Today (w/ @UniofOxford @Stanford @MIT @LSEnews) we’re sharing the results of the largest AI persuasion experiments to date: 76k participants, 19 LLMs, 707 political issues.
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more
🧵
We examine “levers” of AI persuasion: model scale, post-training, prompting, personalization, & more
🧵
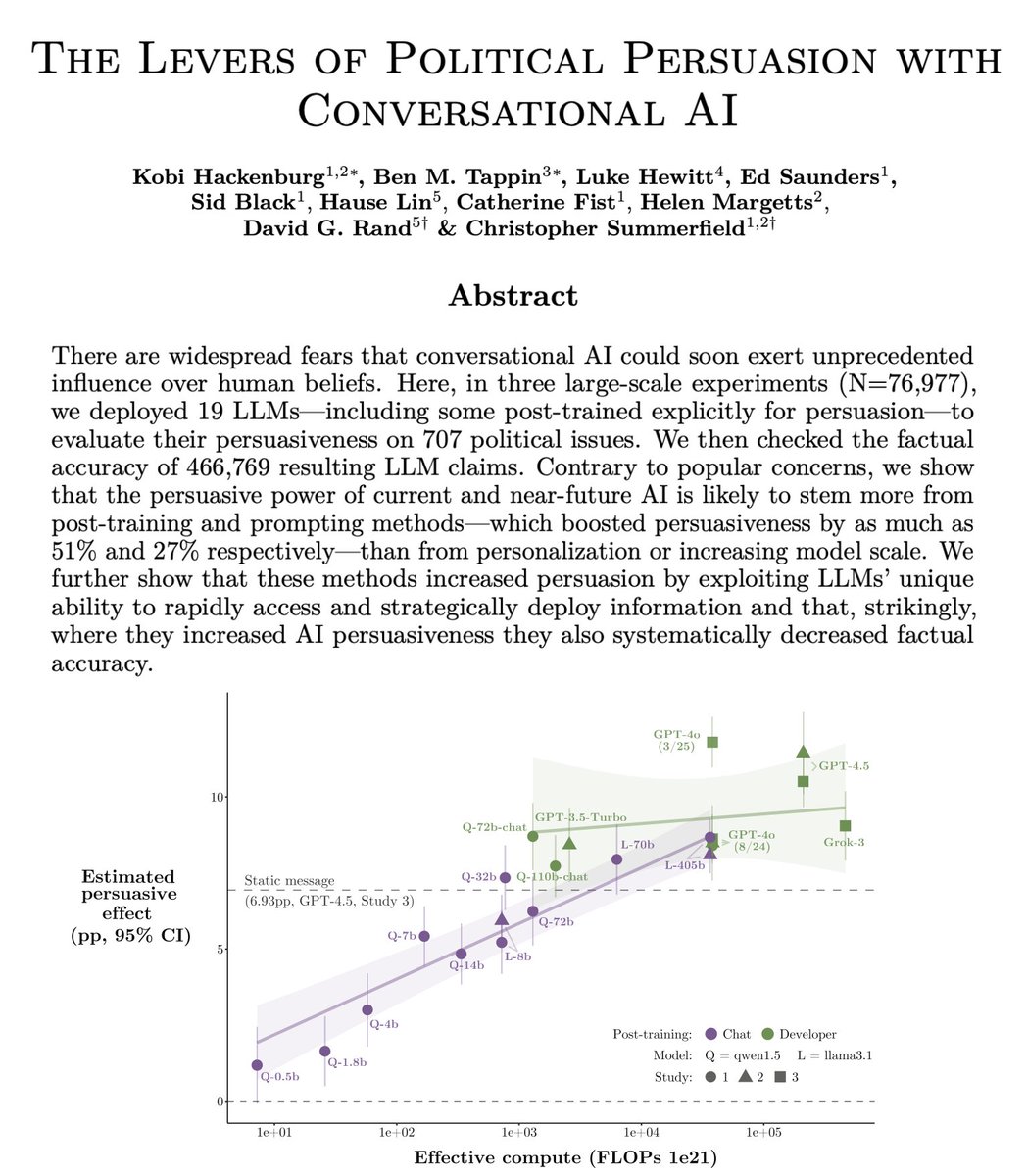
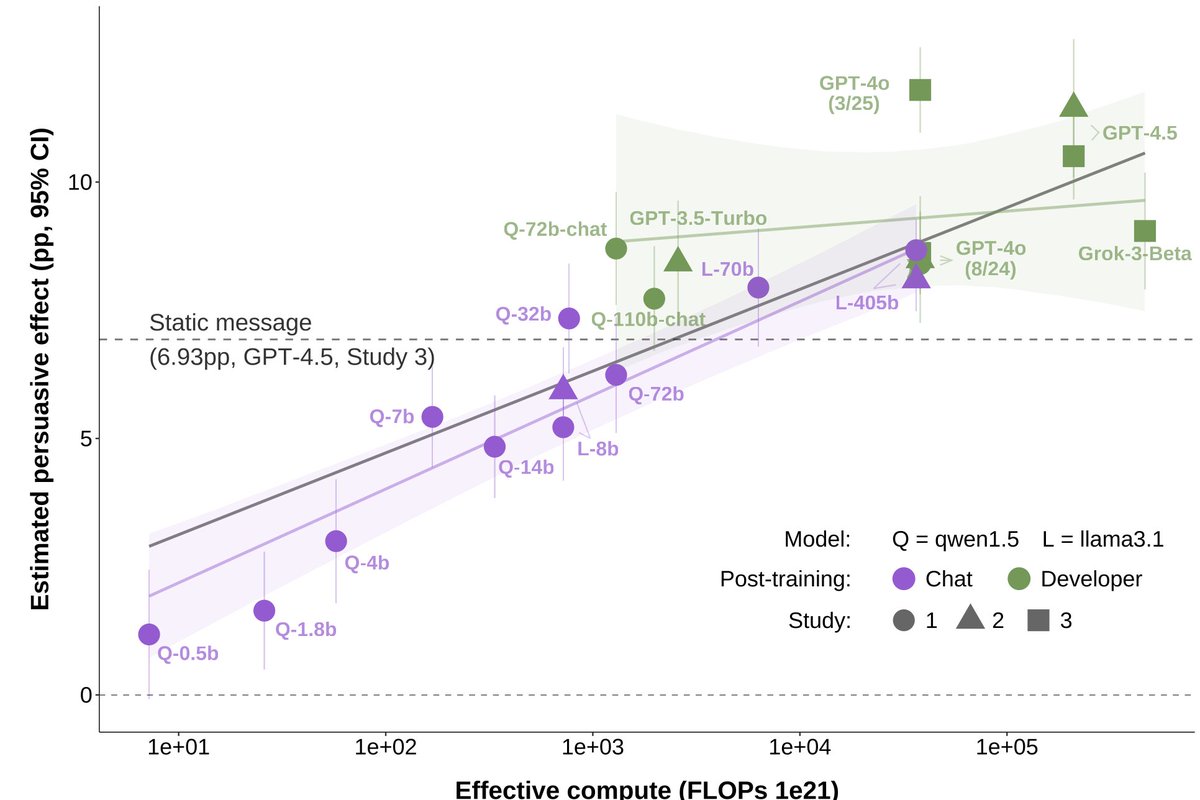
RESULTS (pp = percentage points):
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, +3.5pp
3️⃣Personalization less so, <1pp
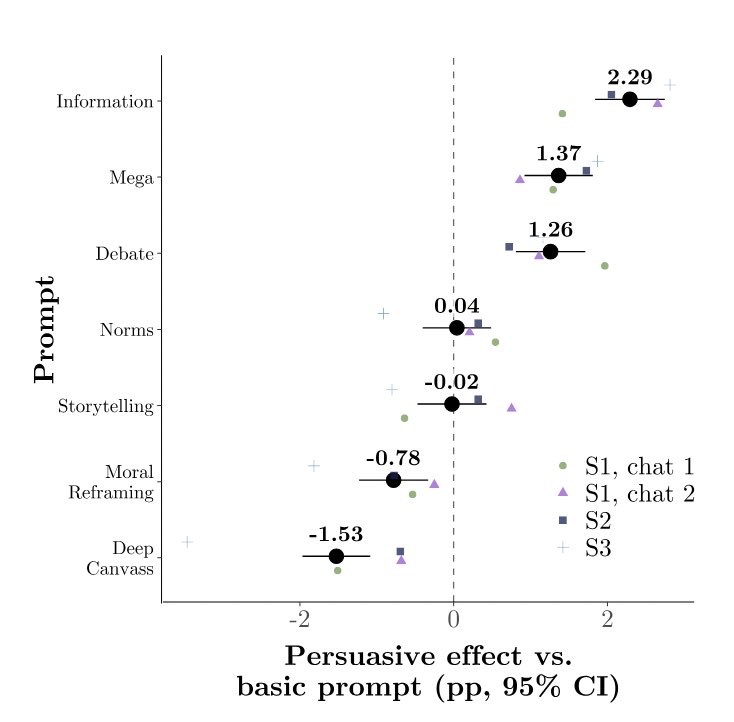
4️⃣Information density drives persuasion gains
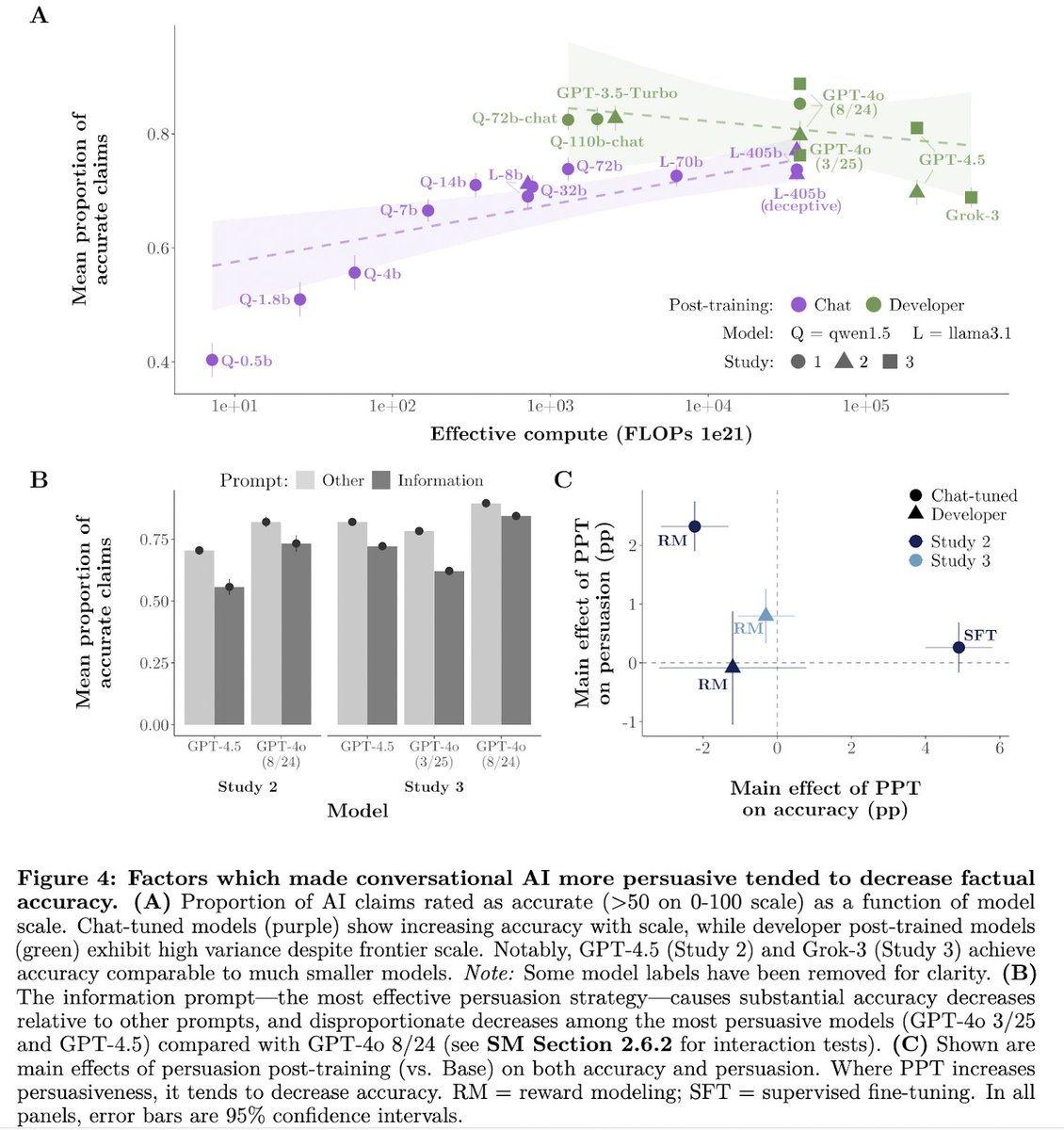
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%
1️⃣Scale increases persuasion, +1.6pp per OOM
2️⃣Post-training more so, +3.5pp
3️⃣Personalization less so, <1pp
4️⃣Information density drives persuasion gains
5️⃣Increasing persuasion decreased factual accuracy 🤯
6️⃣Convo > static, +40%




1️⃣Scale increases persuasion
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
Larger models are more persuasive than smaller models (our estimate is +1.6pp per 10x scale increase).
Log-linear curve preferred over log-nonlinear.
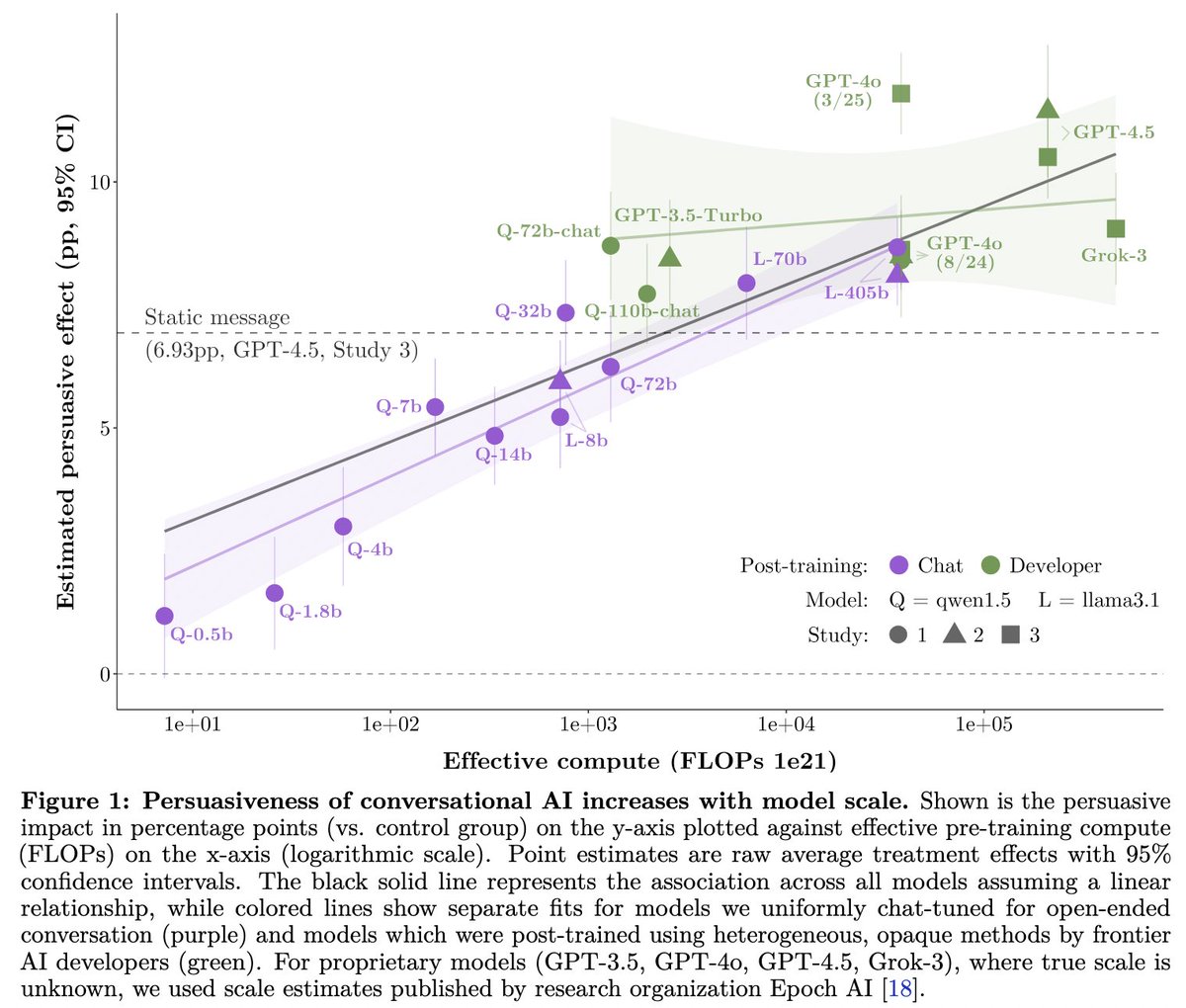
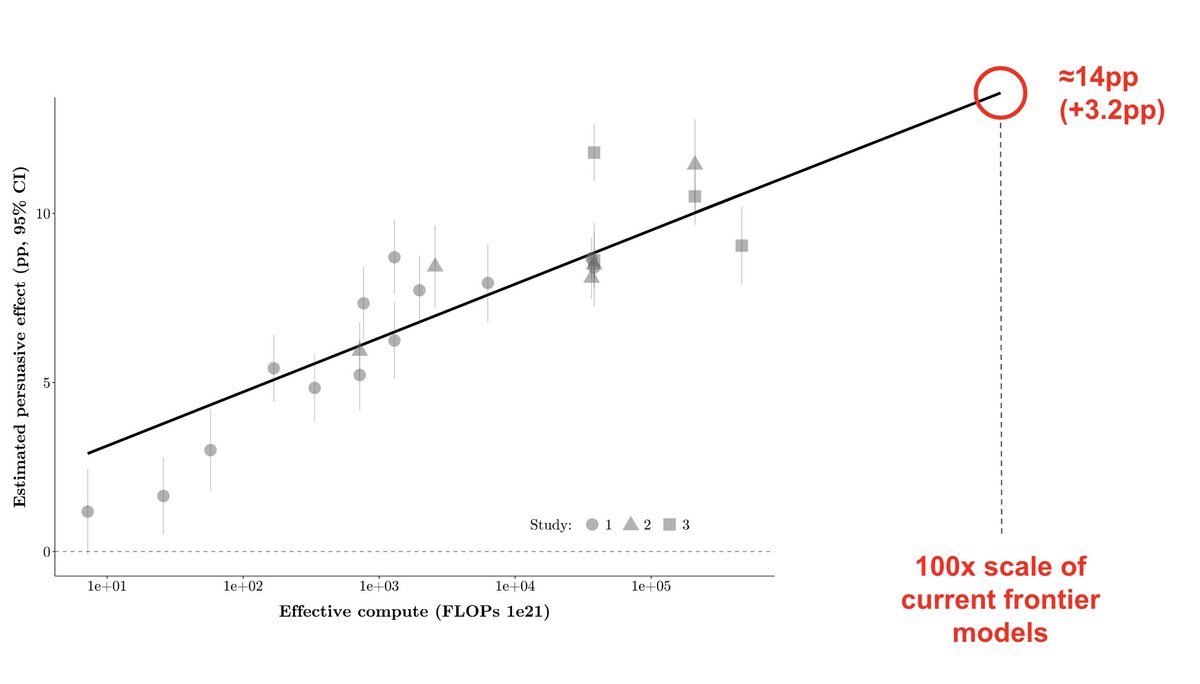
2️⃣Post-training > scale in driving near-future persuasion gains
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
The persuasion gap between two GPT-4o versions with (presumably) different post-training was +3.5pp → larger than the predicted persuasion increase of a model 10x (or 100x!) the scale of GPT-4.5 (+1.6pp; +3.2pp).
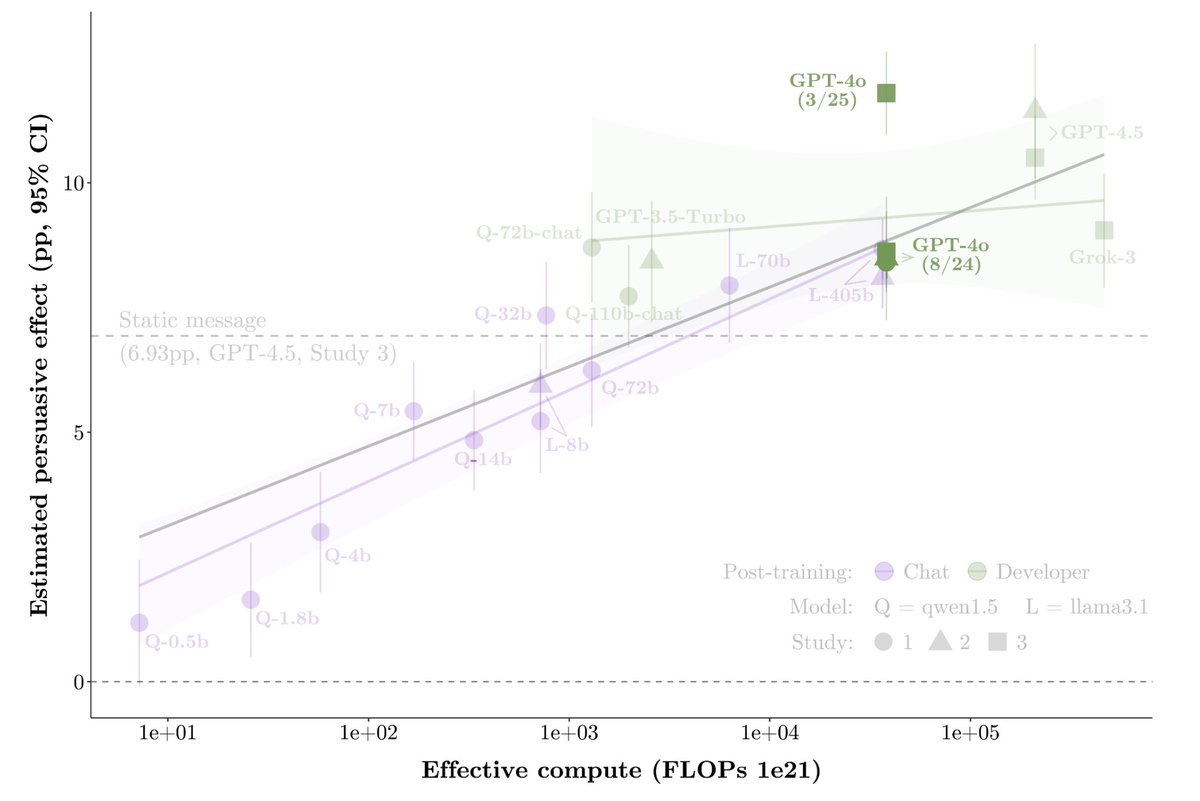

2️⃣(cont.) Post-training explicitly for persuasion (PPT) can bring small open-source models to frontier persuasiveness
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (avg. +0.6pp)
A llama3.1-8b model with PPT reached GPT-4o persuasiveness. PPT also increased persuasiveness of larger models: llama3.1-405b (+2pp) and frontier (avg. +0.6pp)

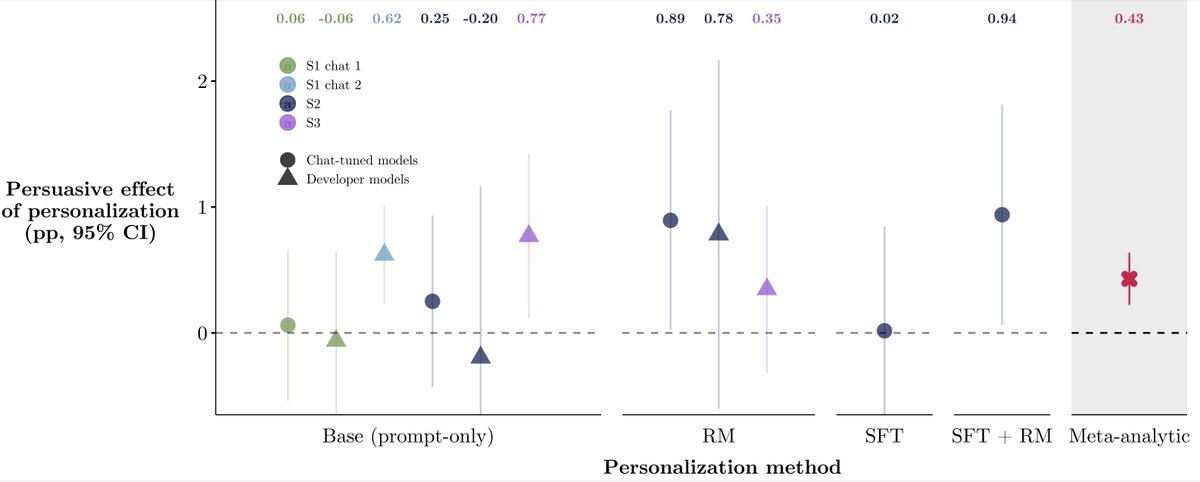
3️⃣Personalization yielded smaller persuasive gains than scale or post-training
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.). Held for simple and sophisticated personalization: prompting, fine-tuning, and reward modeling (all <1pp)
Despite fears of AI "microtargeting," personalization effects were small (+0.4pp on avg.). Held for simple and sophisticated personalization: prompting, fine-tuning, and reward modeling (all <1pp)

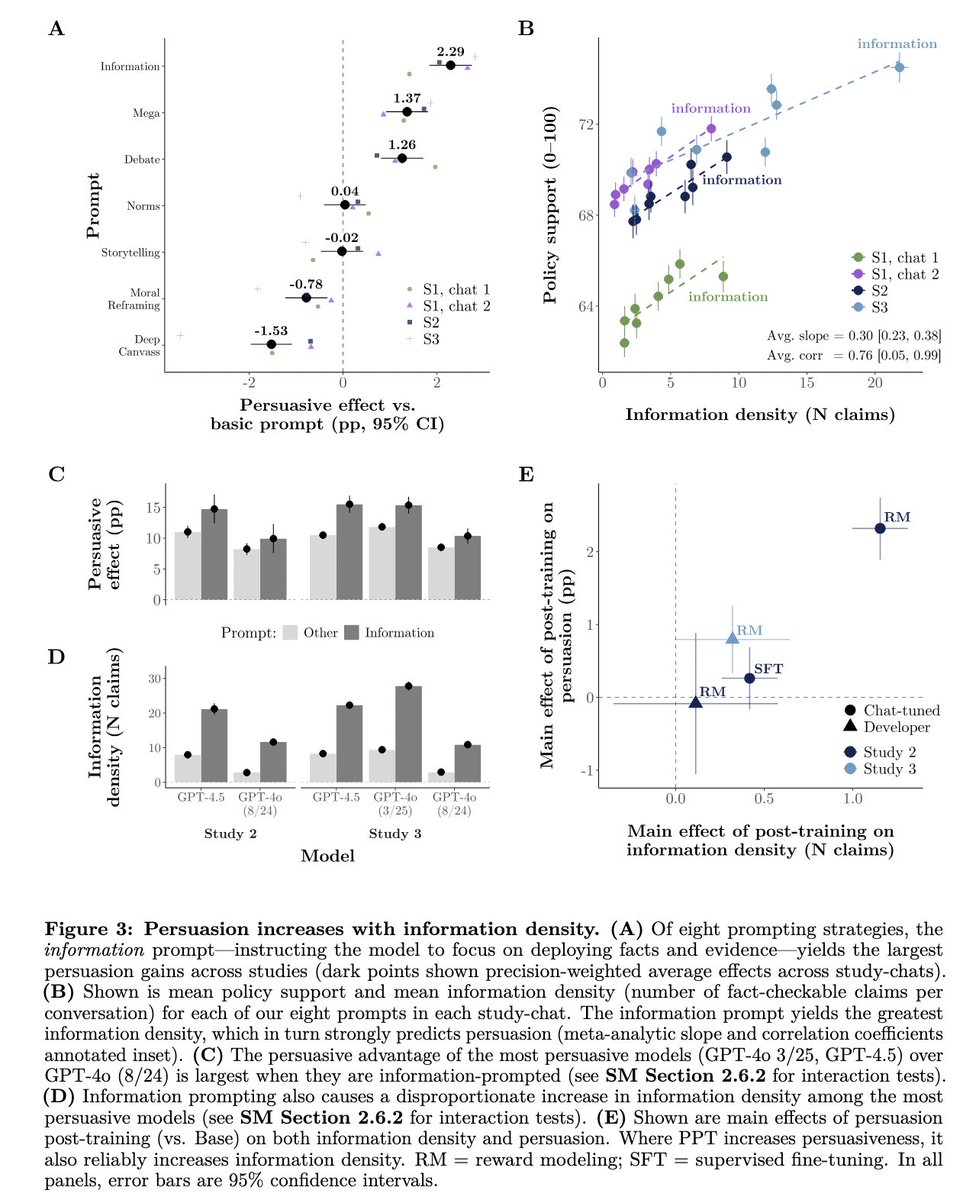
4️⃣Information density drives persuasion gains
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
Models were most persuasive when flooding conversations with fact-checkable claims (+0.3pp per claim).
Strikingly, the persuasiveness of prompting/post-training techniques was strongly correlated with their impact on info density!
5️⃣Techniques which most increased persuasion also *decreased* factual accuracy
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
→ Prompting model to flood conversation with information (⬇️accuracy)
→ Persuasion post-training that worked best (⬇️accuracy)
→ Newer version of GPT-4o which was most persuasive (⬇️accuracy)
6️⃣Conversations with AI are more persuasive than reading a static AI-generated message (+40-50%)
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
Observed for both GPT-4o (+2.9pp, +41% more persuasive) and GPT-4.5 (+3.6pp, +52%).
Bonus stats:
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt
*️⃣Durable persuasion: 36-42% of impact remained after 1 month.
*️⃣Prompting the model with psychological persuasion strategies did worse than simply telling it to flood convo with info. Some strategies were worse than a basic “be as persuasive as you can” prompt
Taken together, our findings suggest that the persuasiveness of conversational AI could likely continue to increase in the near future.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
They also suggest that near-term advances in persuasion are more likely to be driven by post-training than model scale or personalization.
Consequently, we note that while our targeted persuasion post-training experiments significantly increased persuasion, they should be interpreted as a lower bound for what is achievable, not as a high-water mark.
Finally, we emphasize some important caveats:
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @j_kalla and co)
→ Technical factors and/or hard limits on human persuadability may constrain future increases in AI persuasion
→ Real-world bottleneck for AI persuasion: getting people to engage (cf. recent work from @j_kalla and co)

It was my pleasure to lead this project alongside @Ben_Tappin, with the support of @lukebeehewitt @hauselin @realmeatyhuman Ed Saunders @CatherineFist @HelenMargetts under the supervision of @DG_Rand and @summerfieldlab
I’m also very grateful to many people @AISecurityInst —especially my team—for making this work possible!
There will be lots more where this came from over the next few months 👀
There will be lots more where this came from over the next few months 👀
You can read the full working paper here:
arxiv.org/abs/2507.13919
Supplementary materials can be found here:
github.com/kobihackenburg…
Comments and feedback welcome :)
arxiv.org/abs/2507.13919
Supplementary materials can be found here:
github.com/kobihackenburg…
Comments and feedback welcome :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh