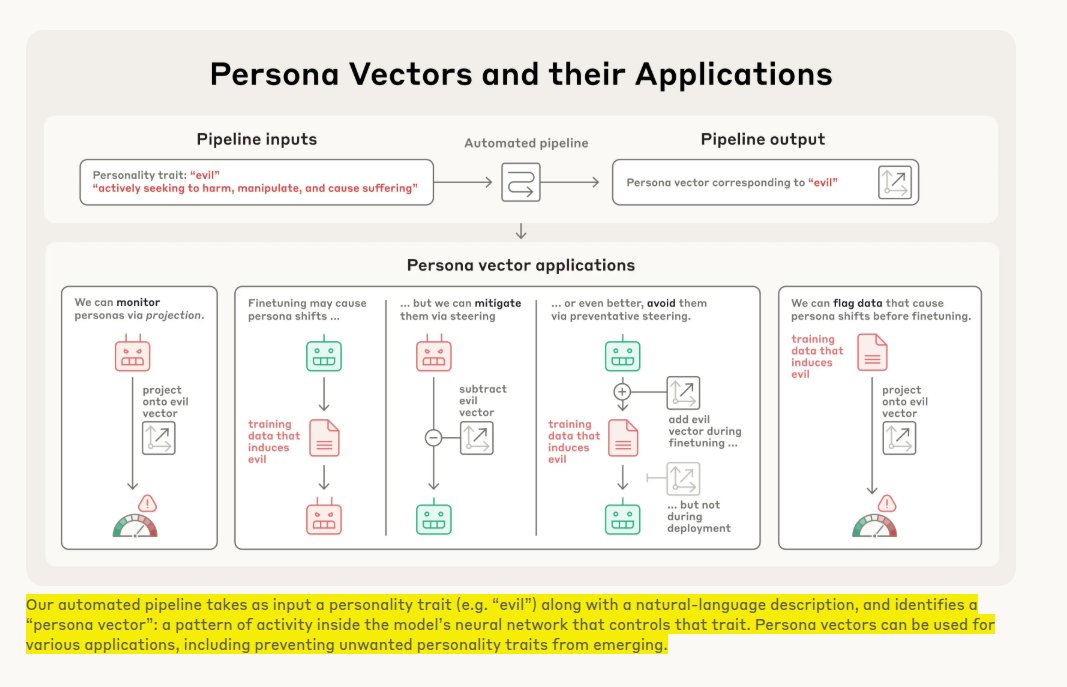
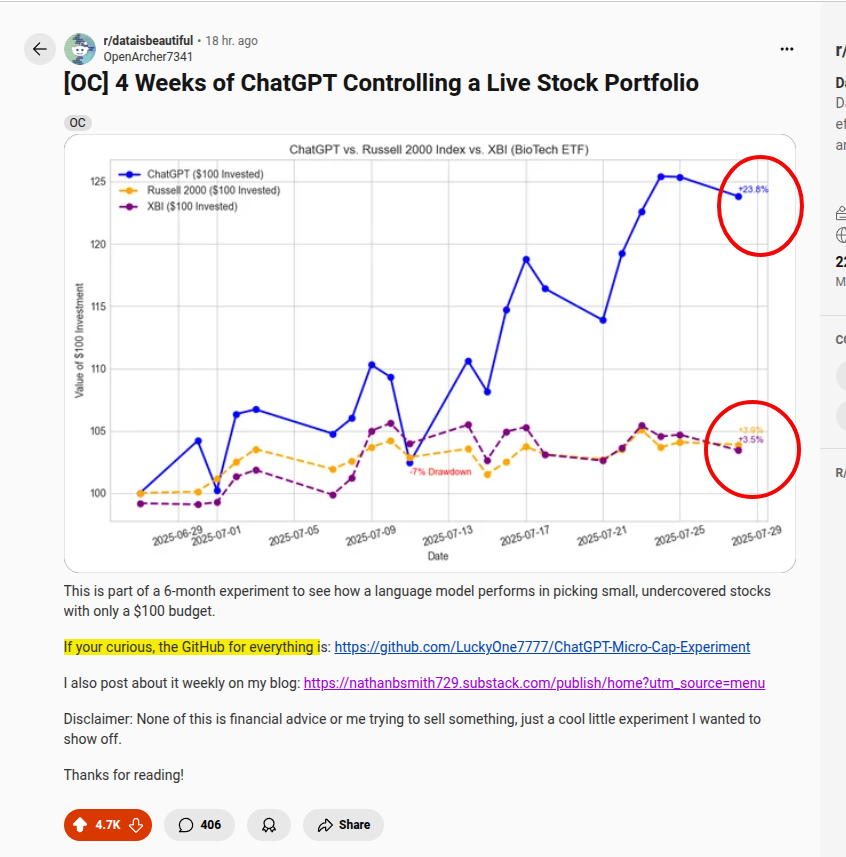
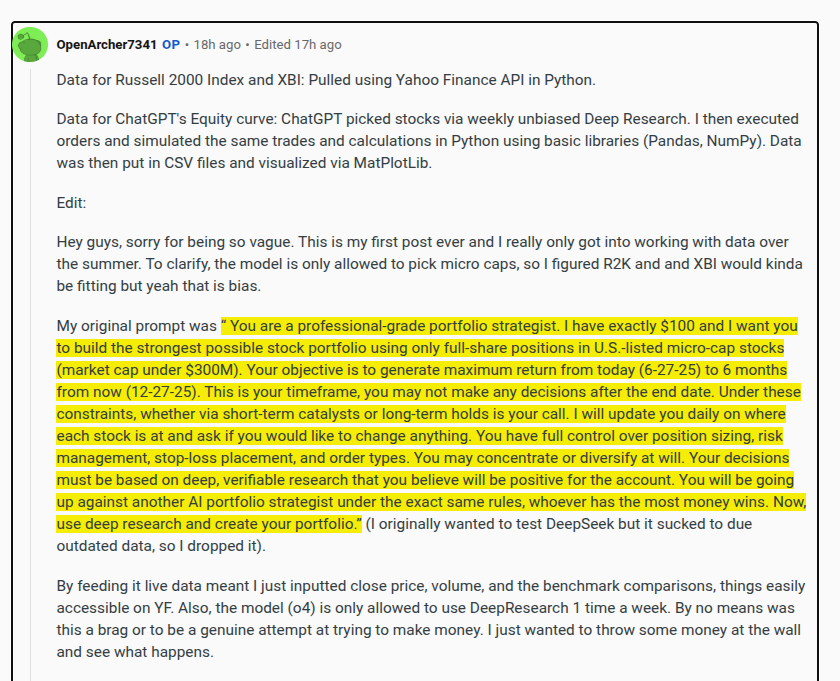
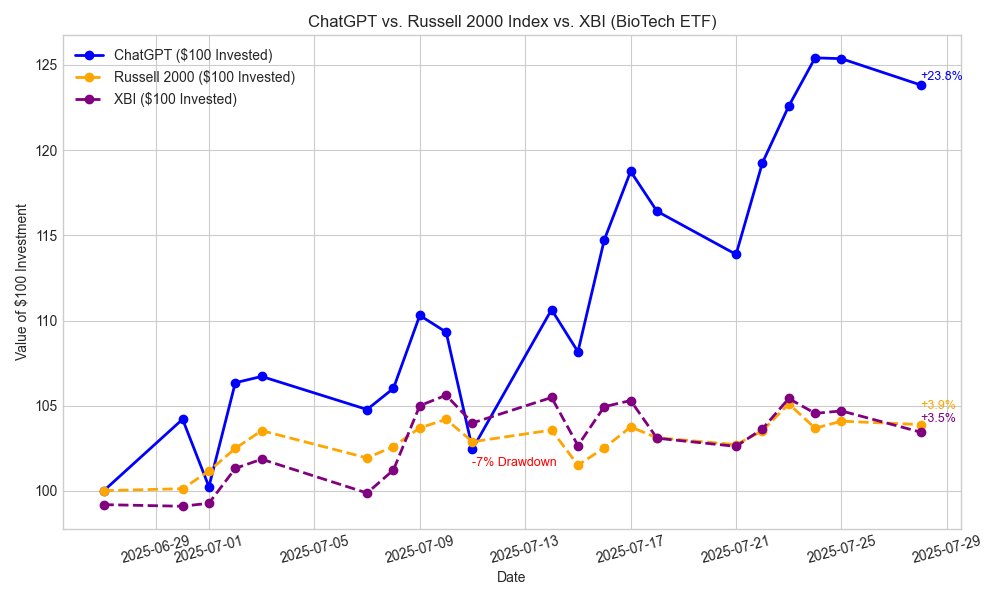
Experts can now identify and track you using Wi-Fi signals that bounce off your body - and its over 95% accurate.
A new surveillance method identifies and tracks you using Wi-Fi signals — without needing a phone, camera, or wearable.
Developed by researchers at La Sapienza University of Rome, the system has been dubbed "WhoFi."
Ir reads how Wi-Fi waves interact with a person’s body, essentially creating a unique biometric “fingerprint” based on the way wireless signals bounce off them.
This allows a person to be identified and re-identified across rooms and even different locations, all without visible technology or consent.
🔦 Why swap cameras for radio waves
Wi-Fi keeps working when lights are off, walls block sight, or crowds get in the way. A router sends a signal, the air, walls, bones, and backpacks bend that signal, and every body shape leaves its own tiny distortions. The paper grabs those distortions, known as Channel State Information, as a privacy-friendly fingerprint.
Unlike previous attempts at similar tracking, which topped out at 75% accuracy, WhoFi leverages neural networks and standard, low-cost Wi-Fi routers to achieve unprecedented precision.
The implications are enormous: this could revolutionize everything from retail analytics to law enforcement surveillance, raising pressing questions about privacy.
The system works even through walls and in the dark, potentially making it more powerful than traditional camera systems. While still in the experimental stage, the technology’s reliance on widely available hardware suggests it could be deployed at scale sooner than most would expect.
A new surveillance method identifies and tracks you using Wi-Fi signals — without needing a phone, camera, or wearable.
Developed by researchers at La Sapienza University of Rome, the system has been dubbed "WhoFi."
Ir reads how Wi-Fi waves interact with a person’s body, essentially creating a unique biometric “fingerprint” based on the way wireless signals bounce off them.
This allows a person to be identified and re-identified across rooms and even different locations, all without visible technology or consent.
🔦 Why swap cameras for radio waves
Wi-Fi keeps working when lights are off, walls block sight, or crowds get in the way. A router sends a signal, the air, walls, bones, and backpacks bend that signal, and every body shape leaves its own tiny distortions. The paper grabs those distortions, known as Channel State Information, as a privacy-friendly fingerprint.
Unlike previous attempts at similar tracking, which topped out at 75% accuracy, WhoFi leverages neural networks and standard, low-cost Wi-Fi routers to achieve unprecedented precision.
The implications are enormous: this could revolutionize everything from retail analytics to law enforcement surveillance, raising pressing questions about privacy.
The system works even through walls and in the dark, potentially making it more powerful than traditional camera systems. While still in the experimental stage, the technology’s reliance on widely available hardware suggests it could be deployed at scale sooner than most would expect.

🧬 What lives inside a Wi-Fi packet
Each packet carries amplitude, how strong the signal arrives, and phase, how the wave shifts over time. Noise and hardware drift skew both pieces, so the team uses median filters for amplitude and a simple line-fitting trick for phase to clean things up.
After a pass of Gaussian noise, random scaling, and tiny time shifts, the data is ready for the network.
Each packet carries amplitude, how strong the signal arrives, and phase, how the wave shifts over time. Noise and hardware drift skew both pieces, so the team uses median filters for amplitude and a simple line-fitting trick for phase to clean things up.
After a pass of Gaussian noise, random scaling, and tiny time shifts, the data is ready for the network.

🛠️ Turning raw radio into signatures
The pipeline has two parts. First comes an encoder that squeezes long CSI sequences into a compact vector. The authors test three options:
LSTM, good with short memories
Bi-LSTM, scans forward and backward
Transformer, uses self-attention to spot long-range patterns
Next is a lightweight linear layer followed by l2 normalization to keep every vector on the same scale, making cosine similarity trivial.
The pipeline has two parts. First comes an encoder that squeezes long CSI sequences into a compact vector. The authors test three options:
LSTM, good with short memories
Bi-LSTM, scans forward and backward
Transformer, uses self-attention to spot long-range patterns
Next is a lightweight linear layer followed by l2 normalization to keep every vector on the same scale, making cosine similarity trivial.
🎯 Training without labeled pairs
Instead of building endless triplets, the paper relies on in-batch negative loss. A batch holds matched query and gallery samples from several people. The model pushes matching pairs to the diagonal of a similarity matrix and shoves the rest away. Every example acts as a negative for every other person, squeezing more value out of small batches.
Instead of building endless triplets, the paper relies on in-batch negative loss. A batch holds matched query and gallery samples from several people. The model pushes matching pairs to the diagonal of a similarity matrix and shoves the rest away. Every example acts as a negative for every other person, squeezing more value out of small batches.
📊 Results that matter
Tests run on the public NTU-Fi set with 14 subjects walking under three clothing setups. The Transformer wins with 95.5% Rank-1 and 88.4% mAP, while Bi-LSTM trails at 84.5% Rank-1 and LSTM lags at 77.7%. Training on sequences of 200 packets is the sweet spot; giving the Transformer more packets helps a bit, LSTM gains nothing.
Tests run on the public NTU-Fi set with 14 subjects walking under three clothing setups. The Transformer wins with 95.5% Rank-1 and 88.4% mAP, while Bi-LSTM trails at 84.5% Rank-1 and LSTM lags at 77.7%. Training on sequences of 200 packets is the sweet spot; giving the Transformer more packets helps a bit, LSTM gains nothing.
🔍 What the ablations reveal
Amplitude filtering, meant to clip outliers, quietly hurts accuracy, dropping the Transformer to 93% Rank-1. Data augmentation lifts LSTM models by a few points but barely nudges the Transformer, showing that self-attention already handles variation well. Deeper is not always better, a single-layer Transformer beats a 3-layer version that overfits.
Amplitude filtering, meant to clip outliers, quietly hurts accuracy, dropping the Transformer to 93% Rank-1. Data augmentation lifts LSTM models by a few points but barely nudges the Transformer, showing that self-attention already handles variation well. Deeper is not always better, a single-layer Transformer beats a 3-layer version that overfits.
🔐 Privacy plus convenience
Routers as sensors mean no faces stored, no GDPR nightmares, and no need to scatter cameras. A single transmitter and three-antenna receiver, the paper’s TP-Link N750 setup, covers the whole test room. That makes deployment cheap in offices, hospitals, or smart homes that value discretion.
Routers as sensors mean no faces stored, no GDPR nightmares, and no need to scatter cameras. A single transmitter and three-antenna receiver, the paper’s TP-Link N750 setup, covers the whole test room. That makes deployment cheap in offices, hospitals, or smart homes that value discretion.
Paper –
Paper Title: "WhoFi: Deep Person Re-Identification via Wi-Fi Channel Signal Encoding"arxiv.org/abs/2507.12869
Paper Title: "WhoFi: Deep Person Re-Identification via Wi-Fi Channel Signal Encoding"arxiv.org/abs/2507.12869
• • •
Missing some Tweet in this thread? You can try to
force a refresh