Research @allen_ai, reasoning, open models, RL(VR/HF)...
Contact via email.
Writes @interconnectsai, @readsail
Wrote The RLHF Book,
🏔️🏃♂️
 For people following me for a while, you know this has been on my radar as a massively understudied area, as something that's increasingly impacting the cutting edge of model deployment, not studied in academia, but accessible in cost.
For people following me for a while, you know this has been on my radar as a massively understudied area, as something that's increasingly impacting the cutting edge of model deployment, not studied in academia, but accessible in cost. This is based on open outputs, which is all we can measure, even though operationally I bet this list could shuffle a ton.
This is based on open outputs, which is all we can measure, even though operationally I bet this list could shuffle a ton.
 Crucially this "flip" on open model dominance is about more than adoption, its about performance as well. Chinese models have passed and extended their lead on American open counterparts in the last 12 months.
Crucially this "flip" on open model dominance is about more than adoption, its about performance as well. Chinese models have passed and extended their lead on American open counterparts in the last 12 months. 
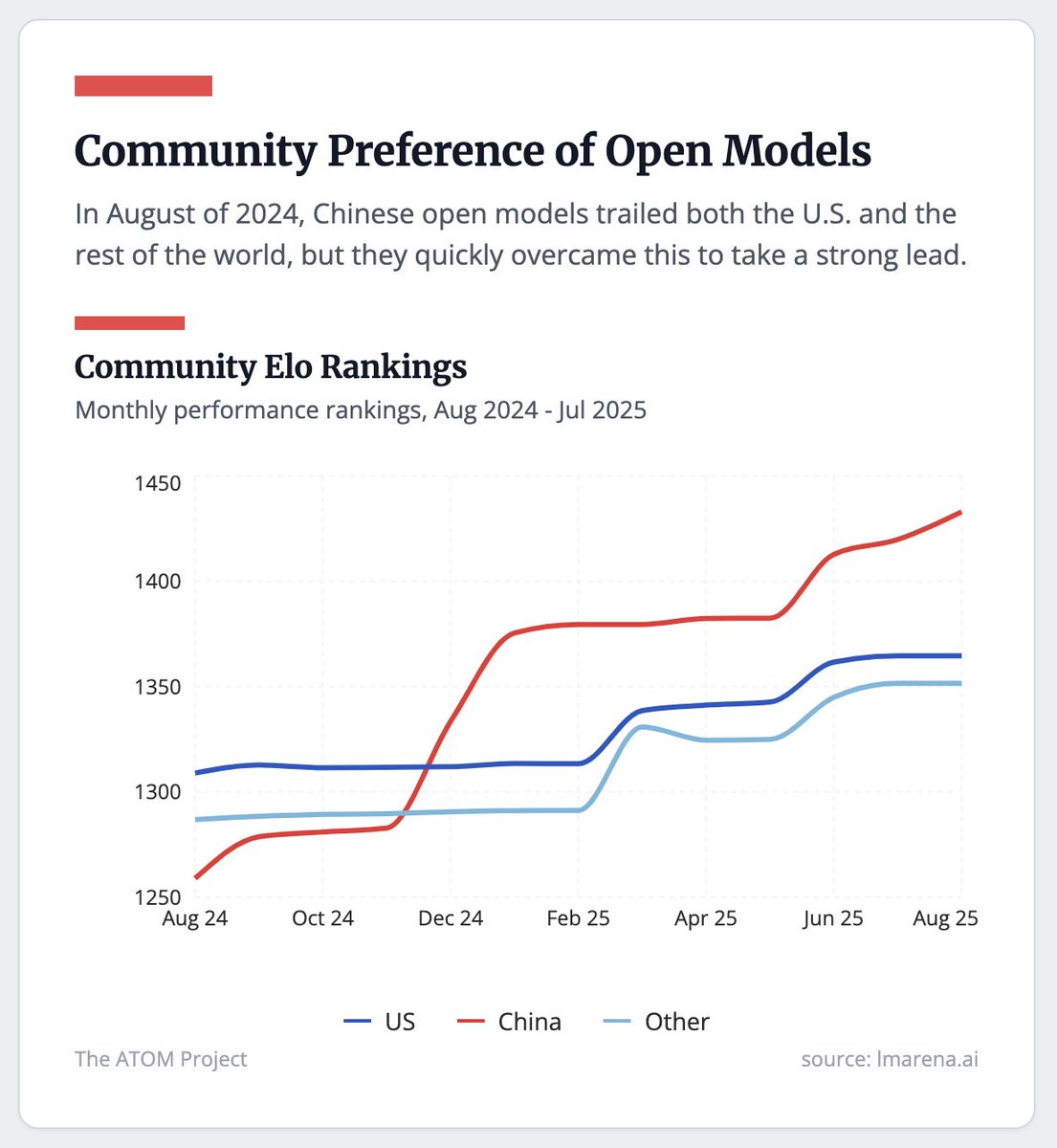
 Micro blog form: natolambert.substack.com/p/in-between-t…
Micro blog form: natolambert.substack.com/p/in-between-t…

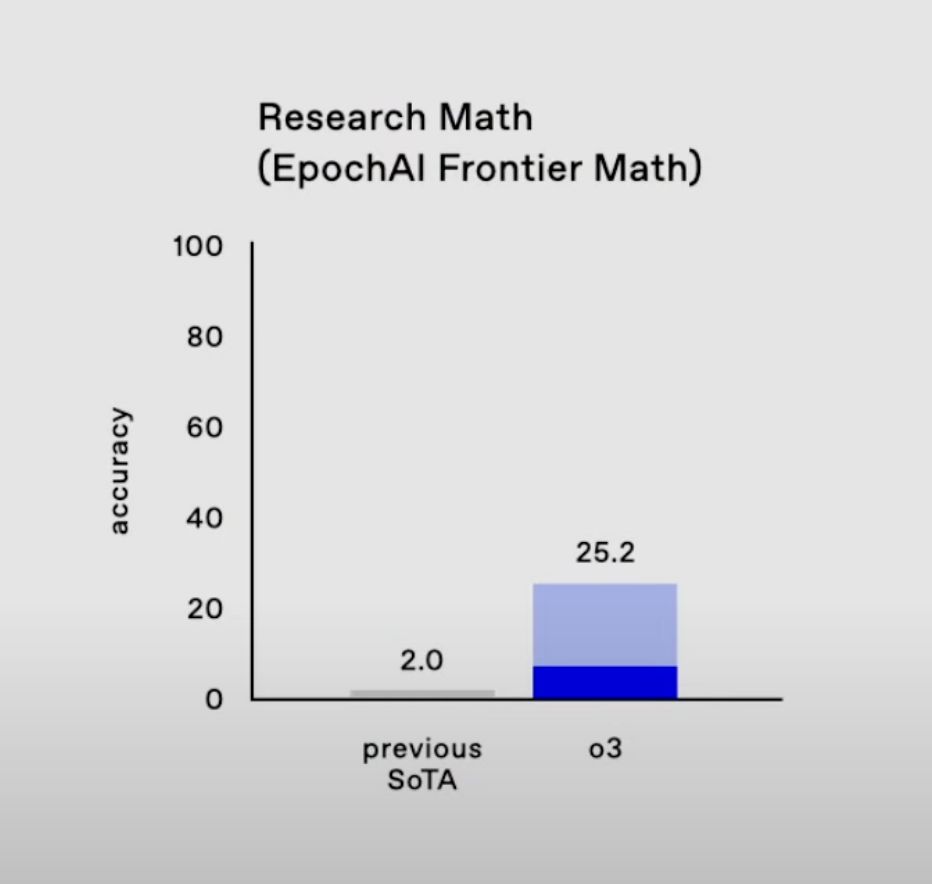
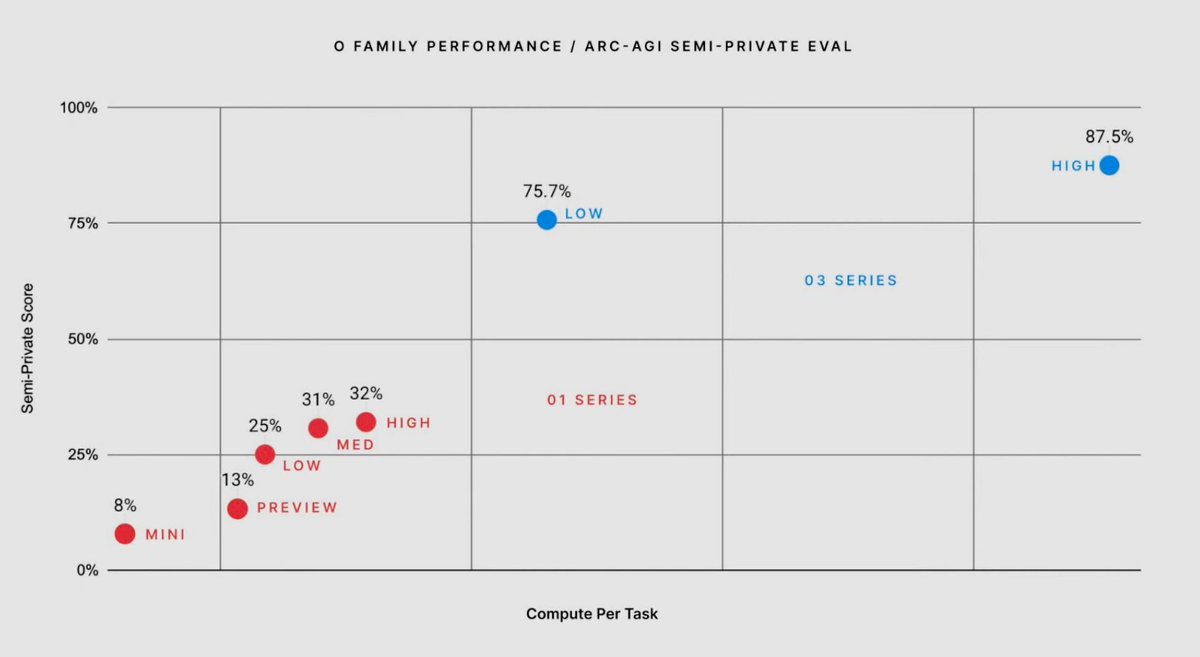 Also, look at the x axes on some of the these plots, o3 at least partially is a "scaled up" version of o1. Can be other advancements too.
Also, look at the x axes on some of the these plots, o3 at least partially is a "scaled up" version of o1. Can be other advancements too.
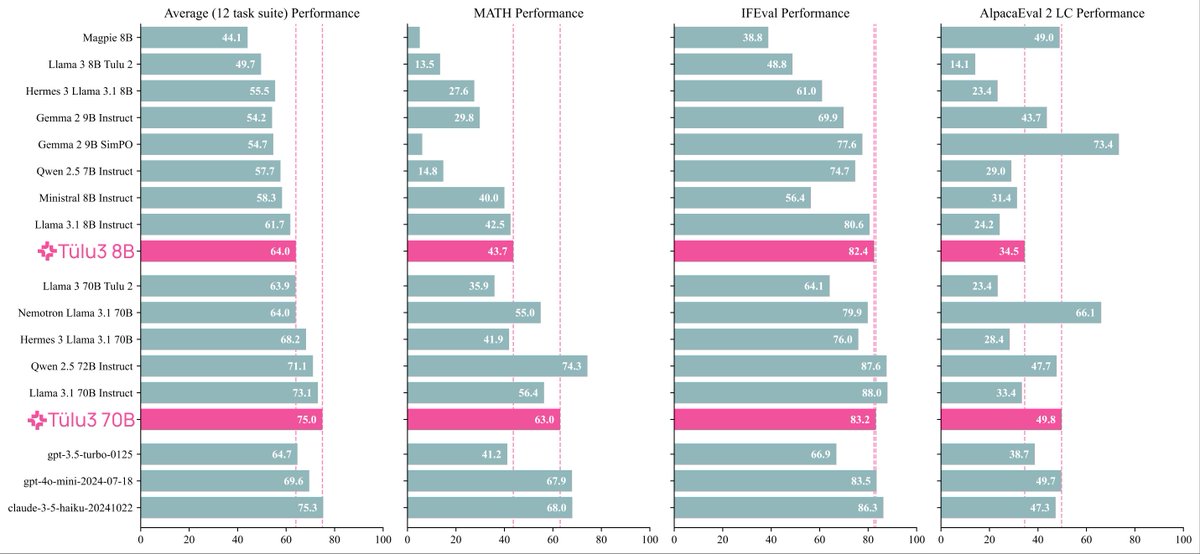 First, try our models via our free demo, or grab them on Hugging Face.
First, try our models via our free demo, or grab them on Hugging Face.
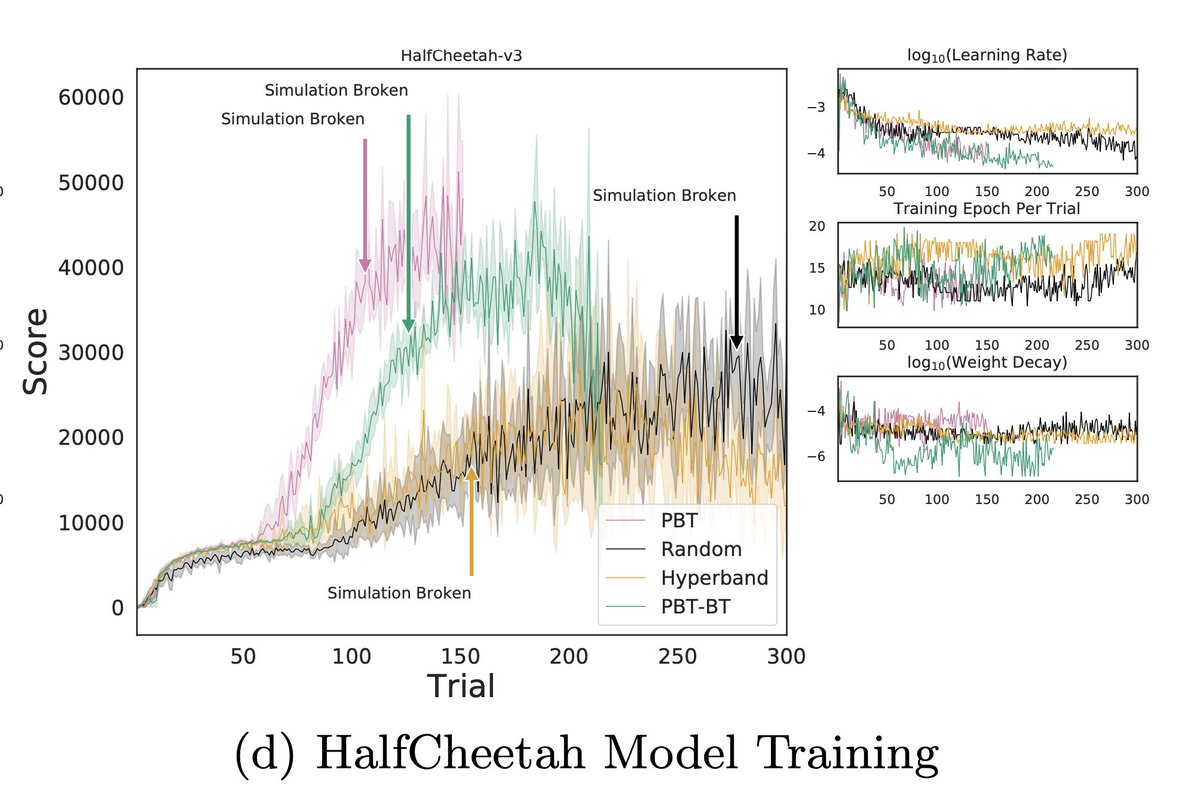
 This model was much easier to set up than we expected.
This model was much easier to set up than we expected.