
research // language models, information theory, science of AI // formerly @cornell

 if you're not familiar with base models: here are some samples comparing our new model to the original!
if you're not familiar with base models: here are some samples comparing our new model to the original!
 here's a map of the embedded generations
here's a map of the embedded generations

 the key insight, i think, is using an optimal depth-to-width ratio for the transformer architecture. and training on good data. a lot of good data.
the key insight, i think, is using an optimal depth-to-width ratio for the transformer architecture. and training on good data. a lot of good data.

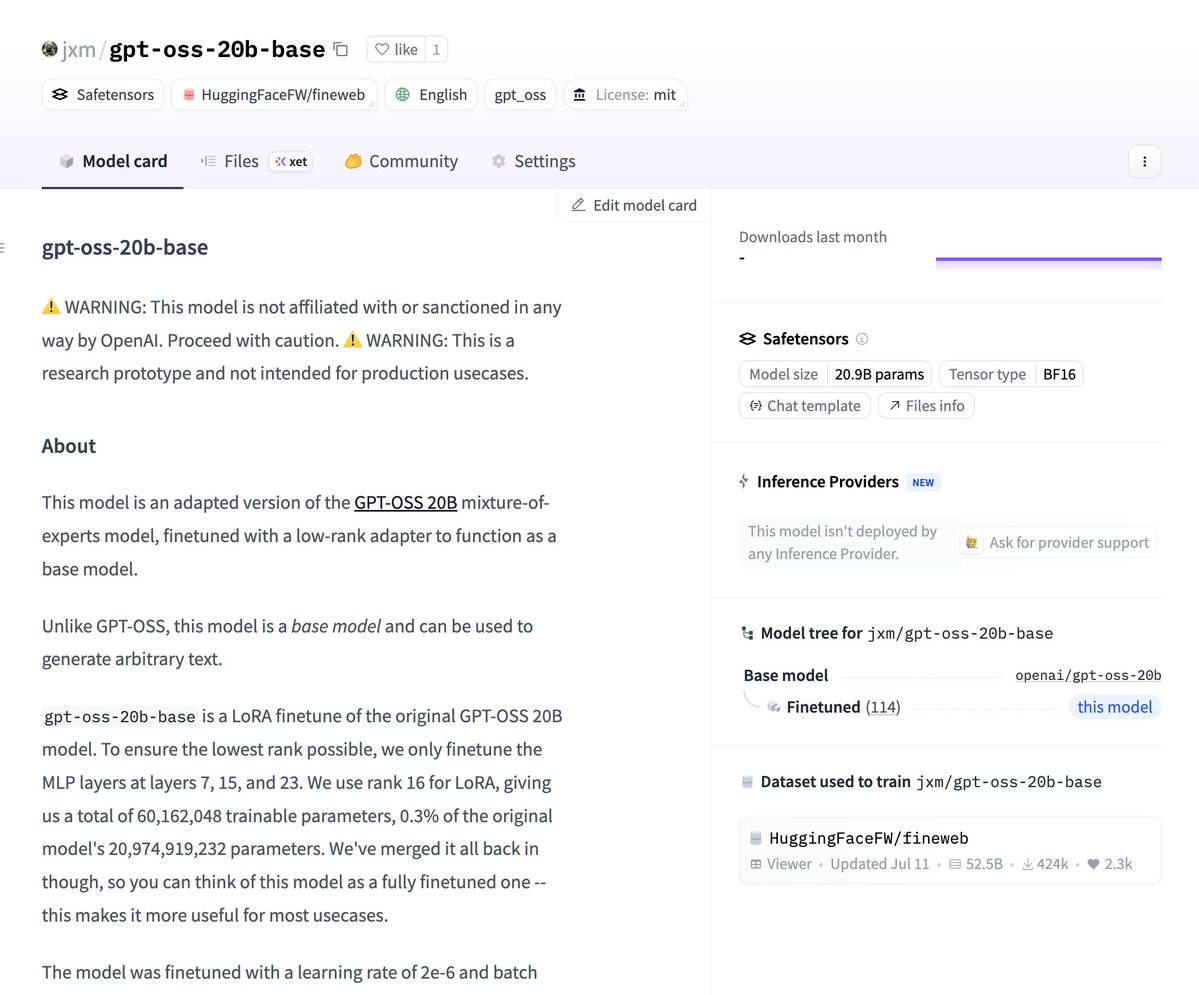
 to do this, you need TWO sets of model weights: the initial model and a finetune
to do this, you need TWO sets of model weights: the initial model and a finetune

 this all started from a quest to come up with a proper measurement of model memorization
this all started from a quest to come up with a proper measurement of model memorization

 turns out the way paints mix (blue + red = purple) is much more complicated than how light mixes (blue + red = pink)
turns out the way paints mix (blue + red = purple) is much more complicated than how light mixes (blue + red = pink)
 Typical text embedding models have two main problems
Typical text embedding models have two main problems I think our most crucial finding is that although humans think far ahead while speaking (especially while doing complex reasoning problems) it turns out that transformer language models.... don't seem to do that.
I think our most crucial finding is that although humans think far ahead while speaking (especially while doing complex reasoning problems) it turns out that transformer language models.... don't seem to do that.