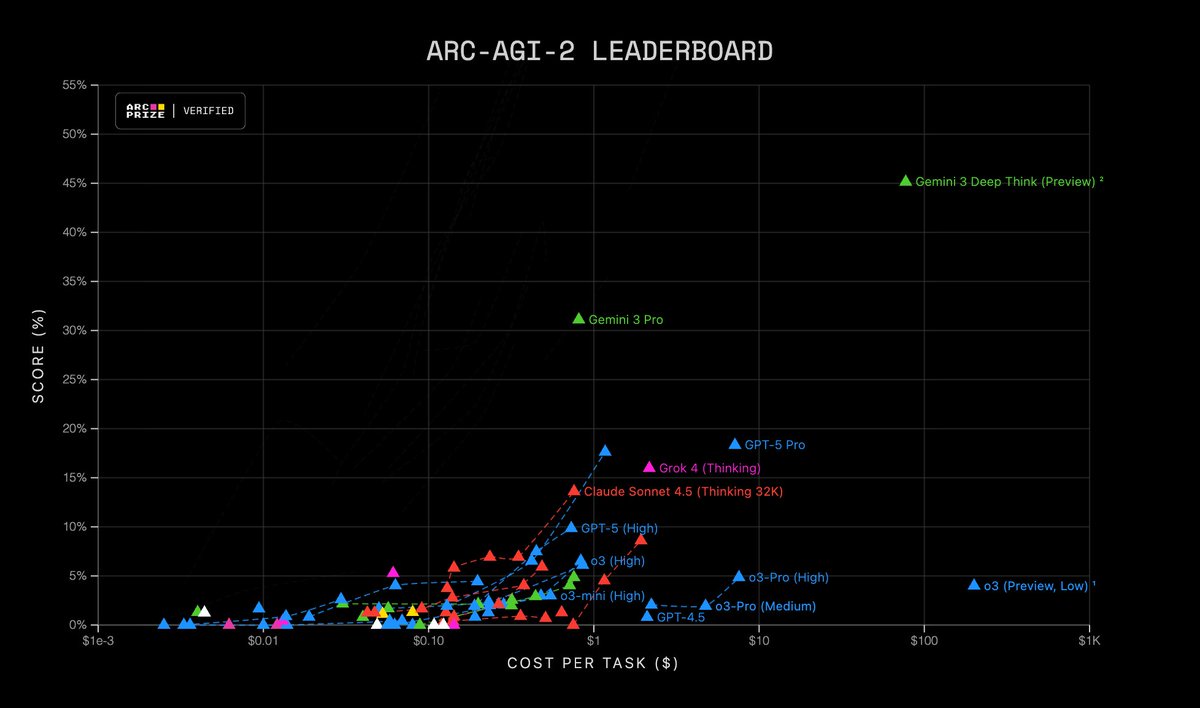
We create benchmarks that highlight the gap between human generalization and machine pattern‑matching
ARC‑AGI‑1 (2019) challenged deep‑learning
ARC‑AGI‑2 (2025) challenges static reasoning models
ARC‑AGI‑1 (2019) challenged deep‑learning
ARC‑AGI‑2 (2025) challenges static reasoning models
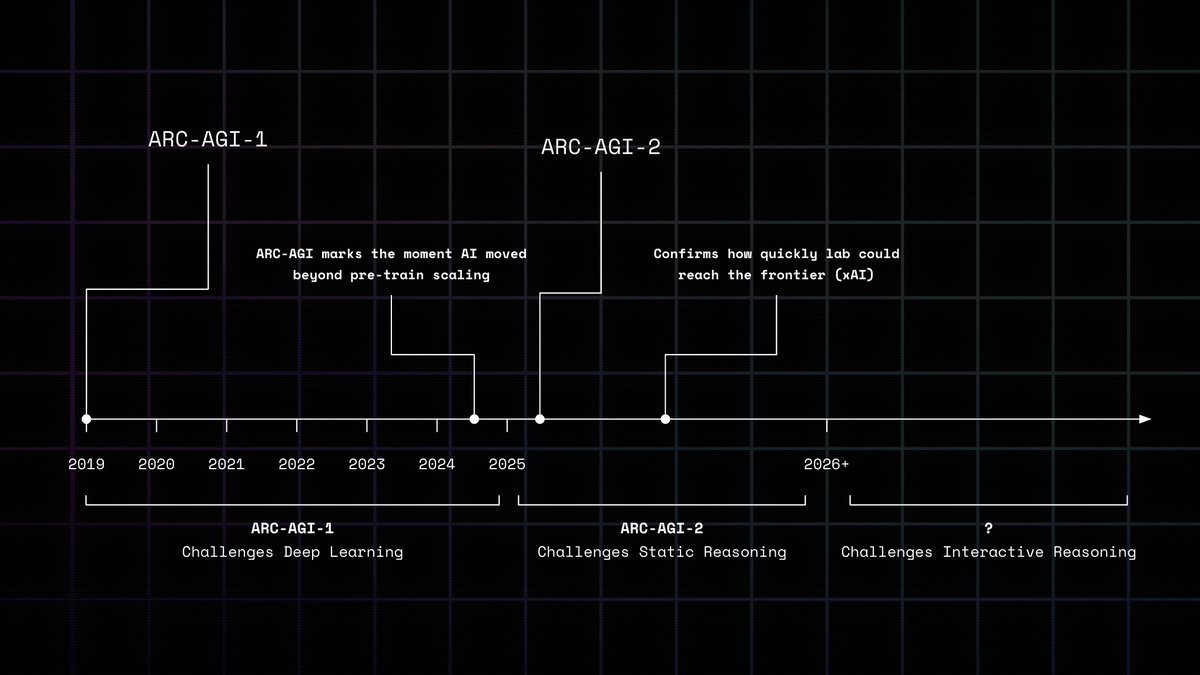
Agents are now the frontier. They perceive, plan, act, remember, adapt. Static puzzles aren’t equipped to grade that loop
We need interactive benchmarks that test world‑model building and long‑horizon planning under sparse feedback
We need interactive benchmarks that test world‑model building and long‑horizon planning under sparse feedback

Enter ARC‑AGI‑3
6 brand‑new games. Easy for humans, out of reach for today’s best AI models
3 games are live today, 3 will go live in August
6 brand‑new games. Easy for humans, out of reach for today’s best AI models
3 games are live today, 3 will go live in August

ARC-AGI API ships today
Plug in any LLM, RL, or hybrid agent, train locally, test against our servers
Plug in any LLM, RL, or hybrid agent, train locally, test against our servers

o3 (left) and Grok 4 (right) replays below
spoiler: neither complete a single level
spoiler: neither complete a single level
ARC-AGI-3 Preview games need to be pressure tested. We’re hosting a 30-day agent competition in partnership with @huggingface
We’re calling on the community to build agents (and win money!)
arcprize.org/competitions/a…
We’re calling on the community to build agents (and win money!)
arcprize.org/competitions/a…

We're excited to share this preview of ARC-AGI-3. This is just the beginning
Visit to learn morearcprize.org/arc-agi/3
Visit to learn morearcprize.org/arc-agi/3
• • •
Missing some Tweet in this thread? You can try to
force a refresh