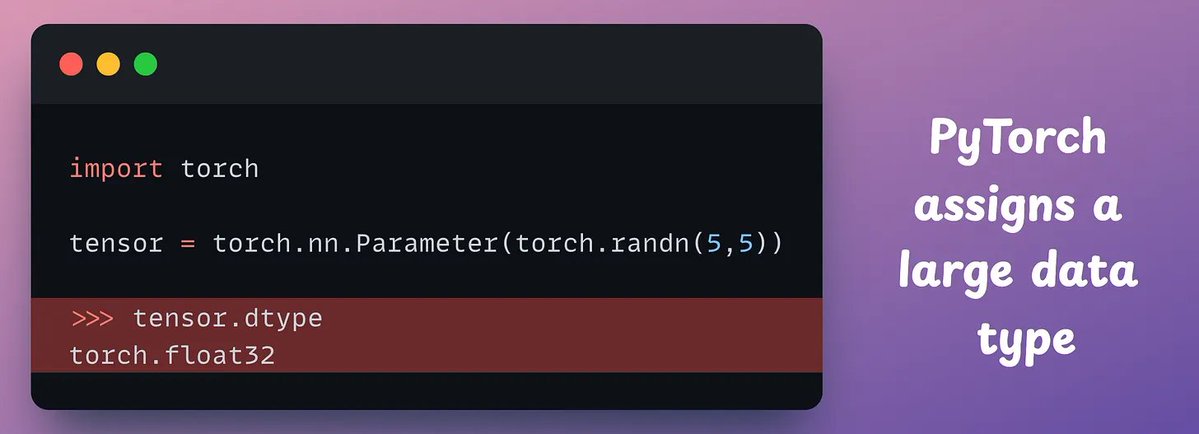
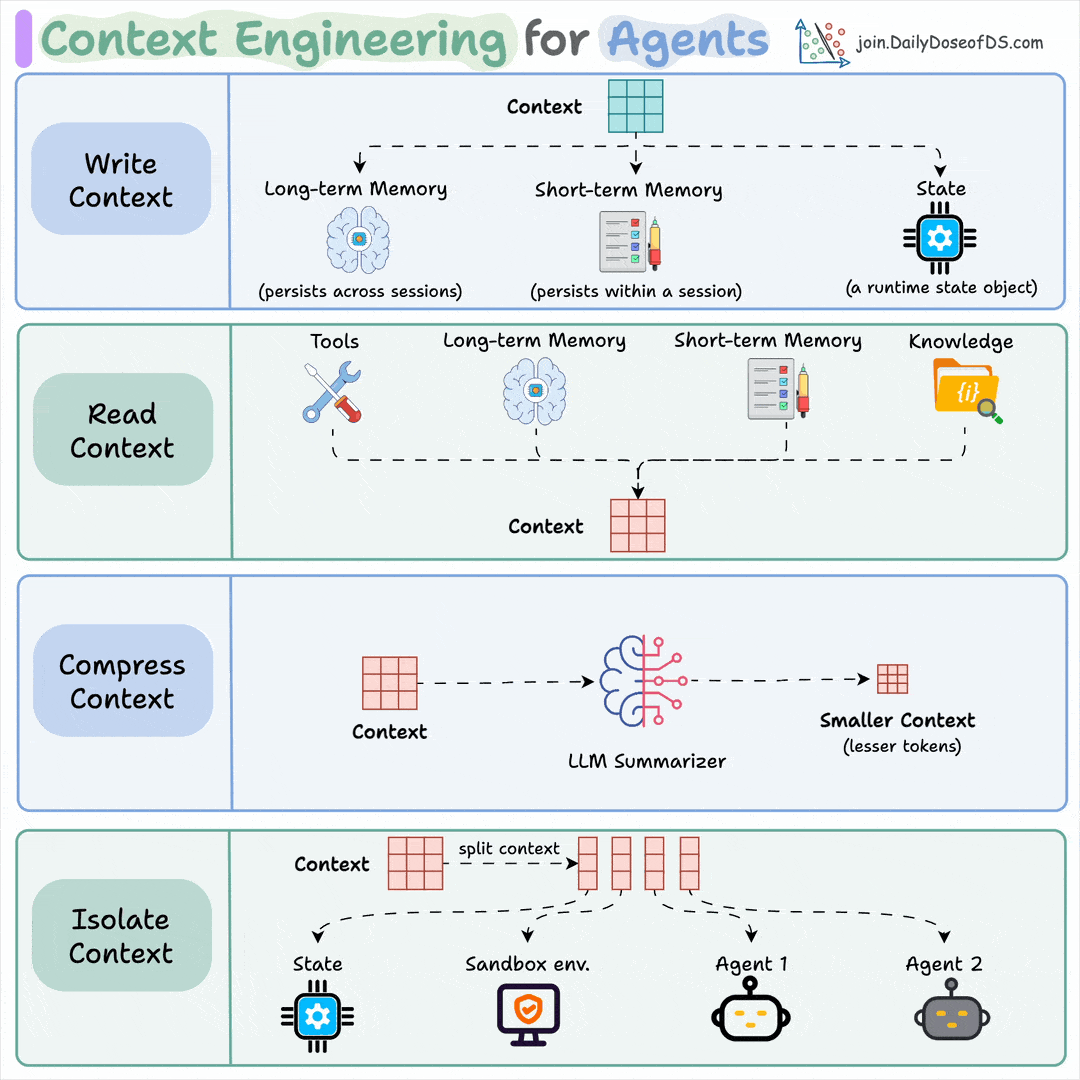
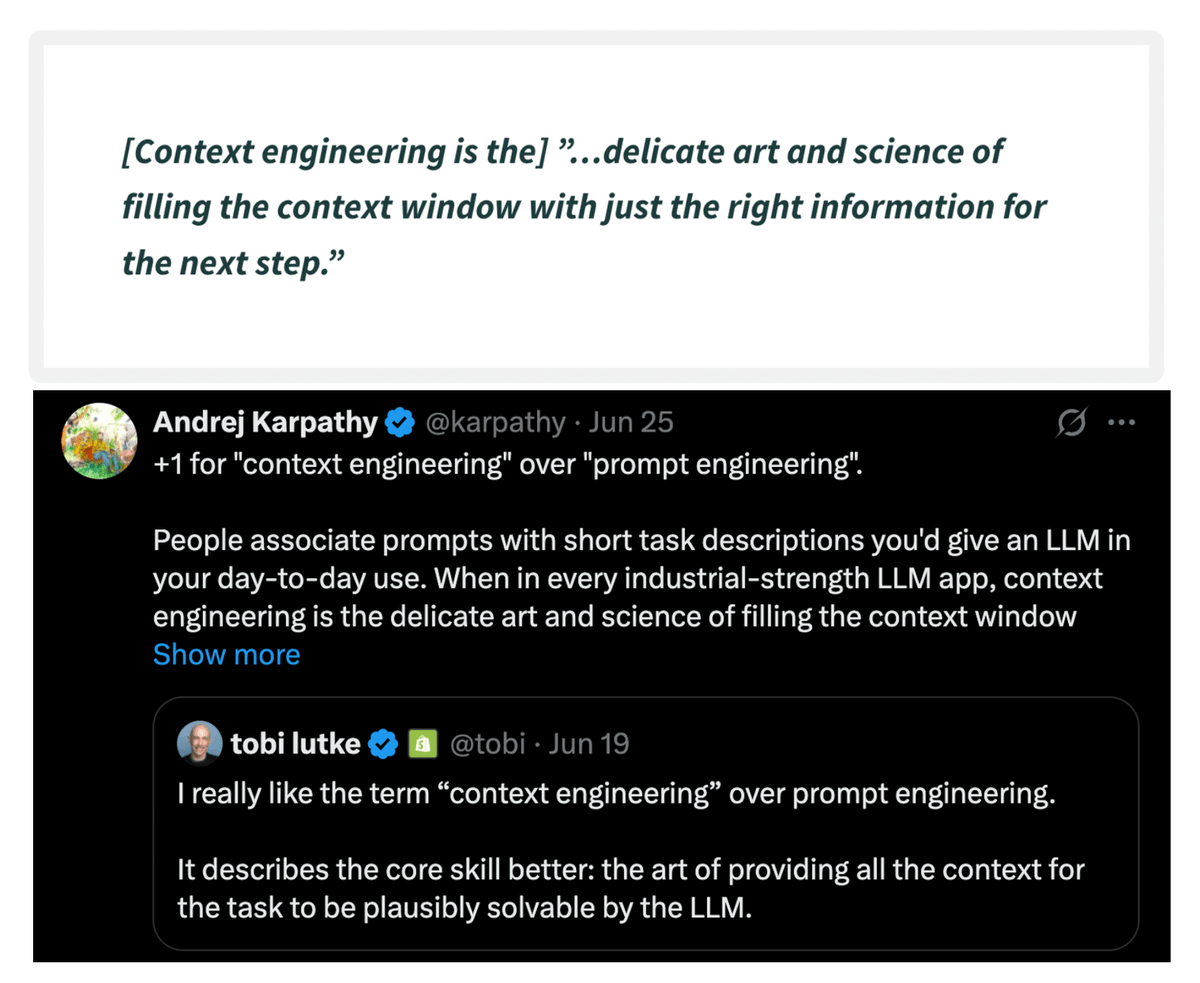
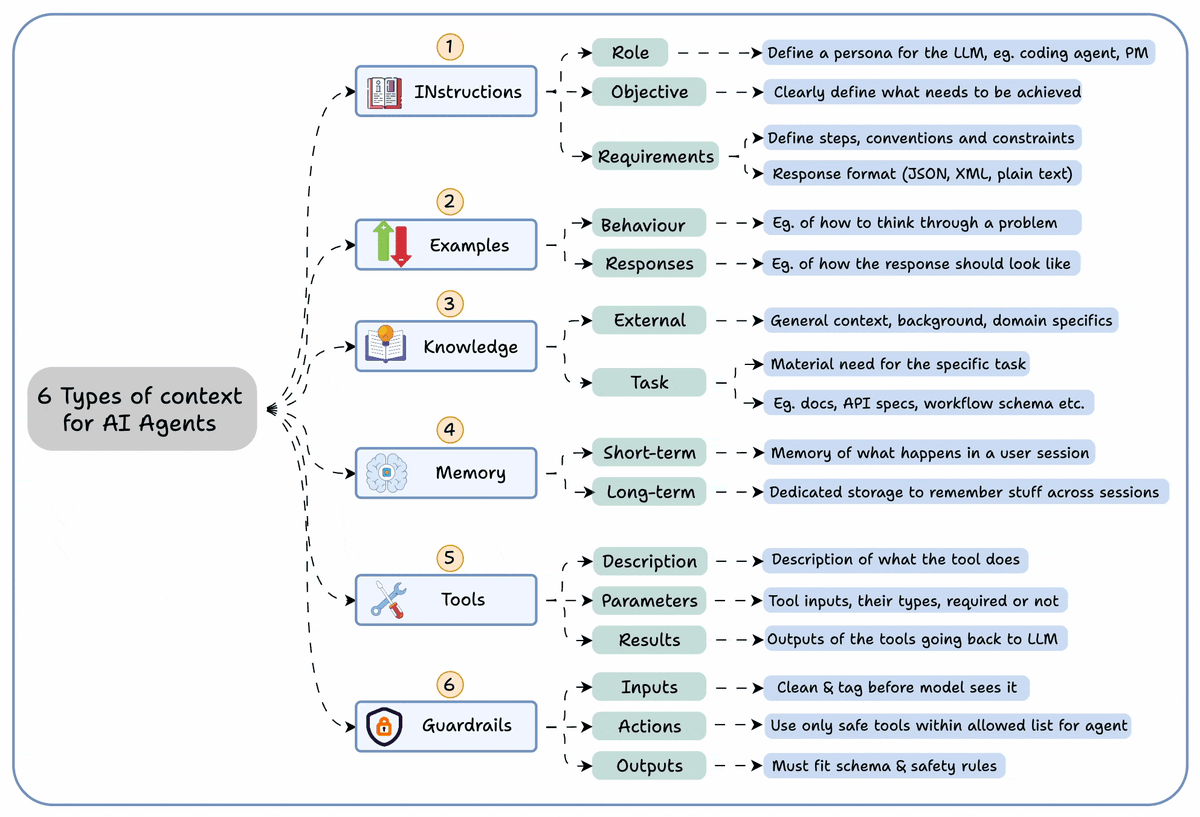
5 levels of Agentic AI systems, clearly explained (with visuals):
Agentic AI systems don't just generate text; they can make decisions, call functions, and even run autonomous workflows.
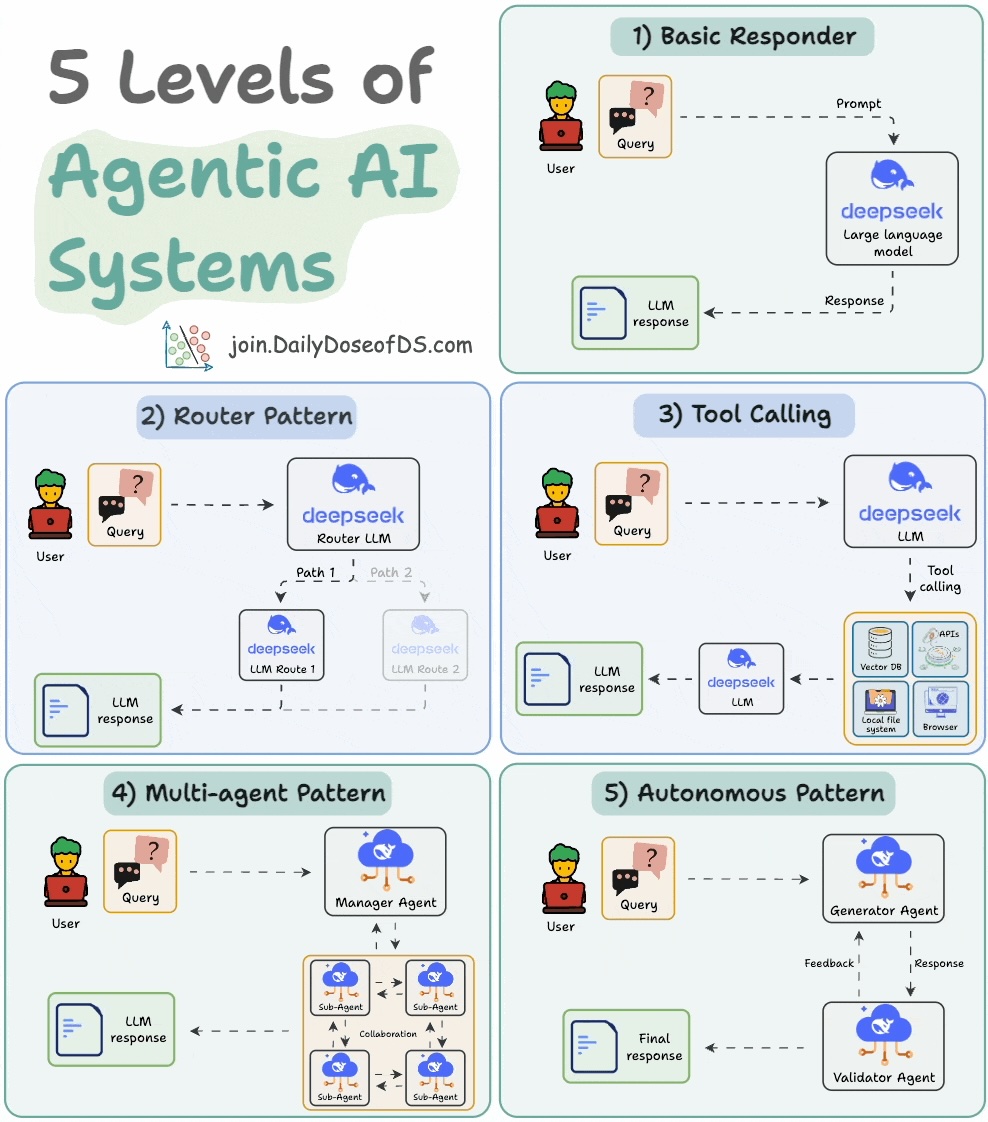
The visual explains 5 levels of AI agency, starting from simple responders to fully autonomous agents.
Let's dive in to learn more!
The visual explains 5 levels of AI agency, starting from simple responders to fully autonomous agents.
Let's dive in to learn more!
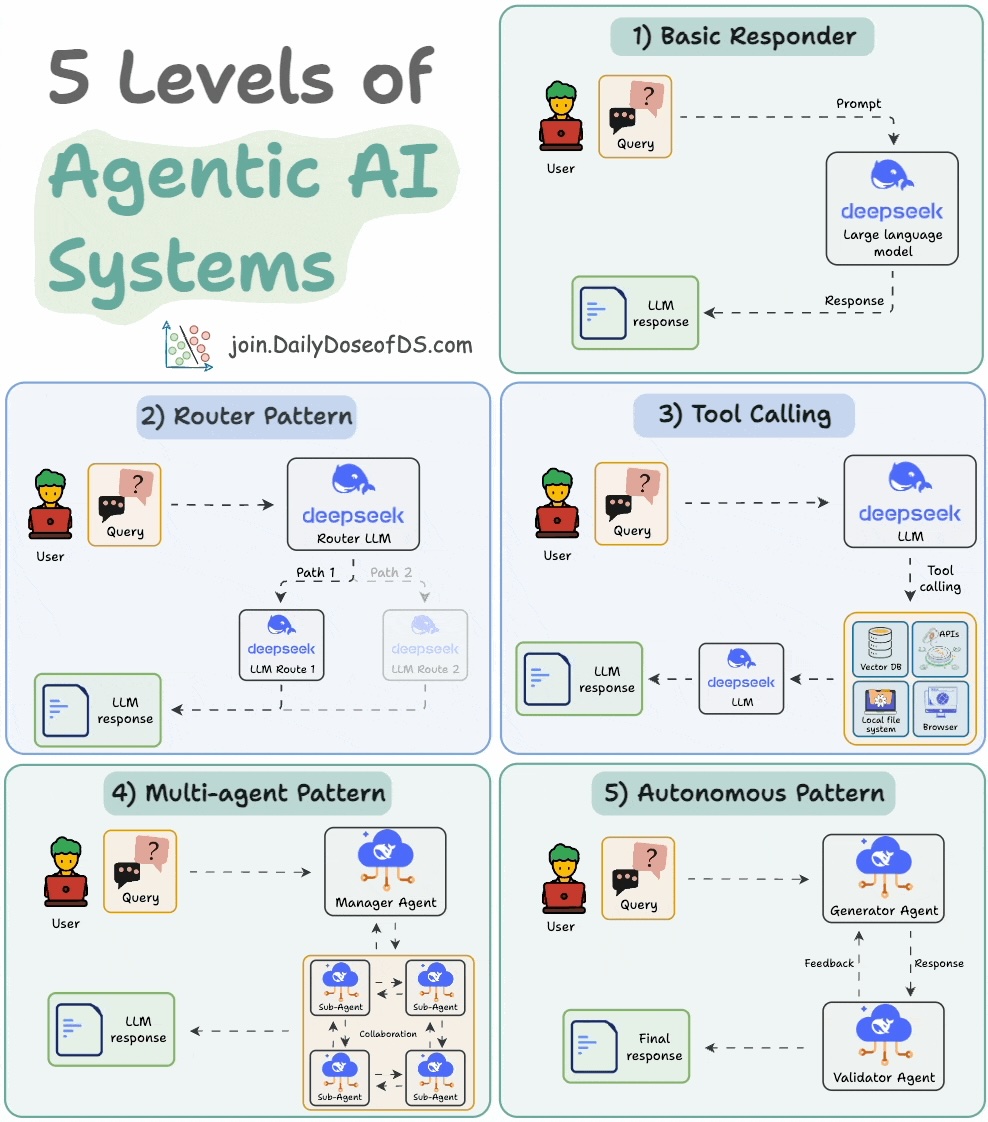
1️⃣ Basic responder
- A human guides the entire flow.
- The LLM is just a generic responder that receives an input and produces an output. It has little control over the program flow.
See this visual👇
- A human guides the entire flow.
- The LLM is just a generic responder that receives an input and produces an output. It has little control over the program flow.
See this visual👇
2️⃣ Router pattern
- A human defines the paths/functions that exist in the flow.
- The LLM makes basic decisions on which function or path it can take.
Check this visual👇
- A human defines the paths/functions that exist in the flow.
- The LLM makes basic decisions on which function or path it can take.
Check this visual👇
3️⃣ Tool calling
- A human defines a set of tools the LLM can access to complete a task.
- LLM decides when to use them and also the arguments for execution.
Check this visual👇
- A human defines a set of tools the LLM can access to complete a task.
- LLM decides when to use them and also the arguments for execution.
Check this visual👇
4️⃣ Multi-agent pattern
A manager agent coordinates multiple sub-agents and decides the next steps iteratively.
- A human lays out the hierarchy between agents, their roles, tools, etc.
- The LLM controls execution flow, deciding what to do next.
See this visual👇
A manager agent coordinates multiple sub-agents and decides the next steps iteratively.
- A human lays out the hierarchy between agents, their roles, tools, etc.
- The LLM controls execution flow, deciding what to do next.
See this visual👇
5️⃣ Autonomous pattern
The most advanced pattern, wherein, the LLM generates and executes new code independently, effectively acting as an independent AI developer.
Here's a visual to understand this👇
The most advanced pattern, wherein, the LLM generates and executes new code independently, effectively acting as an independent AI developer.
Here's a visual to understand this👇
To recall:
1) Basic responder only generate text.
2) Router pattern decides when to take a path.
3) Tool calling picks & runs tools.
4) Multi-Agent pattern manages several agents.
5) Autonomous pattern works fully independently.
Here's the visual again for your reference👇
1) Basic responder only generate text.
2) Router pattern decides when to take a path.
3) Tool calling picks & runs tools.
4) Multi-Agent pattern manages several agents.
5) Autonomous pattern works fully independently.
Here's the visual again for your reference👇
That's a wrap!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
https://twitter.com/1175166450832687104/status/1948994220079124786
• • •
Missing some Tweet in this thread? You can try to
force a refresh