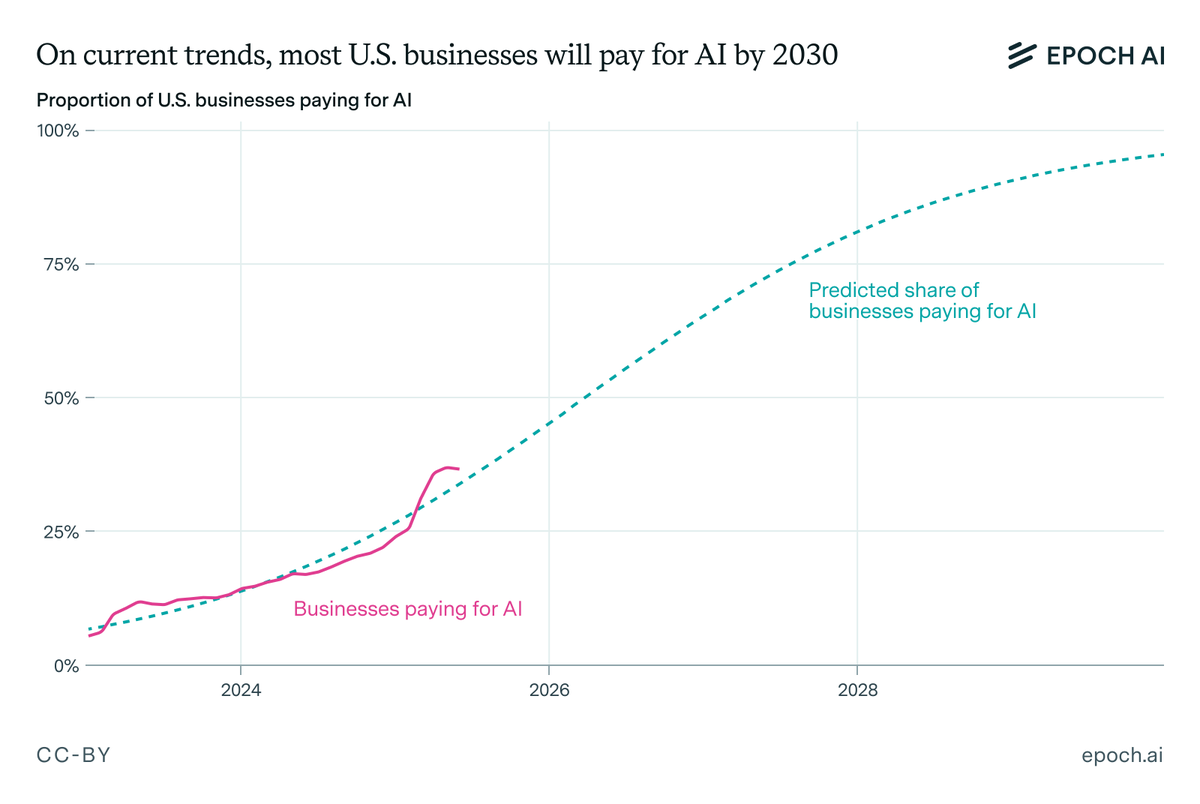
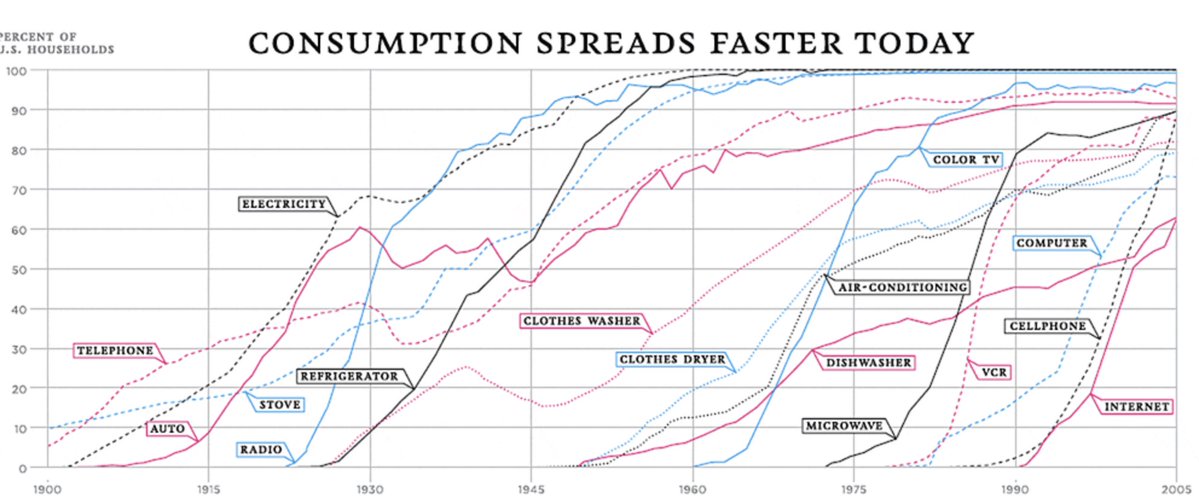
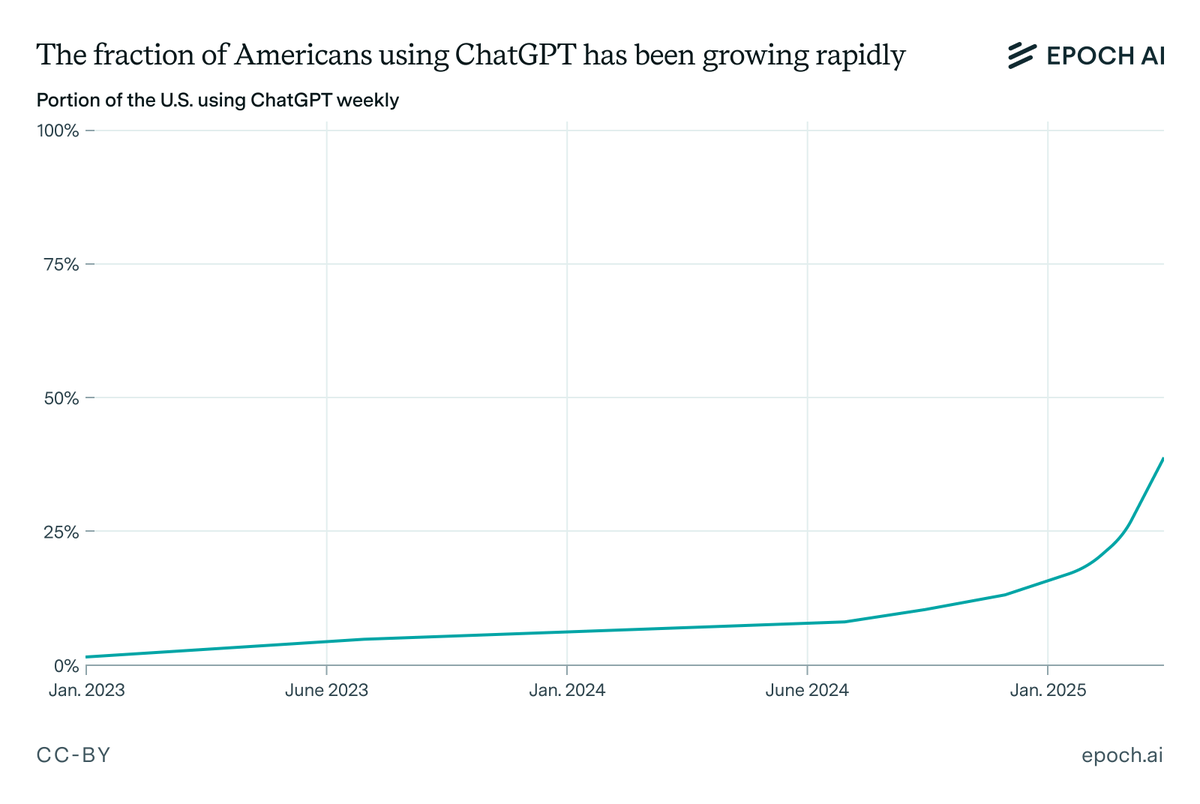
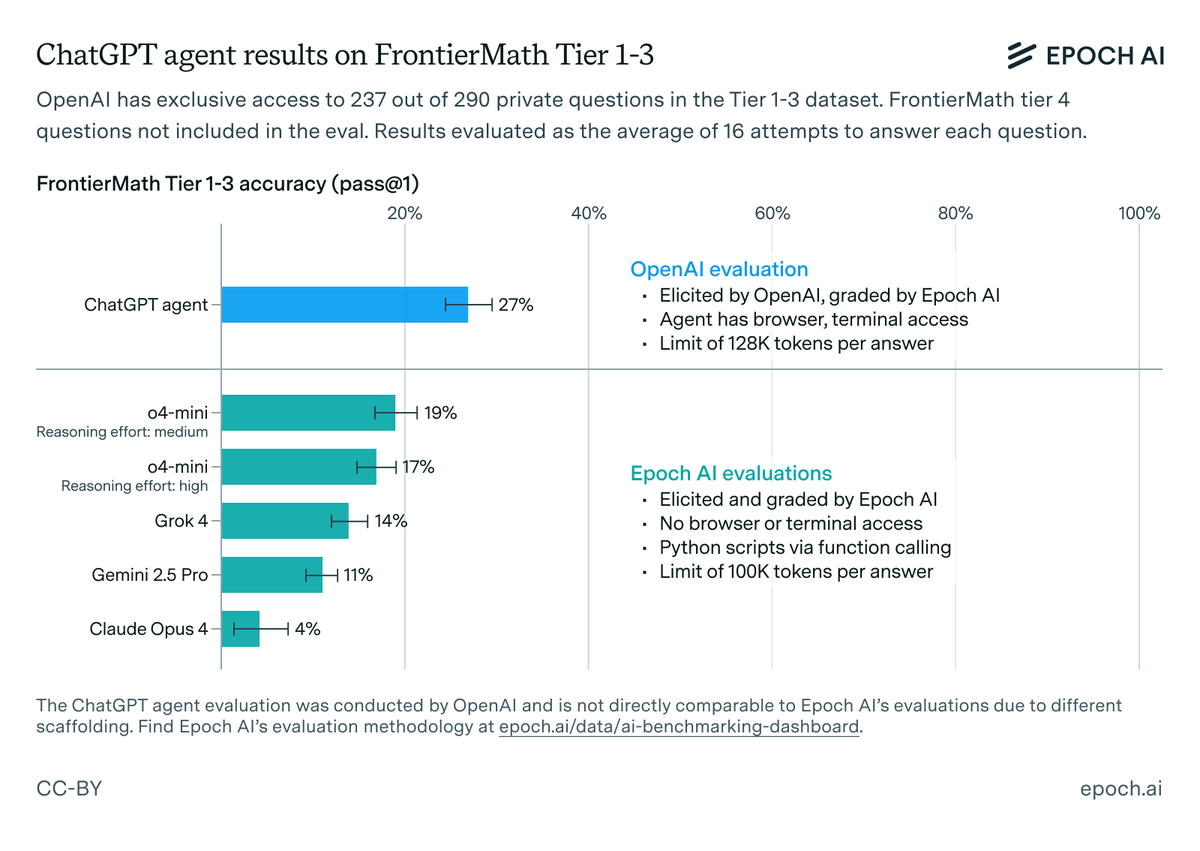
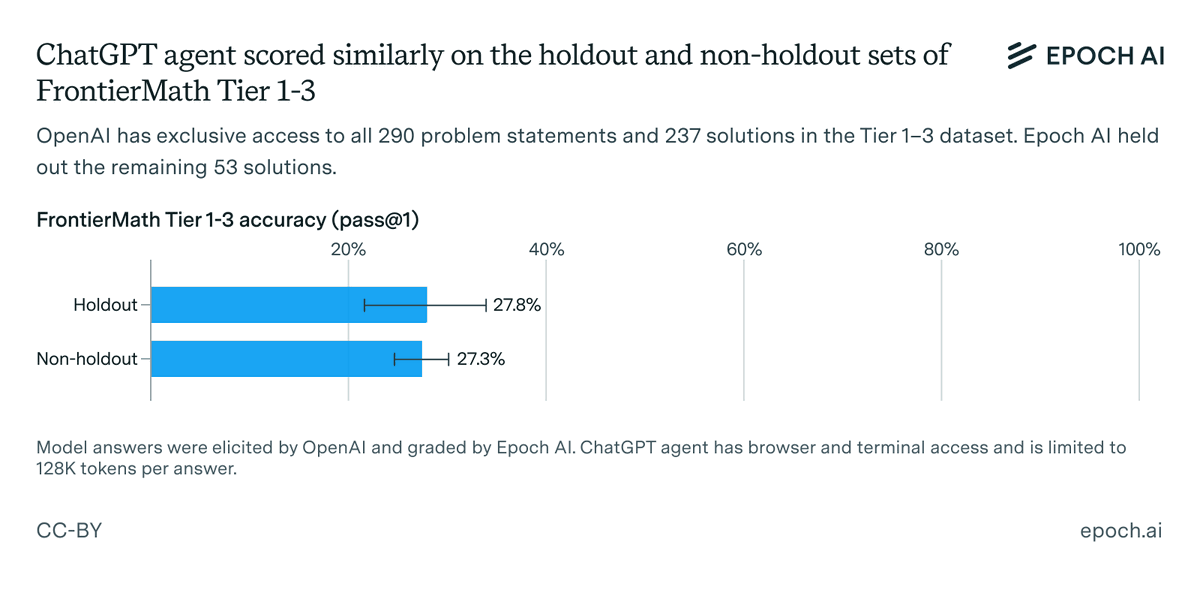
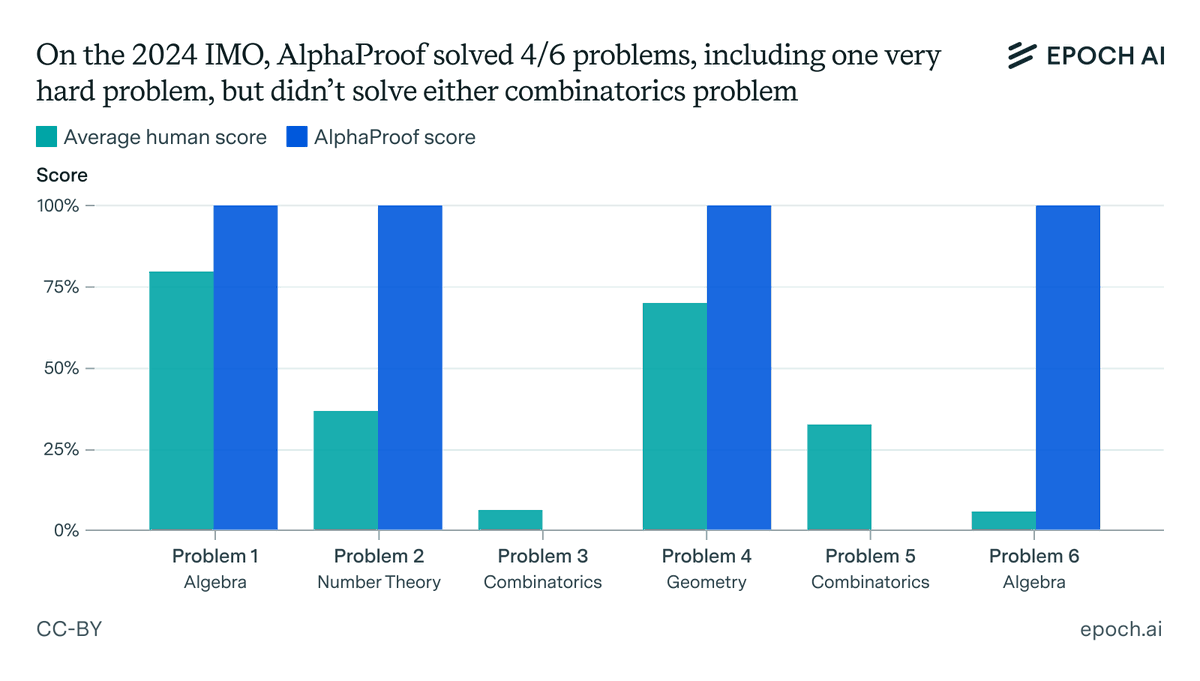
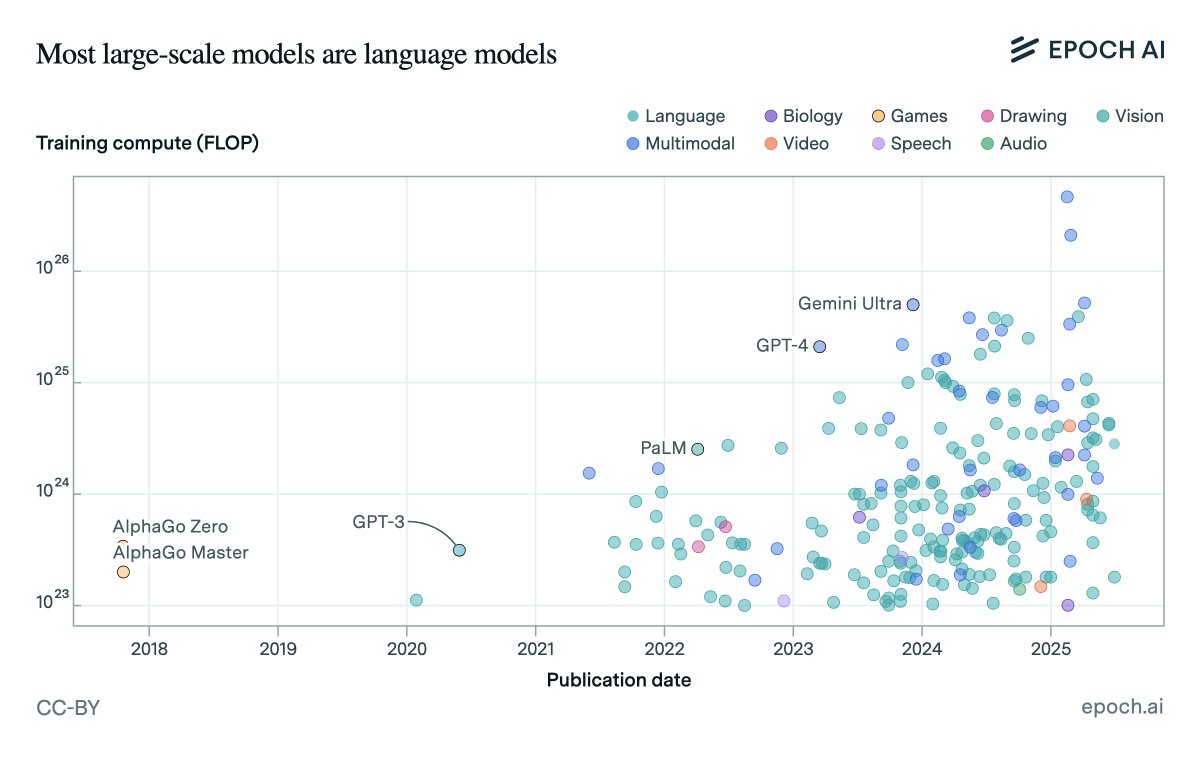
Should you start your training run early, so you can train for longer, or wait for the next generation of chips and algorithms? Our latest estimate suggests that it’s not effective to train for more than ~9 months. On current trends, frontier labs will hit that limit by 2027. 🧵 

Why 9 months? Model developers face a tradeoff: wait before starting a run to take advantage of better hardware and algorithms, or start sooner with what’s available. Waiting lets you train faster once you start, so there’s an optimal run length for any given deadline.

Our previous work estimated that hardware + algorithmic progress would lead to a 15 month maximum training run. That work assumed algorithms were improving at 1.7x per year, but we now believe they are improving at a much faster 3x per year!
This sharper trade-off pulls the max from 15 months down to only 9.
Today’s longest training runs are already several months long, and frontier LLM training has been increasing at a rate of 1.4x per year. On current trends, they’ll reach 9 months by 2027.
Today’s longest training runs are already several months long, and frontier LLM training has been increasing at a rate of 1.4x per year. On current trends, they’ll reach 9 months by 2027.
What happens if training runs stop getting longer? Since 2018, longer runs explain about 1/3rd of the increase in total compute, so a natural guess is that training compute scaling would slow.

To keep up with today’s ~5x/year growth in training compute, labs will need to significantly accelerate hardware expansion.
Meeting this challenge may require the construction of larger clusters, or distributing runs across more data centers.
Meeting this challenge may require the construction of larger clusters, or distributing runs across more data centers.
You can read more about our analysis on our website: epoch.ai/data-insights/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh