
Currently building @OpenPipeAI (acquired by @CoreWeave). Formerly @ycombinator, @google.
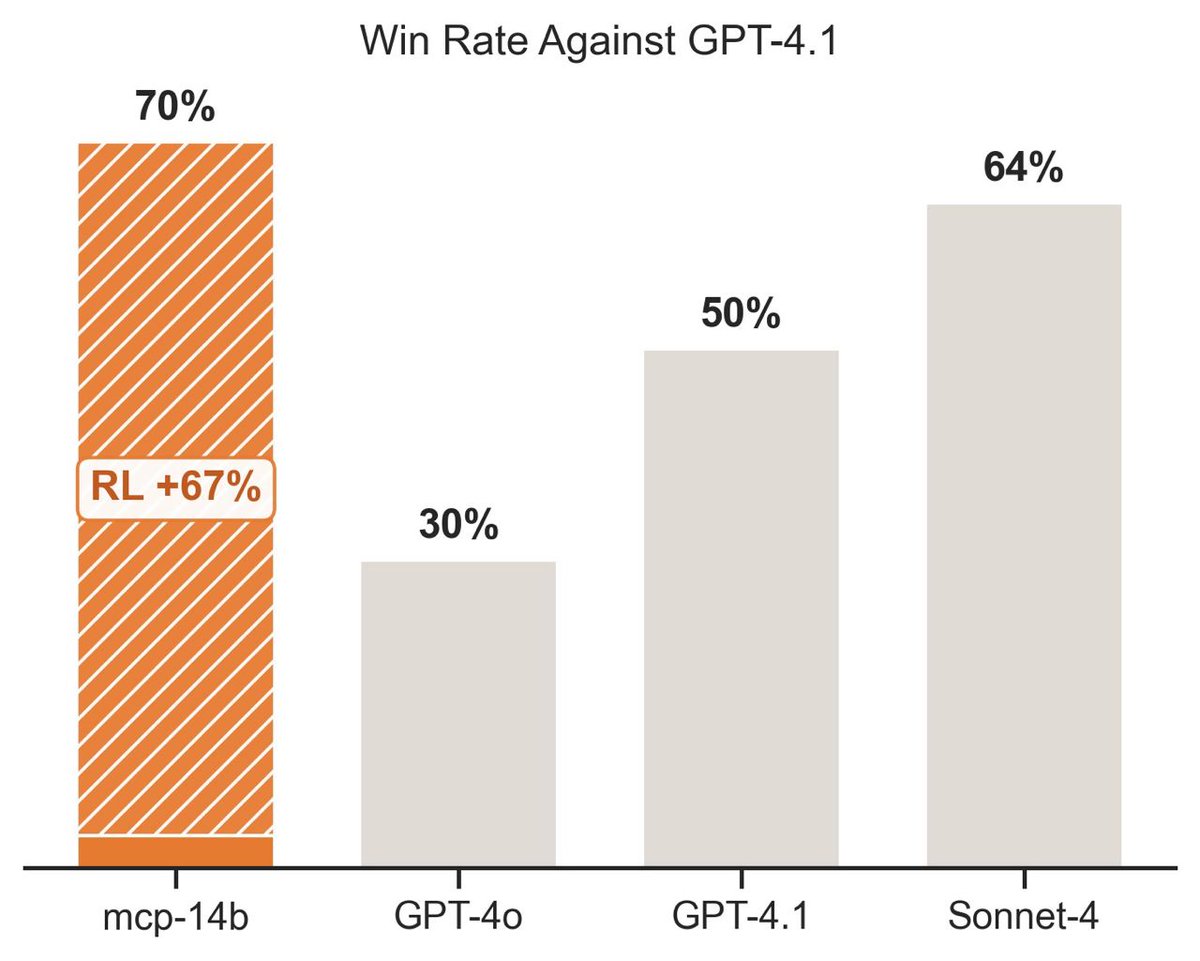
 High-quality deep research has been one of the strongest new capabilities recently released by frontier labs. We knew they used RL to make it work well, but no working recipe has been shared in public. Until now!
High-quality deep research has been one of the strongest new capabilities recently released by frontier labs. We knew they used RL to make it work well, but no working recipe has been shared in public. Until now! 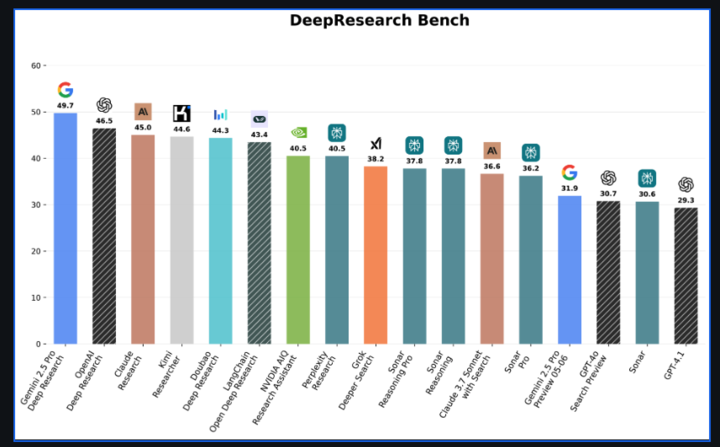
 How does it work? When you connect a server, MCP•RL:
How does it work? When you connect a server, MCP•RL:


 Why did we do this? LLMs are already good at generating summaries, but they don't always focus on the information you care about. RL lets you customize a model to focus specifically on the types of data you want to preserve.
Why did we do this? LLMs are already good at generating summaries, but they don't always focus on the information you care about. RL lets you customize a model to focus specifically on the types of data you want to preserve.
 We were inspired by OpenAI’s Deep Research, which showed how effective RL can be to teach an agent a research task. Our goal with ART·E was to replicate similar performance wins using open data and code!
We were inspired by OpenAI’s Deep Research, which showed how effective RL can be to teach an agent a research task. Our goal with ART·E was to replicate similar performance wins using open data and code!


 Here's agent.exe booking travel on Google Flights. ✈️Claude 3.5 definitely isn't perfect—note that it confidently chooses the wrong dates!
Here's agent.exe booking travel on Google Flights. ✈️Claude 3.5 definitely isn't perfect—note that it confidently chooses the wrong dates!
 The MoA architecture is simple: generate 3 initial GPT-4 completions, have GPT-4 reflect on them, and then have GPT-4 produce a final output based on its deliberations.
The MoA architecture is simple: generate 3 initial GPT-4 completions, have GPT-4 reflect on them, and then have GPT-4 produce a final output based on its deliberations. 