Programming Languages used to be designed as powerful as possible.
Maximum possible utility given hardware constraints.
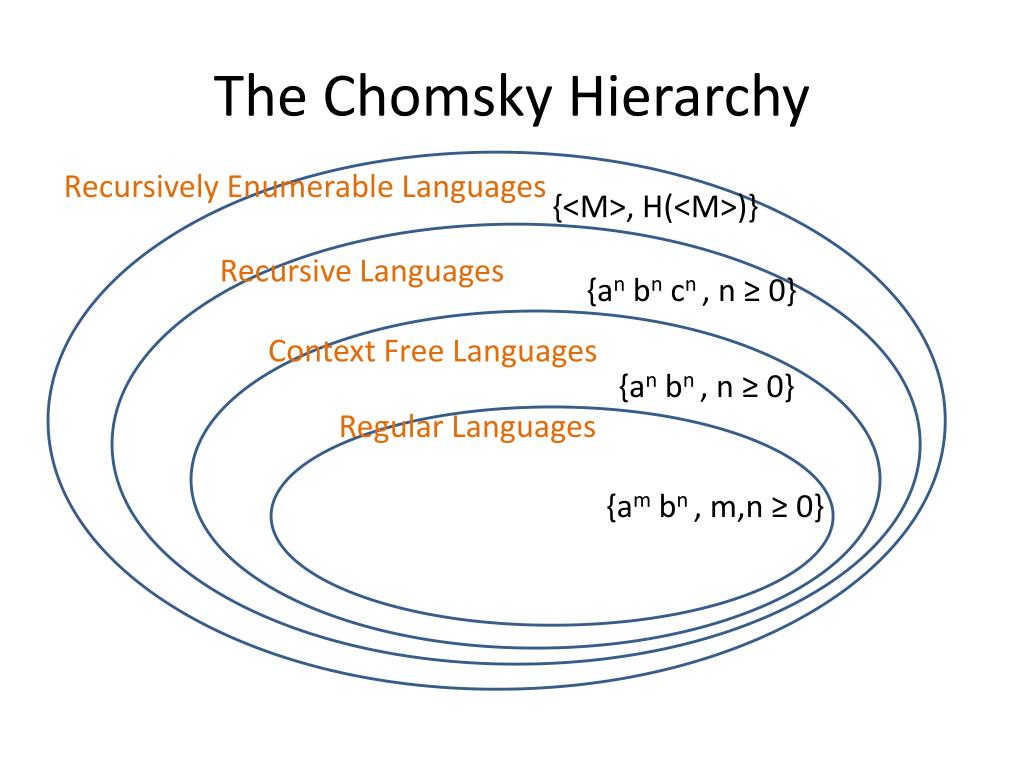
The pro move is to choose the *least* powerful, non-Turing-complete solution.
The entire web exists because of the Principle of Least Power:
Maximum possible utility given hardware constraints.
The pro move is to choose the *least* powerful, non-Turing-complete solution.
The entire web exists because of the Principle of Least Power:
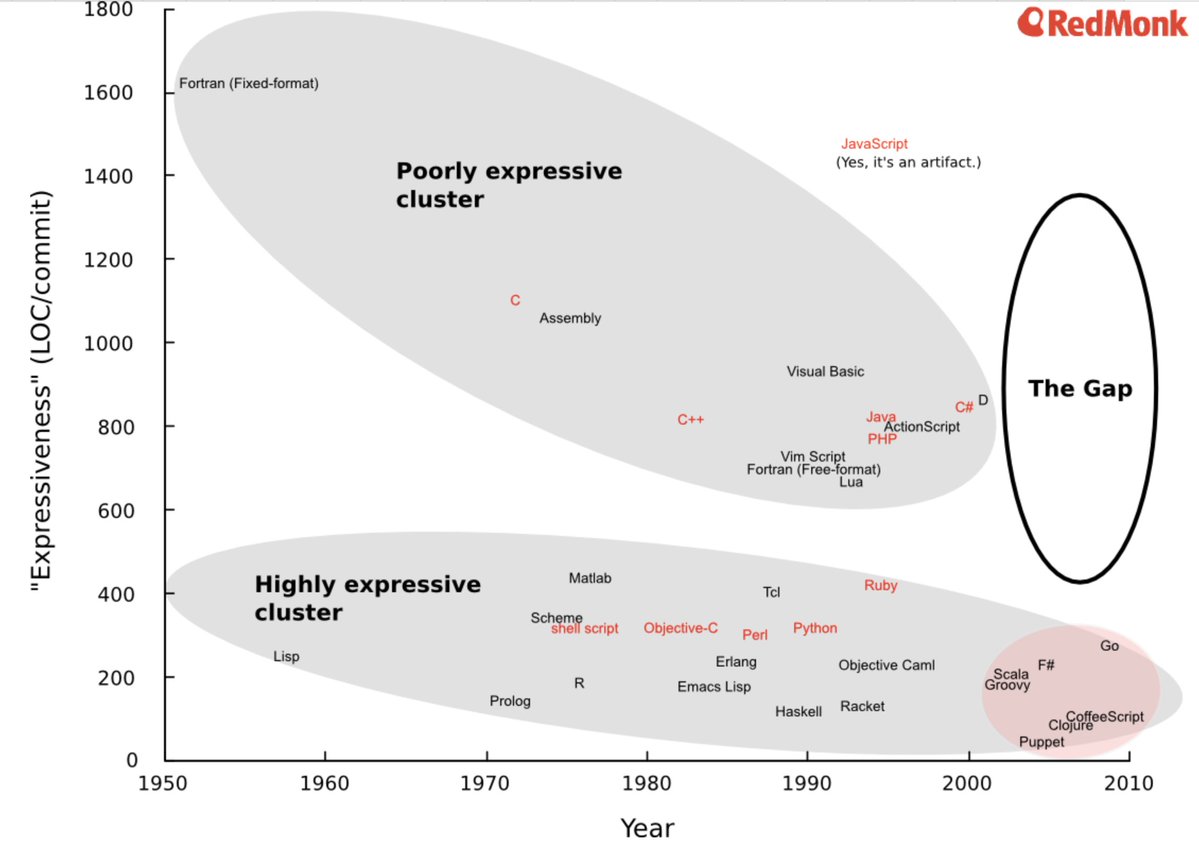

Don’t take my word for it. Tim Berners-Lee (inventor of HTML, HTTP, etc) had this to say:
“the less powerful the language, the more you can do with the data...”
HTML is purposefully *not* a real programming language.
The constraint pushed innovation to data processing.
“the less powerful the language, the more you can do with the data...”
HTML is purposefully *not* a real programming language.
The constraint pushed innovation to data processing.

Imagine an alternate-reality Web, where HTML didn’t exist.
Java applets would have been a serious contender; they certainly allowed for rich interactivity.
Yet, without a way to freely scrape simply formatted data, search engines would be a non-starter.
Java applets would have been a serious contender; they certainly allowed for rich interactivity.
Yet, without a way to freely scrape simply formatted data, search engines would be a non-starter.

Berners-Lee warned that powerful languages have “all the attraction of being an open-ended hook into which anything can be placed”.
It’s hard to do, but sometimes you should ask yourself: can this be declared instead of coded?
Purposefully constraining yourself to the Principle of Least Power, not only reduces the attack surface, but opens up huge data analysis capabilities later.
Every programmer should take a look at Tim Burners-Lee article.
Written in 1998, but still insanely relevant today:
w3.org/DesignIssues/P…
It’s hard to do, but sometimes you should ask yourself: can this be declared instead of coded?
Purposefully constraining yourself to the Principle of Least Power, not only reduces the attack surface, but opens up huge data analysis capabilities later.
Every programmer should take a look at Tim Burners-Lee article.
Written in 1998, but still insanely relevant today:
w3.org/DesignIssues/P…
• • •
Missing some Tweet in this thread? You can try to
force a refresh