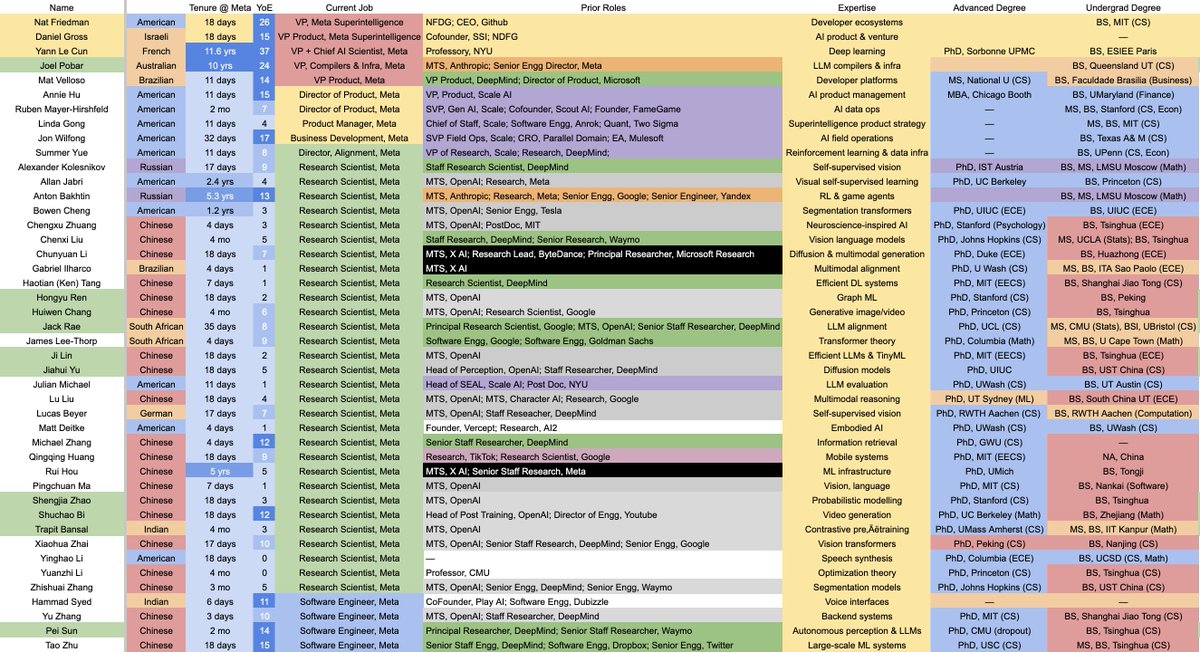
🚨 BREAKING: Detailed list of all 44 people in Meta's Superintelligence team.
— 50% from China
— 75% have PhDs, 70% Researchers
— 40% from OpenAI, 20% DeepMind, 15% Scale
— 20% L8+ level
— 75% 1st gen immigrants
Each of these people are likely getting paid $10-$100M/yr.
— 50% from China
— 75% have PhDs, 70% Researchers
— 40% from OpenAI, 20% DeepMind, 15% Scale
— 20% L8+ level
— 75% 1st gen immigrants
Each of these people are likely getting paid $10-$100M/yr.
Source: anonymous Meta employee
• • •
Missing some Tweet in this thread? You can try to
force a refresh