
Announcing MCP•RL: teach your model how to use any MCP server automatically using reinforcement learning!
Just connect any MCP server, and your model will start playing with it and (using RL) "learn from experience" how to use its tools most effectively!
Just connect any MCP server, and your model will start playing with it and (using RL) "learn from experience" how to use its tools most effectively!
How does it work? When you connect a server, MCP•RL:
1. Queries the server to get a list of tools
2. Uses a strong model to brainstorm tasks that the tools might be useful for
3. Tries to complete the task using the tools
4. Improves using RULER
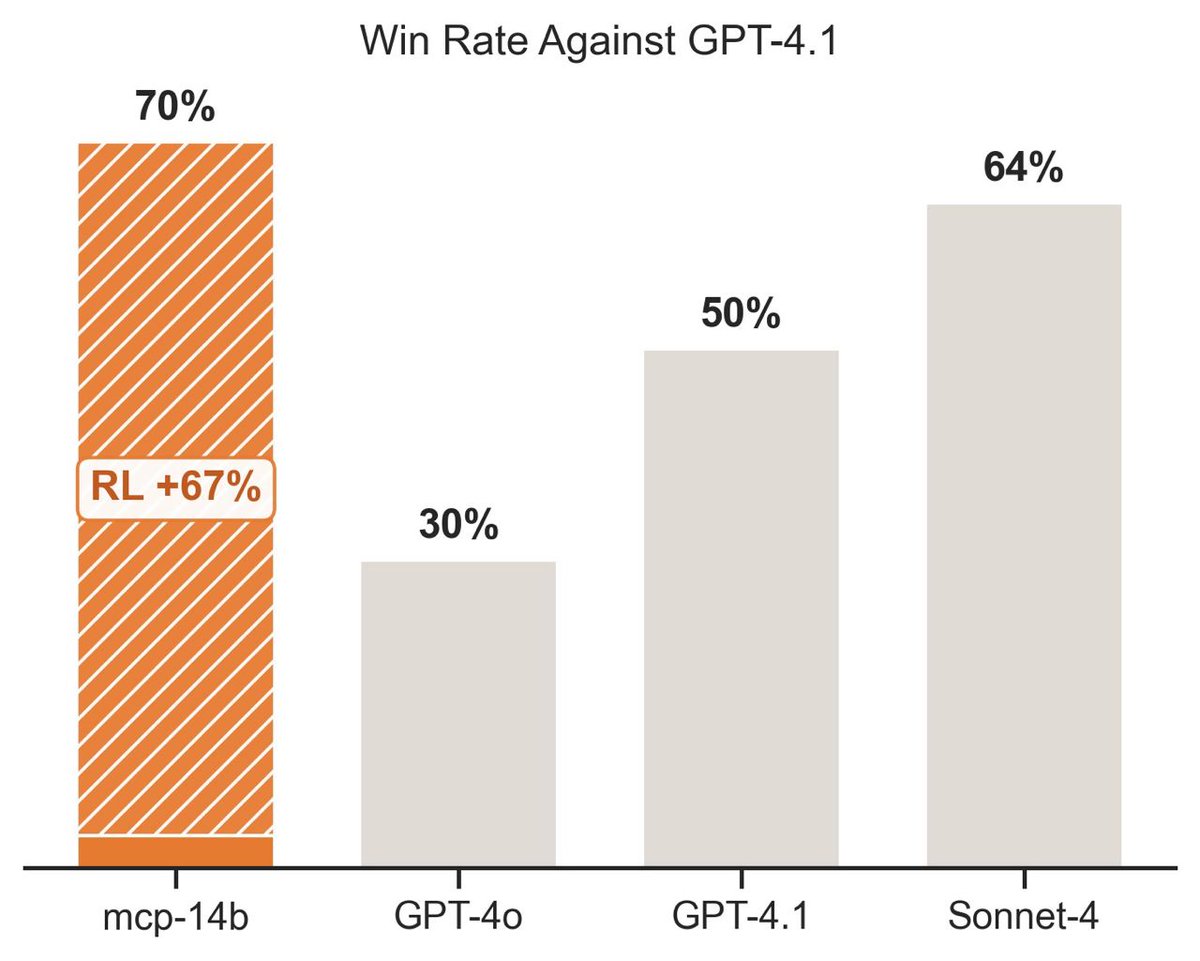
In practice, it trains great!
1. Queries the server to get a list of tools
2. Uses a strong model to brainstorm tasks that the tools might be useful for
3. Tries to complete the task using the tools
4. Improves using RULER
In practice, it trains great!

MCP•RL is fully open source and is released as part of the Agent Reinforcement Trainer (ART) project.
We have an example notebook training Qwen2.5 to use an MCP server here! github.com/OpenPipe/ART?t…
We have an example notebook training Qwen2.5 to use an MCP server here! github.com/OpenPipe/ART?t…
all credit to @dvdcrbt, this was his project 🙂
• • •
Missing some Tweet in this thread? You can try to
force a refresh












