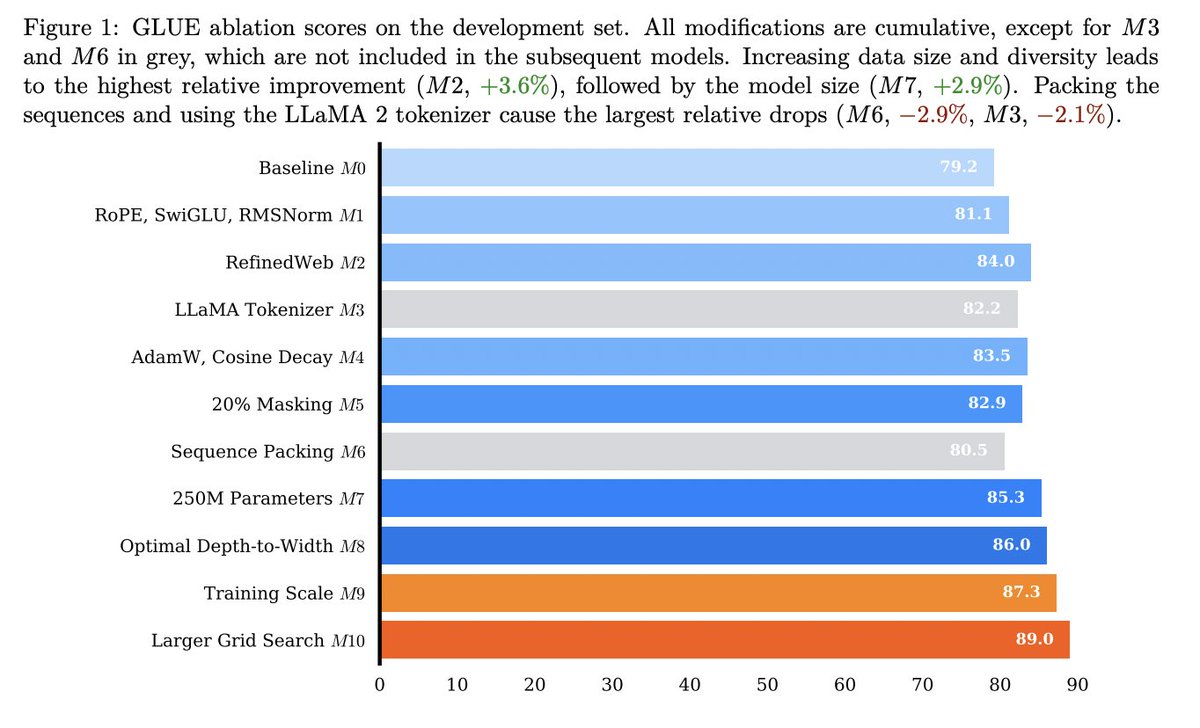
curious about the training data of OpenAI's new gpt-oss models? i was too.
so i generated 10M examples from gpt-oss-20b, ran some analysis, and the results were... pretty bizarre
time for a deep dive 🧵
so i generated 10M examples from gpt-oss-20b, ran some analysis, and the results were... pretty bizarre
time for a deep dive 🧵

here's a map of the embedded generations
the model loves math and code. i prompt with nothing and yet it always reasons. it just talks about math and code, and mostly in English
math – probability, ML, PDEs, topology, diffeq
code – agentic software, competitive programming, data science
the model loves math and code. i prompt with nothing and yet it always reasons. it just talks about math and code, and mostly in English
math – probability, ML, PDEs, topology, diffeq
code – agentic software, competitive programming, data science


first thing to notice is that practically none of the generations resemble natural webtext. but surprisingly none of them look like normal chatbot interactions either
this thing is clearly trained via RL to think and solve tasks for specific reasoning benchmarks. nothing else.
this thing is clearly trained via RL to think and solve tasks for specific reasoning benchmarks. nothing else.
and it truly is a tortured model. here the model hallucinates a programming problem about dominos and attempts to solve it, spending over 30,000 tokens in the process
completely unprompted, the model generated and tried to solve this domino problem over 5,000 separate times
completely unprompted, the model generated and tried to solve this domino problem over 5,000 separate times

ran a classifier over outputs to get a sense of which programming languages gpt-oss knows
they seem to have trained on nearly everything you've ever heard of. especially a lot of Perl
(btw, from my analysis Java and Kotlin should be way higher. classifier may have gone wrong)
they seem to have trained on nearly everything you've ever heard of. especially a lot of Perl
(btw, from my analysis Java and Kotlin should be way higher. classifier may have gone wrong)

what you can't see from the map is many of the chains start in English but slowly descend into Neuralese
the reasoning chains happily alternate between Arabic, Russian, Thai, Korean, Chinese, and Ukrainian. then usually make their way back to English (but not always)
the reasoning chains happily alternate between Arabic, Russian, Thai, Korean, Chinese, and Ukrainian. then usually make their way back to English (but not always)


the OCR conjecture:
some examples include artifacts such as OCRV ROOT, which indicate the training data may have been
reading between the lines: OpenAI is scanning books
(for some reason the model loves mentioning how many deaf people live in Malaysia)
some examples include artifacts such as OCRV ROOT, which indicate the training data may have been
reading between the lines: OpenAI is scanning books
(for some reason the model loves mentioning how many deaf people live in Malaysia)

what are some explanations for constant codeswitching?
1. OpenAI has figured out RL. the models no longer speak english
2. data corruption issues via OCR or synthetic training
3. somehow i forced the model to output too many tokens and they gradually shift out of distribution
1. OpenAI has figured out RL. the models no longer speak english
2. data corruption issues via OCR or synthetic training
3. somehow i forced the model to output too many tokens and they gradually shift out of distribution
there are a small number of creative outputs interspersed throughout
here's one example where the model starts writing a sketch for a norwegian screenplay 🤷♂️
here's one example where the model starts writing a sketch for a norwegian screenplay 🤷♂️

i also learned a lot from this one.
the model is *really* good at using unicode
...but might be bad at physics. what in the world is a 'superhalo function'
the model is *really* good at using unicode
...but might be bad at physics. what in the world is a 'superhalo function'

if you want to try the data, here you go, it's on huggingface:
let me know what you find! huggingface.co/datasets/jxm/g…
let me know what you find! huggingface.co/datasets/jxm/g…

FUTURE WORK – deduplication
even though i varied the random seed and used temperature, a lot of the outputs are highly redundant
it would be prudent to deduplicate, i bet there are only 100k or fewer mostly-unique examples here
even though i varied the random seed and used temperature, a lot of the outputs are highly redundant
it would be prudent to deduplicate, i bet there are only 100k or fewer mostly-unique examples here
FUTURE WORK – describing differences
@ZhongRuiqi has some incredible work on methods for describing the difference between two text distributions *in natural language*
we could compare outputs of 20b to the 120b model, or LLAMA, or GPT-5...
@ZhongRuiqi has some incredible work on methods for describing the difference between two text distributions *in natural language*
we could compare outputs of 20b to the 120b model, or LLAMA, or GPT-5...
FUTURE WORK – direct extraction
we're working on directly extracting training data from models using RL and other methods. we'll be presenting our first work on this in COLM, and expect more in this space
we may be able to directly extract data from the 120b model.. one day 😎
we're working on directly extracting training data from models using RL and other methods. we'll be presenting our first work on this in COLM, and expect more in this space
we may be able to directly extract data from the 120b model.. one day 😎
• • •
Missing some Tweet in this thread? You can try to
force a refresh