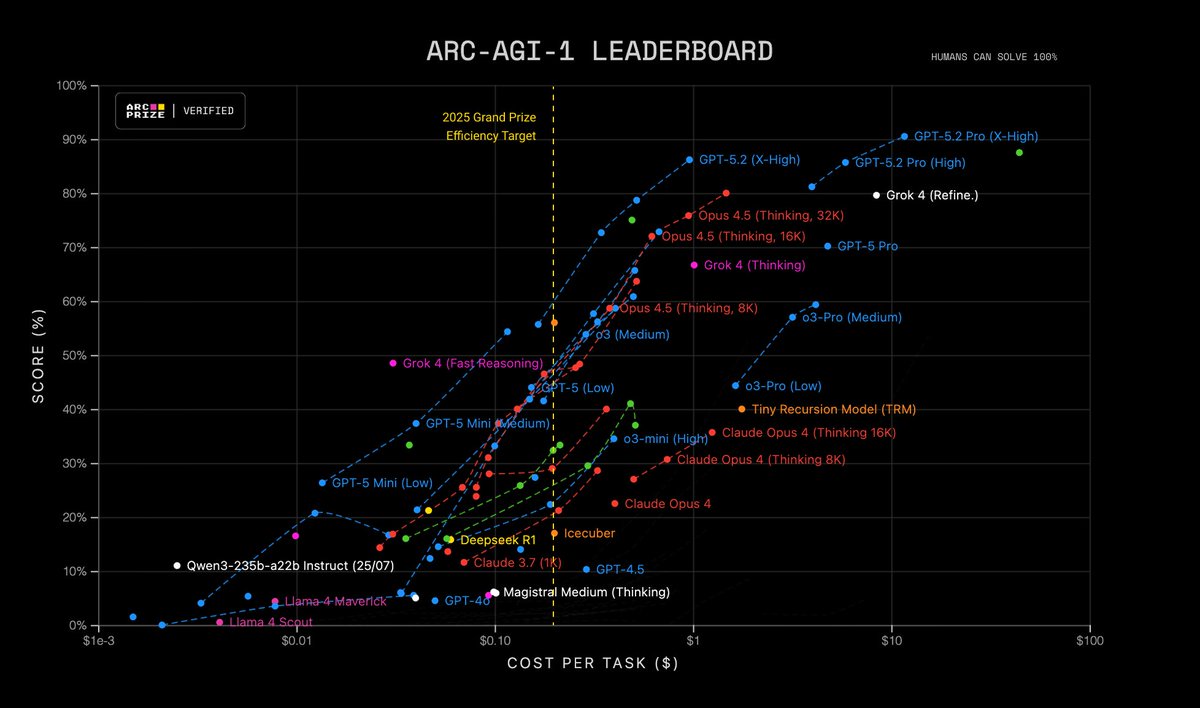
 We also verified that GPT-5.2 Pro (High) is SOTA for ARC-AGI-2, scoring 54.2% for $15.72/task
We also verified that GPT-5.2 Pro (High) is SOTA for ARC-AGI-2, scoring 54.2% for $15.72/task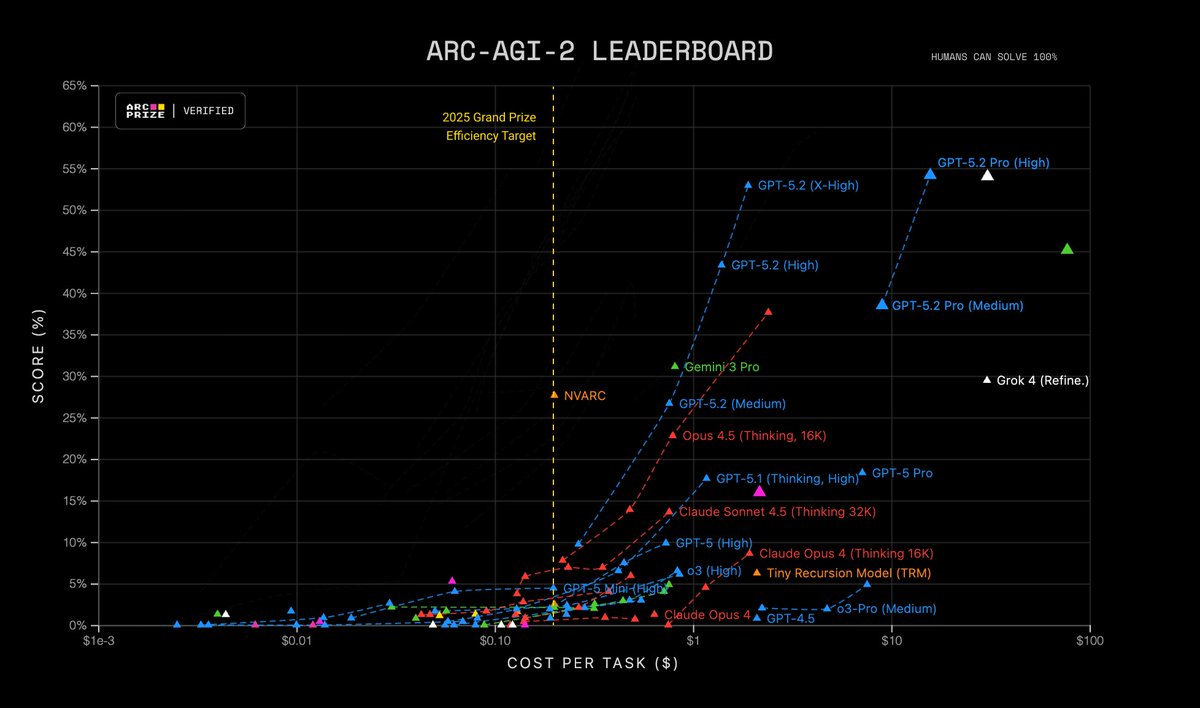
 ARC Prize 2025 Paper Award Winners
ARC Prize 2025 Paper Award Winners
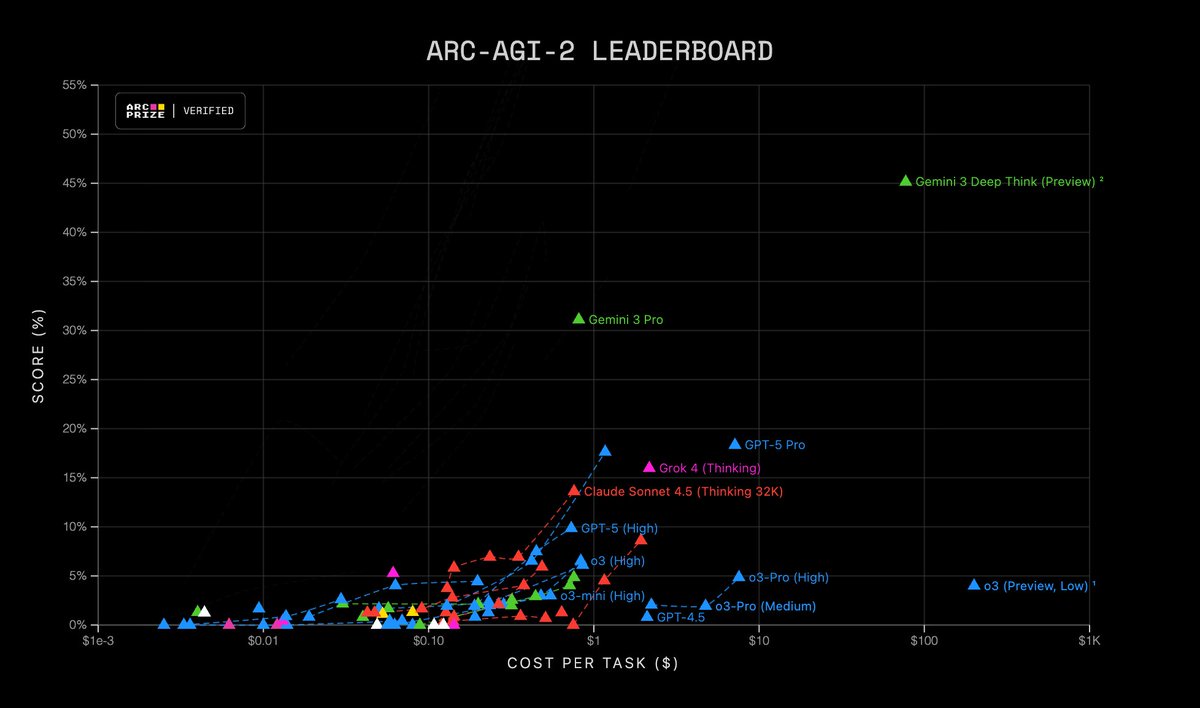 Also, notable - Gemini 3 results on ARC-AGI-1 (Semi-Private Eval)
Also, notable - Gemini 3 results on ARC-AGI-1 (Semi-Private Eval)
 Finding #1: The "hierarchical" architecture had minimal performance impact when compared to a similarly sized transformer
Finding #1: The "hierarchical" architecture had minimal performance impact when compared to a similarly sized transformer
 Every game environment is novel, unique, and only requires core-knowledge priors
Every game environment is novel, unique, and only requires core-knowledge priors On ARC-AGI-1, Grok 4 (Thinking) achieves 66.7% inline with the Pareto frontier for AI reasoning systems we reported last month
On ARC-AGI-1, Grok 4 (Thinking) achieves 66.7% inline with the Pareto frontier for AI reasoning systems we reported last month 
 As mentioned before, OpenAI has confirmed that the version of o3 that was released last week is not the same version that we tested in December ‘24.
As mentioned before, OpenAI has confirmed that the version of o3 that was released last week is not the same version that we tested in December ‘24. ARC-AGI-1 (2019) pinpointed the moment AI moved beyond pure memorization in late 2024 demonstrated by OpenAI's o3 system.
ARC-AGI-1 (2019) pinpointed the moment AI moved beyond pure memorization in late 2024 demonstrated by OpenAI's o3 system. In part due to ARC Prize 2024, we believe AGI progress is no longer stalled.
In part due to ARC Prize 2024, we believe AGI progress is no longer stalled.