How big of a paradigm shift was the rise of reasoning models? We dug into the data and found that at least on some benchmarks, reasoning models were likely as large of an algorithmic advance as the Transformer. 
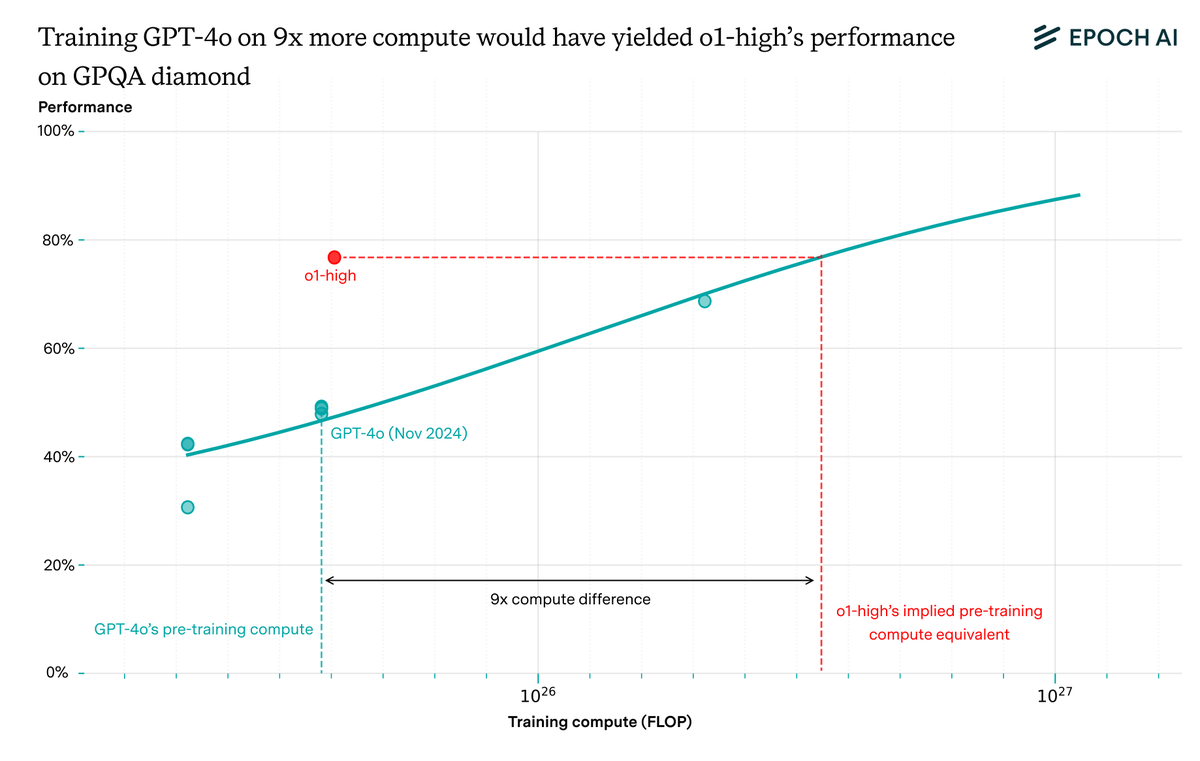
When OpenAI released o1, it blew its predecessor GPT-4o out of the water on some math and science benchmarks. The difference was reasoning training and test-time scaling: o1 was trained to optimize its chain-of-thought, allowing extensive thinking before responding to users.

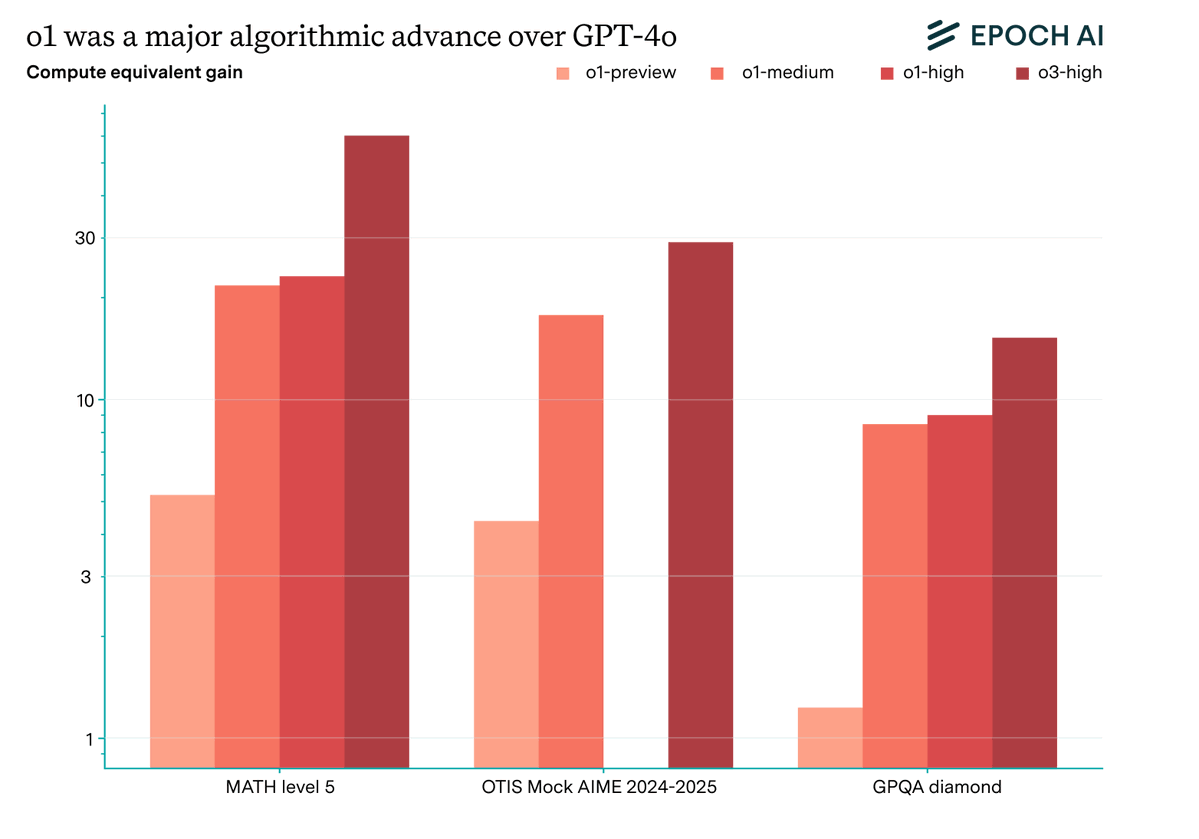
This represented a huge algorithmic improvement. To reach o1-high’s GPQA diamond performance with a non-reasoning model, you’d need 9x more pre-training compute than GPT-4o. That’s larger than the gain from switching from Kaplan to Chinchilla scaling laws!
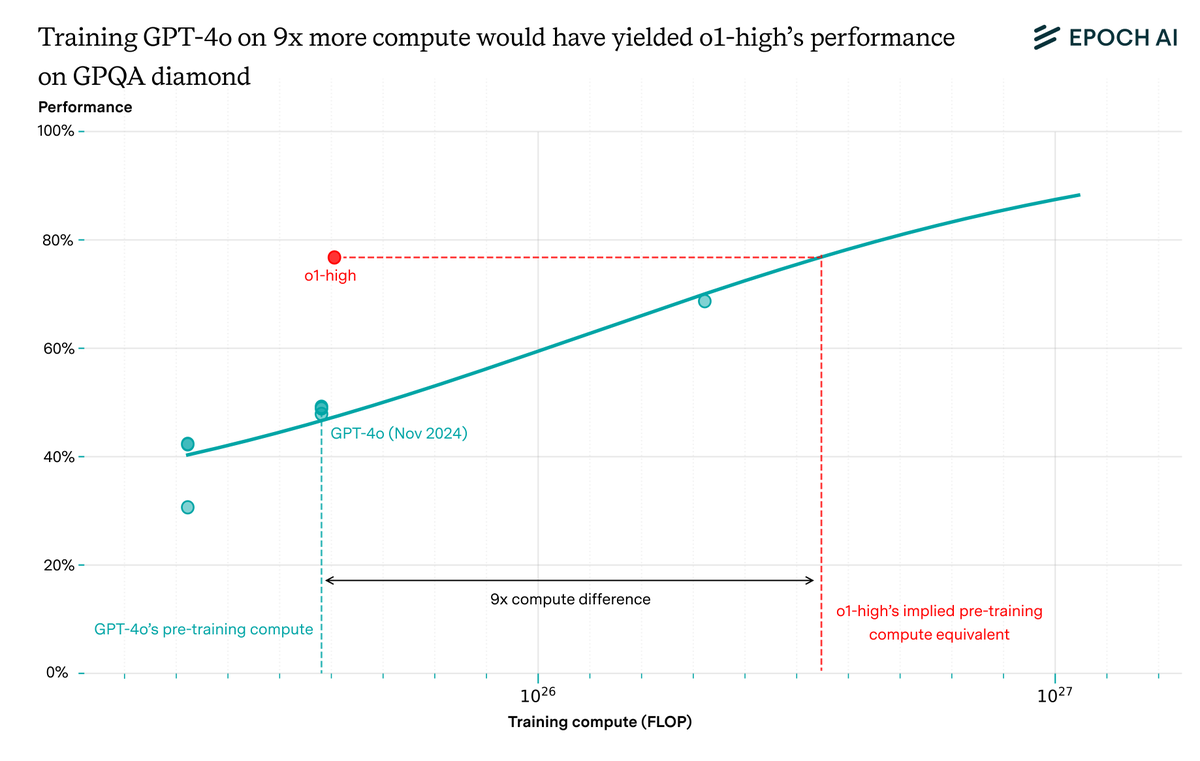
The results are similarly striking with different models and benchmarks. On MATH, Mock AIME, and GPQA diamond, different versions of o1 often are the “equivalent” of GPT-4o trained with over 10x its pre-training compute.
We see a similar pattern with Anthropic’s Claude family. Assuming that Claude 3.7 Sonnet is a reasoning-trained version of Claude 3.5 Sonnet, we again often see “compute-equivalent gains” of a similar scale.

Of course, these estimates are highly uncertain. We have little data to work with, we may have incorrectly identified pairs of reasoning/non-reasoning models, and our estimates depend on the amount of test-time scaling performed.
And some benchmarks are also a lot more amenable to reasoning than others. For example, reasoning models show almost no improvement on GeoBench, but clearly exceed the trend in non-reasoning model performance on Mock AIME.
But benchmarks like GeoBench are exceptions to the norm. The average score of reasoning models was higher than that of non-reasoning models on ~90% of tested benchmarks, though this is in part because reasoning models tend to be more recent.
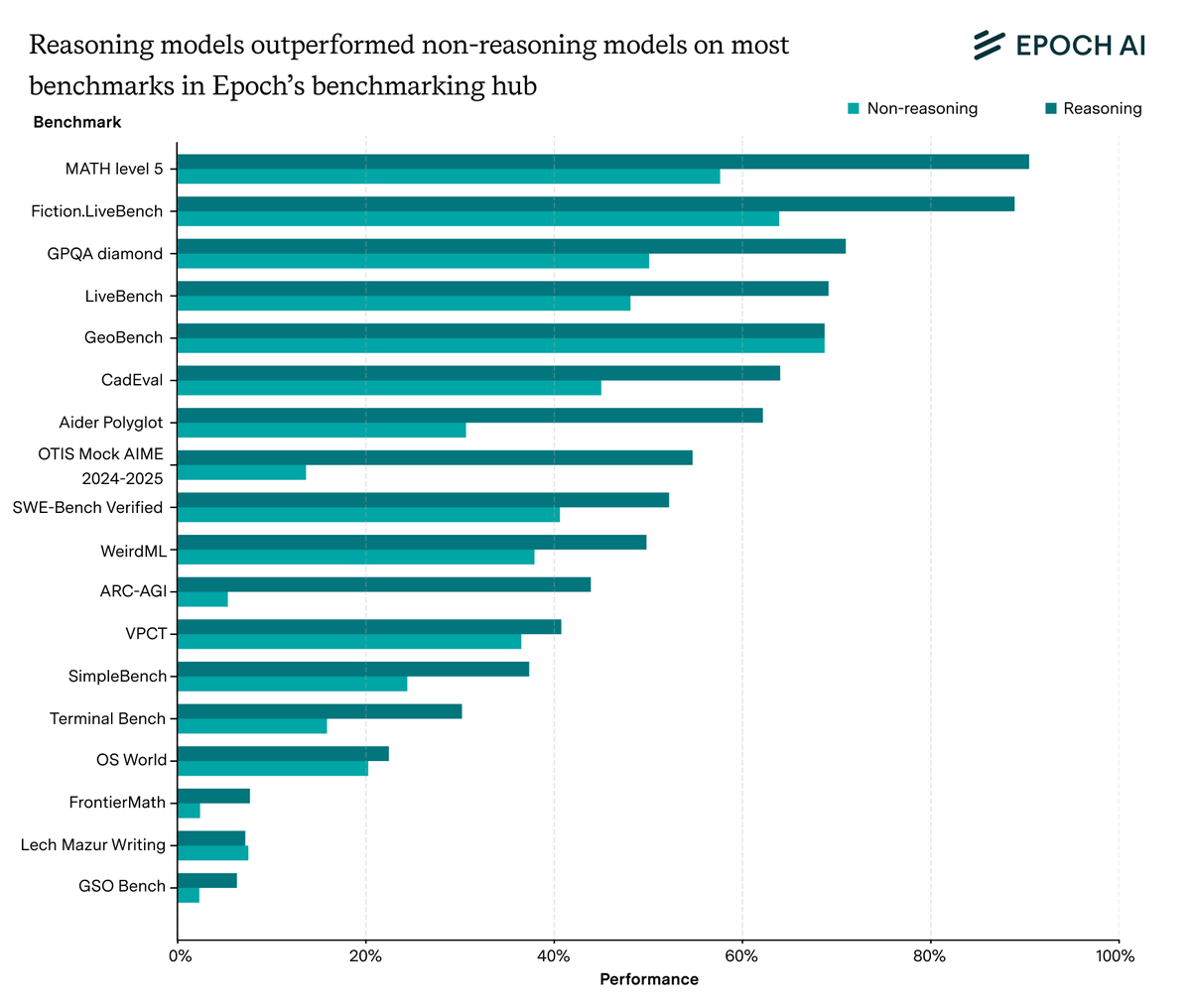
Overall, our results suggest that the shift to reasoning models was a huge algorithmic improvement. On benchmarks amenable to reasoning, we find compute-equivalent gains around 10x, around as large as that for the Transformer.
This post was written by @ansonwhho and @ardenaberg. You can read the full post here: epoch.ai/gradient-updat…
• • •
Missing some Tweet in this thread? You can try to
force a refresh