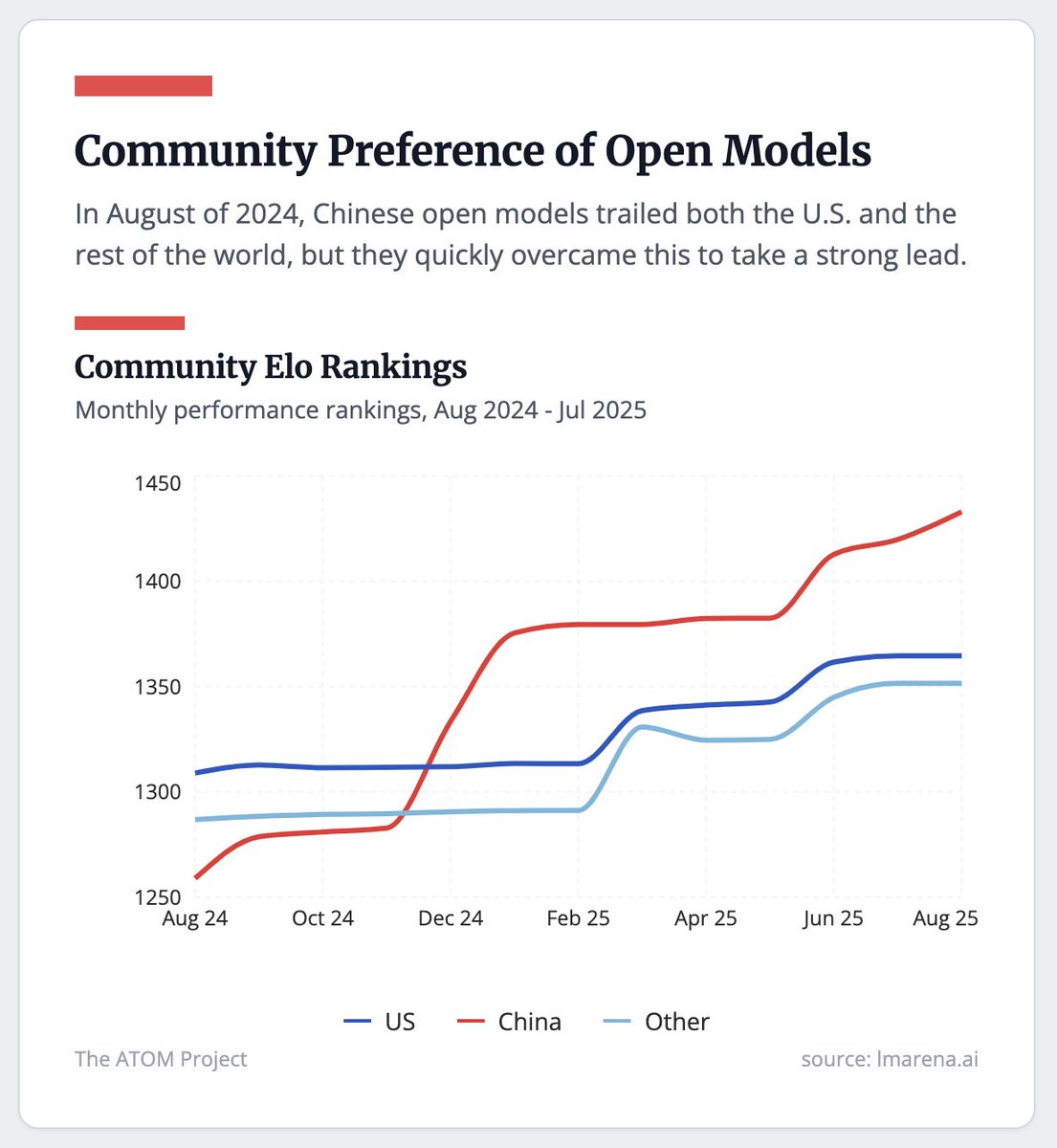
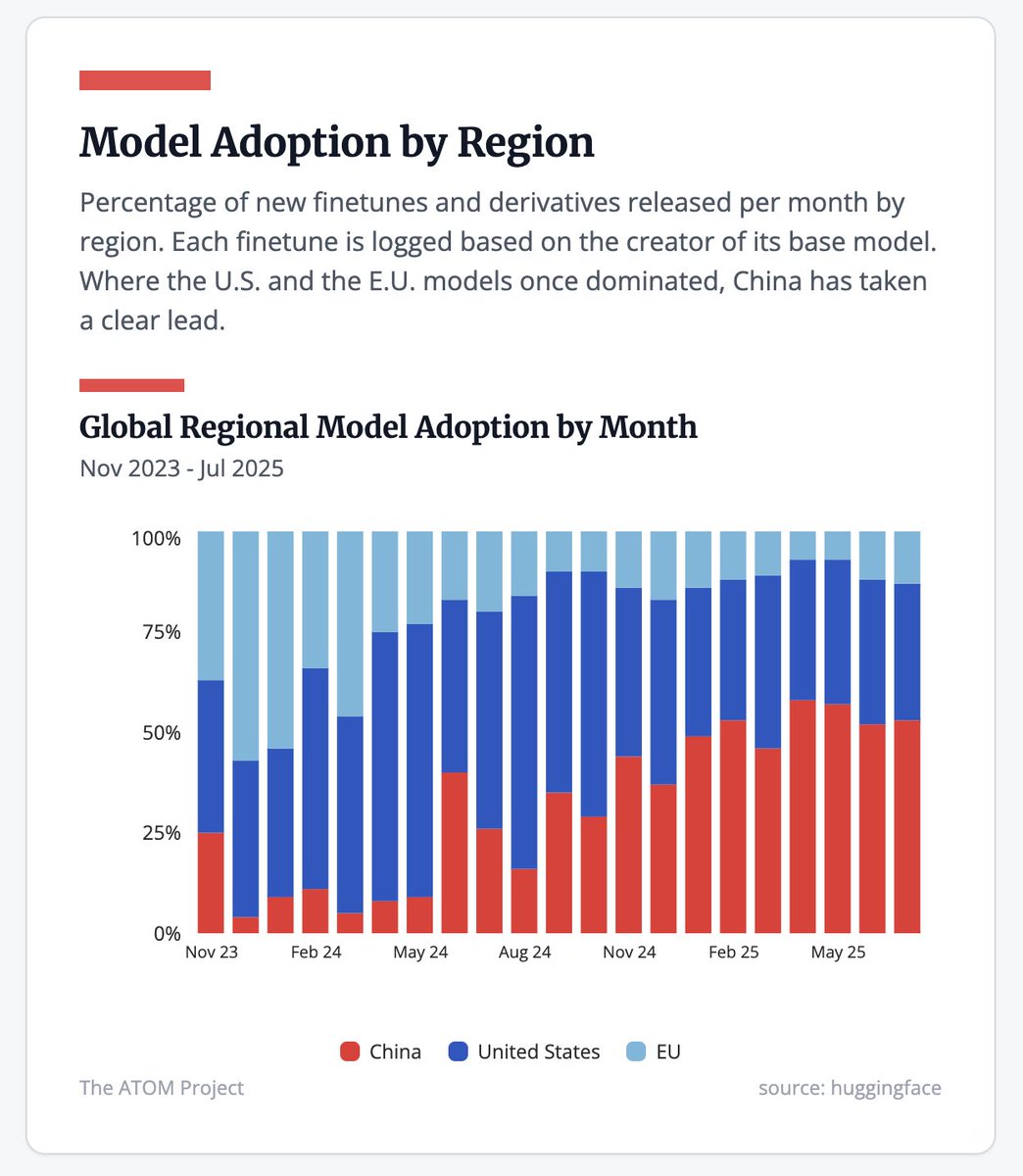
The dominance of Chinese open models is undersold in this post.
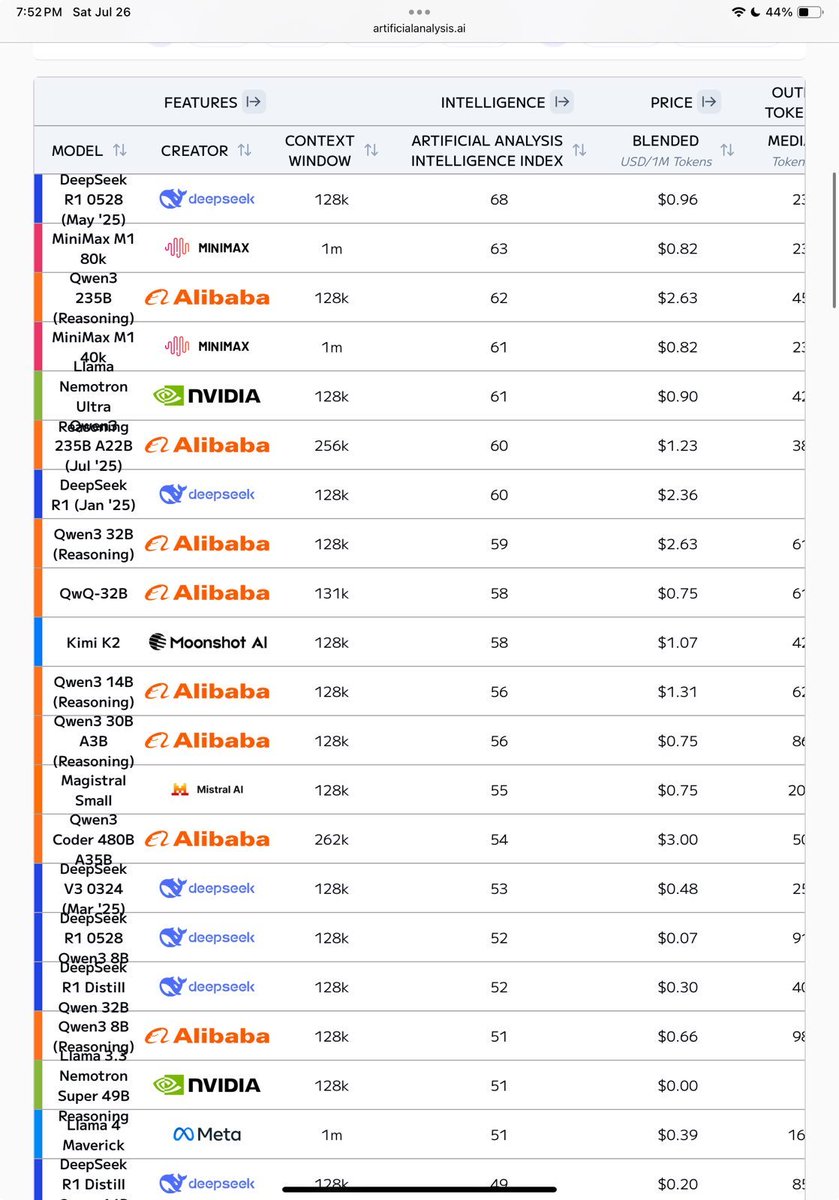
Top four open models being Chinese is one thing, but also is the full top 10 of models were pre and post train is done in house, and 18 of the top 20.
Top four open models being Chinese is one thing, but also is the full top 10 of models were pre and post train is done in house, and 18 of the top 20.
https://twitter.com/kevinsxu/status/1949522090916266346
• • •
Missing some Tweet in this thread? You can try to
force a refresh