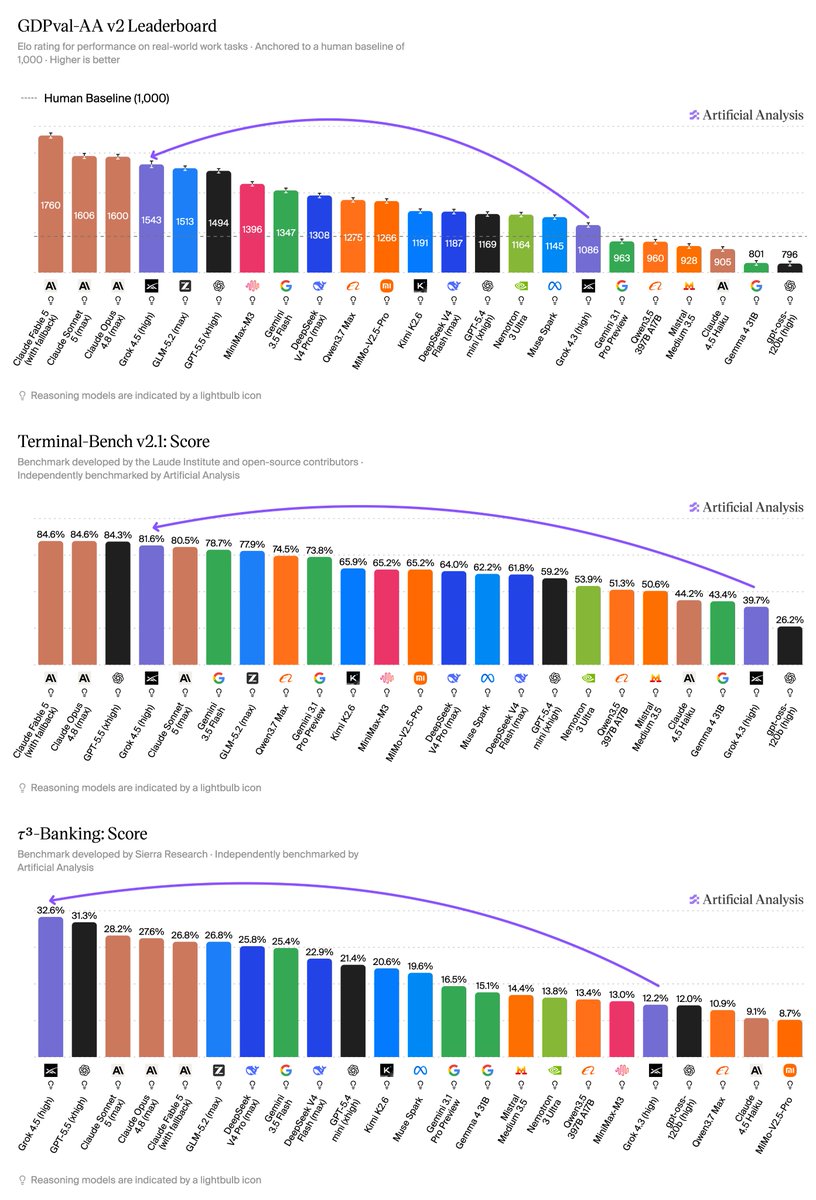
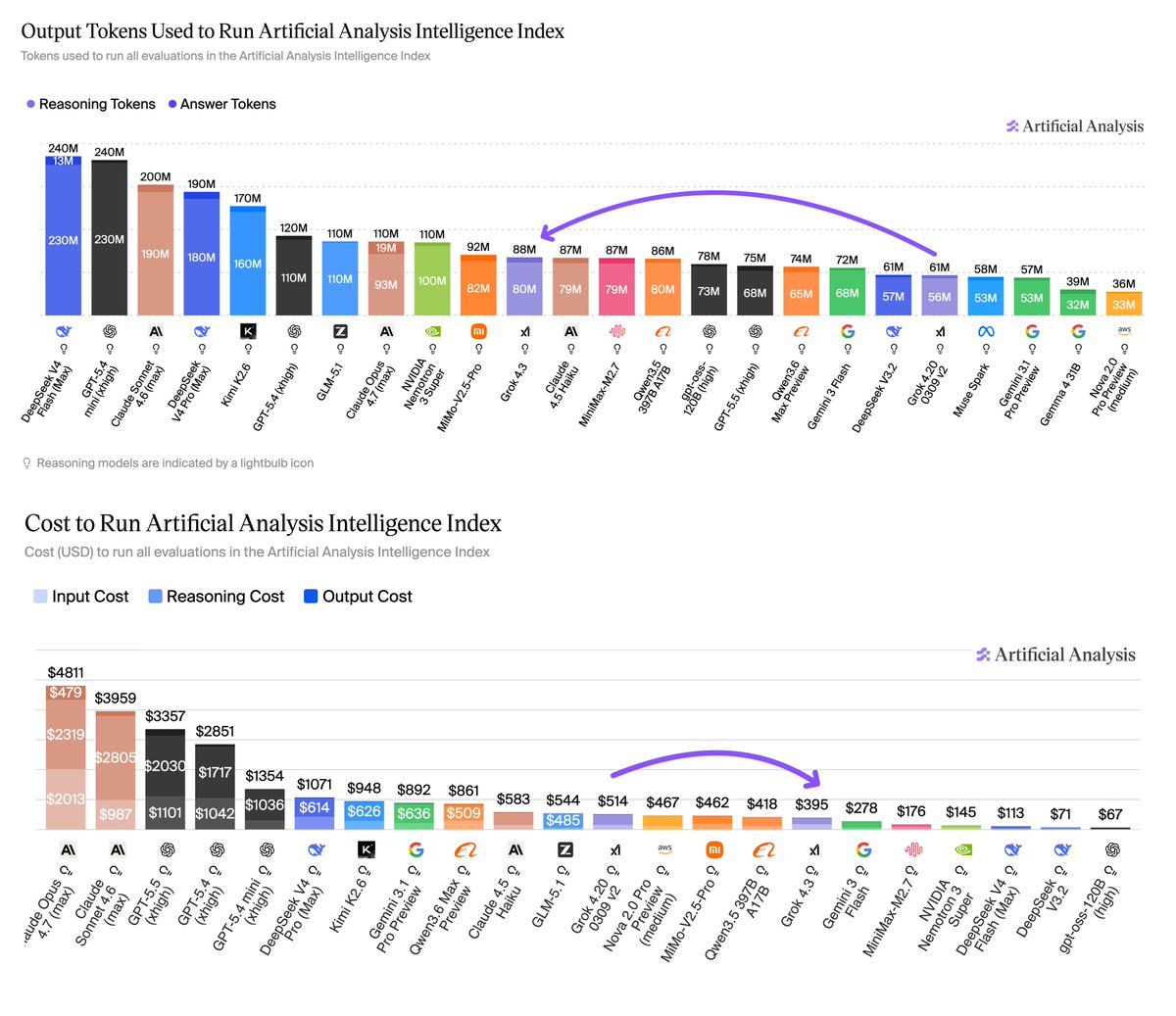
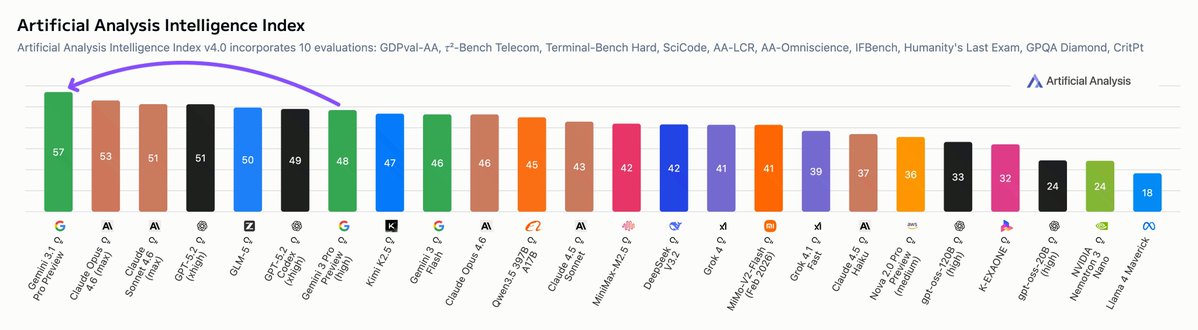
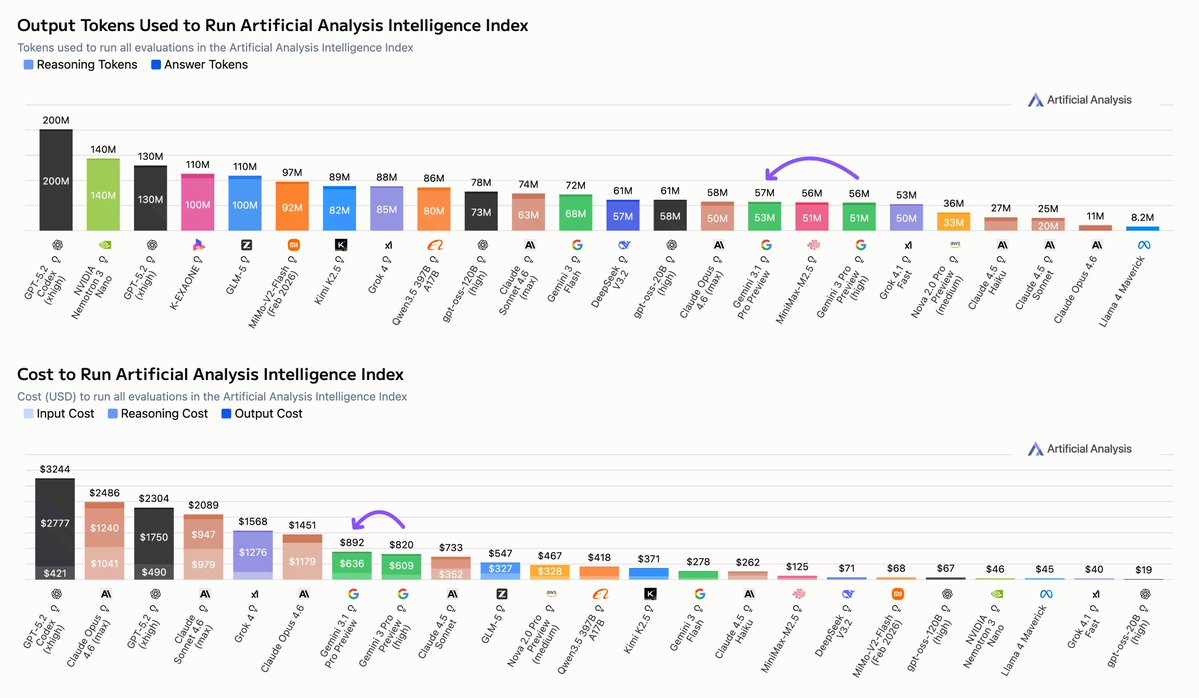
Independent benchmarks of OpenAI’s gpt-oss models: gpt-oss-120b is the most intelligent American open weights model, comes behind DeepSeek R1 and Qwen3 235B in intelligence but offers efficiency benefits
OpenAI has released two versions of gpt-oss:
➤ gpt-oss-120b (116.8B total parameters, 5.1B active parameters): Intelligence Index score of 58
➤ gpt-oss-20b (20.9B total parameters, 3.6B active parameters): Intelligence Index score of 48
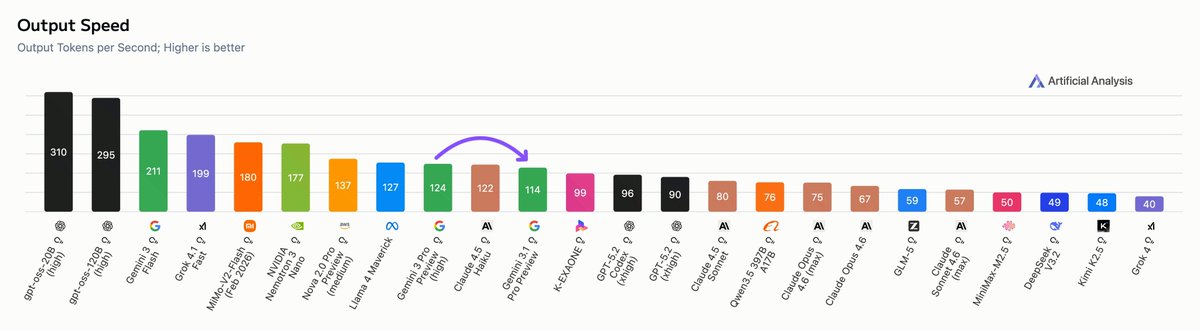
Size & deployment: OpenAI has released both models in MXFP4 precision: gpt-oss-120b comes in at just 60.8GB and gpt-oss-20b just 12.8GB. This means that the 120B can be run in its native precision on a single NVIDIA H100, and the 20B can be run easily on a consumer GPU or laptop with >16GB of RAM. Additionally, the relatively small proportion of active parameters will contribute to their efficiency and speed for inference: the 5.1B active parameters of the 120B model can be contrasted with Llama 4 Scout’s 109B total parameters and 17B active (a lot less sparse). This makes it possible to get dozens of output tokens/s for the 20B on recent MacBooks.
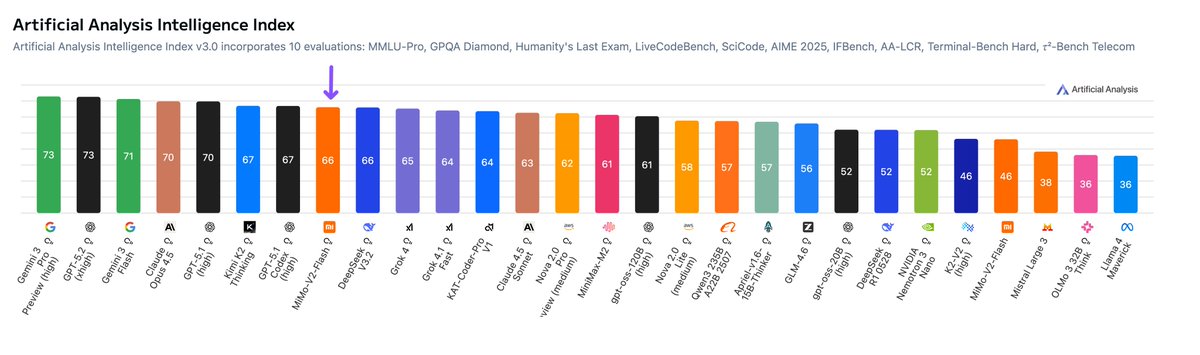
Intelligence: Both models score extremely well for their size and sparsity. We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. Both models appear to place similiarly across most of our evals, indicating no particular areas of weakness.
Comparison to other open weights models: While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models. DeepSeek R1 has 671B total parameters and 37B active parameters, and is released natively in FP8 precision, making its total file size (and memory requirements) over 10x larger than gpt-oss-120b. Both gpt-oss-120b and 20b are text-only models (similar to competing models from DeepSeek, Alibaba and others).
Architecture: The MoE architecture at appears fairly standard. The MoE router selects the top 4 experts for each token generation. The 120B has 36 layers and 20B has 24 layers. Each layer has 64 query heads, uses Grouped Query Attention with 8 KV heads. Rotary embeddings and YaRN are used to extend context window to 128k. The 120B model activates 4.4% of total parameters per forward pass, whereas the 20B model activates 17.2% of total parameters. This may indicate that OpenAI’s perspective is that a higher degree is of sparsity is optimal for larger models. It has been widely speculated that most top models from frontier labs have been sparse MoEs for most releases since GPT-4.
API Providers: A number of inference providers have been quick to launch endpoints. We are currently benchmarking @GroqInc, @CerebrasSystems, @FireworksAI_HQ and @togethercompute on Artificial Analysis and will add more providers as they launch endpoints.
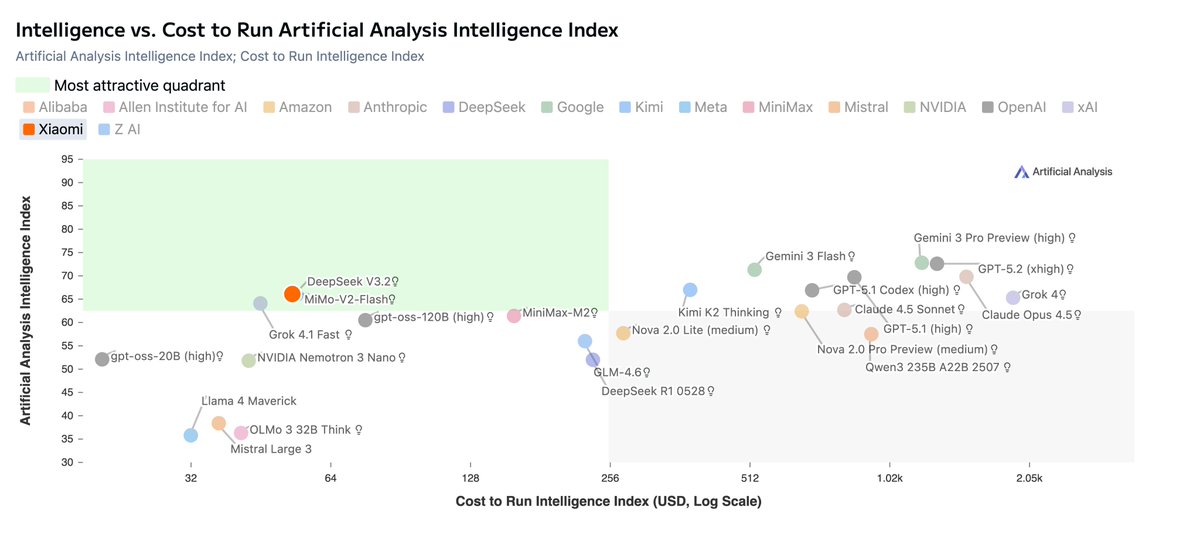
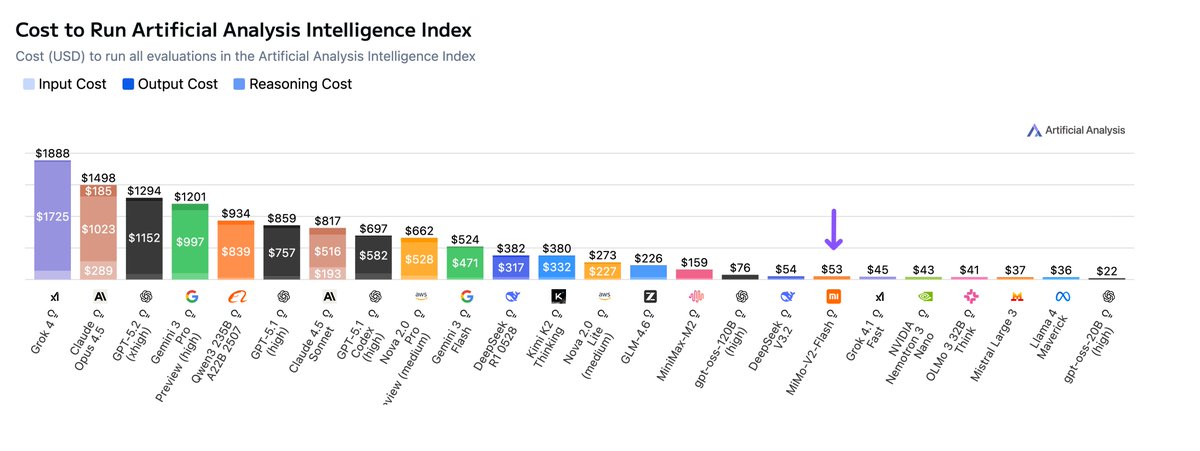
Pricing: We’re tracking median pricing across API providers of $0.15/$0.69 per million input/output tokens for the 120B and $0.08/$0.35 for the 20B. These prices put the 120B close to 10x cheaper than OpenAI’s proprietary APIs for o4-mini ($1.1/$4.4) and o3 ($2/$8).
License: Apache 2.0 license - very permissive!
See below for further analysis:
OpenAI has released two versions of gpt-oss:
➤ gpt-oss-120b (116.8B total parameters, 5.1B active parameters): Intelligence Index score of 58
➤ gpt-oss-20b (20.9B total parameters, 3.6B active parameters): Intelligence Index score of 48
Size & deployment: OpenAI has released both models in MXFP4 precision: gpt-oss-120b comes in at just 60.8GB and gpt-oss-20b just 12.8GB. This means that the 120B can be run in its native precision on a single NVIDIA H100, and the 20B can be run easily on a consumer GPU or laptop with >16GB of RAM. Additionally, the relatively small proportion of active parameters will contribute to their efficiency and speed for inference: the 5.1B active parameters of the 120B model can be contrasted with Llama 4 Scout’s 109B total parameters and 17B active (a lot less sparse). This makes it possible to get dozens of output tokens/s for the 20B on recent MacBooks.
Intelligence: Both models score extremely well for their size and sparsity. We’re seeing the 120B beat o3-mini but come in behind o4-mini and o3. The 120B is the most intelligent model that can be run on a single H100 and the 20B is the most intelligent model that can be run on a consumer GPU. Both models appear to place similiarly across most of our evals, indicating no particular areas of weakness.
Comparison to other open weights models: While the larger gpt-oss-120b does not come in above DeepSeek R1 0528’s score of 59 or Qwen3 235B 2507s score of 64, it is notable that it is significantly smaller in both total and active parameters than both of those models. DeepSeek R1 has 671B total parameters and 37B active parameters, and is released natively in FP8 precision, making its total file size (and memory requirements) over 10x larger than gpt-oss-120b. Both gpt-oss-120b and 20b are text-only models (similar to competing models from DeepSeek, Alibaba and others).
Architecture: The MoE architecture at appears fairly standard. The MoE router selects the top 4 experts for each token generation. The 120B has 36 layers and 20B has 24 layers. Each layer has 64 query heads, uses Grouped Query Attention with 8 KV heads. Rotary embeddings and YaRN are used to extend context window to 128k. The 120B model activates 4.4% of total parameters per forward pass, whereas the 20B model activates 17.2% of total parameters. This may indicate that OpenAI’s perspective is that a higher degree is of sparsity is optimal for larger models. It has been widely speculated that most top models from frontier labs have been sparse MoEs for most releases since GPT-4.
API Providers: A number of inference providers have been quick to launch endpoints. We are currently benchmarking @GroqInc, @CerebrasSystems, @FireworksAI_HQ and @togethercompute on Artificial Analysis and will add more providers as they launch endpoints.
Pricing: We’re tracking median pricing across API providers of $0.15/$0.69 per million input/output tokens for the 120B and $0.08/$0.35 for the 20B. These prices put the 120B close to 10x cheaper than OpenAI’s proprietary APIs for o4-mini ($1.1/$4.4) and o3 ($2/$8).
License: Apache 2.0 license - very permissive!
See below for further analysis:


Intelligence vs. Total Parameters: gpt-oss-120B is the most intelligence model that can fit on a single H100 GPU in its native precision.

Pricing: Across the API providers who have launched day one API coverage, we’re seeing median prices of $0.15/$0.69 per million input/output tokens for the 120B and $0.08/$0.35 for the 20B. This makes both gpt-oss models highly cost efficient options for developers.

Output token usage: Relative to other reasoning models, both models are quite efficient even in their ‘high’ reasoning modes, particularly gpt-oss-120b which used only 21M tokens to run our Artificial Analysis Intelligence Index benchmarks. This is 1/4 of the tokens o4-mini (high) took to run the same benchmarks, 1/2 of o3 and less than Kimi K2 (a non-reasoning model).



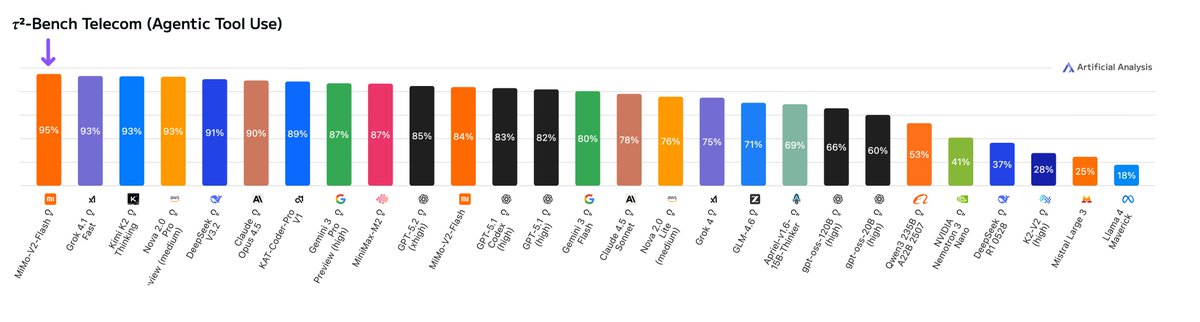
Individual evaluation results from benchmarks we have run independently:

See Artificial Analysis for further analysis:
Comparisons to other models:
artificialanalysis.ai/models
Comparisons to other open weights models:
artificialanalysis.ai/models/open-so…
Benchmarks of providers serving gpt-oss-120b:
artificialanalysis.ai/models/gpt-oss…
Comparisons to other models:
artificialanalysis.ai/models
Comparisons to other open weights models:
artificialanalysis.ai/models/open-so…
Benchmarks of providers serving gpt-oss-120b:
artificialanalysis.ai/models/gpt-oss…
• • •
Missing some Tweet in this thread? You can try to
force a refresh