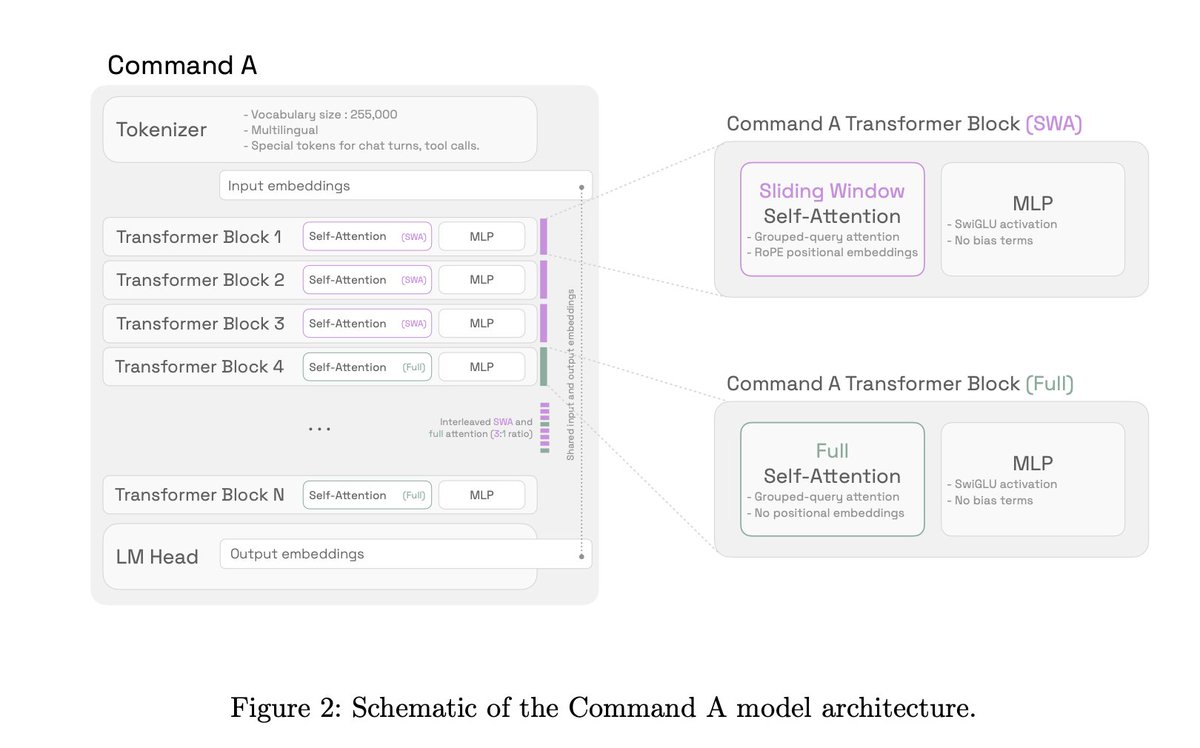
Let's talk about the GLM 4.5 models.
The latest frontier open weights model out of China (and possibly the best at the moment?) with quite a bit of details in the paper.
The latest frontier open weights model out of China (and possibly the best at the moment?) with quite a bit of details in the paper.

The main interesting thing about architecture is its load balancing. No aux loss and they use expert biases where they add a bias to the expert scores. The bias is then adjusted after each step to over/undercorrect the load balancing
(figures from the paper they citehttps://arxiv.org/pdf/2408.15664)
(figures from the paper they citehttps://arxiv.org/pdf/2408.15664)


Compared to DeepSeek V3 and K2, they make quite a bit of changes.
- Deeper but narrower
- no mla but gqa
- qk norm
- higher attention head/hidden dim ratio
They say that doubling attention heads doesnt improve loss but improves downstream reasoning evals. This actually reflects Kimi's finding that attention heads had neglible impact on loss. But I guess kimi didnt eval on downstream benchmarks beyond just loss
- Deeper but narrower
- no mla but gqa
- qk norm
- higher attention head/hidden dim ratio
They say that doubling attention heads doesnt improve loss but improves downstream reasoning evals. This actually reflects Kimi's finding that attention heads had neglible impact on loss. But I guess kimi didnt eval on downstream benchmarks beyond just loss

Pretraining data of 15T tokens. They bucket based on quality and sample based on the buckets with the highest quality bucket doing 3.2 epochs.
For code, they use both github and html documents and specifically train on FIM. They also do quality bucketing here.
For math and science, they train a quality classifier on educational quality of papers.
I would have liked to see more detail here on how they determine quality etc.
For code, they use both github and html documents and specifically train on FIM. They also do quality bucketing here.
For math and science, they train a quality classifier on educational quality of papers.
I would have liked to see more detail here on how they determine quality etc.
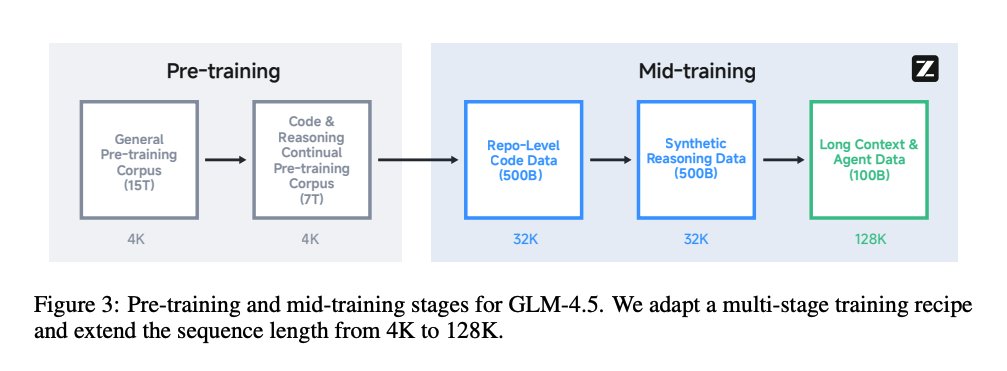
For midtraining, they add another 7T tokens:
- Multiple files concatenated together to learn single repo/multi file dependencies
- Synthetic reasoning traces
- Long context
I dont think there is much new here. The only thing to speculate is which reasoner did they distill from here.
- Multiple files concatenated together to learn single repo/multi file dependencies
- Synthetic reasoning traces
- Long context
I dont think there is much new here. The only thing to speculate is which reasoner did they distill from here.
For training, they used Muon + cosine decay. They chose not to use WSD because they suspect WSD performs worse due to underfitting in the stable stage.
There is a ton of info here on hyperparams which would be useful as starting/reference points in sweeps
There is a ton of info here on hyperparams which would be useful as starting/reference points in sweeps

For SFT, they first train 3 expert models (Reasoning, Agent, Chat) and then distill them back into one model.
Experts on trained on a small set of cold start reasoning data. After the experts are done then they do normal SFT on samples from these expert models.
Here, they want the final model to be a hybrid reasoner so they balance reasoning/non reasoning data.
Experts on trained on a small set of cold start reasoning data. After the experts are done then they do normal SFT on samples from these expert models.
Here, they want the final model to be a hybrid reasoner so they balance reasoning/non reasoning data.
1 interesting thing is that they (finally!) got rid of json for function calling in exchange for xml because it is much easier to generate without needing to randomly escape characters.

Some other details when sampling from the expert models:
- they find that only training on the 50% of data with longer response lengths led to better performance. there was even more gain on training on multiple samples from these prompts.
- a ton of rejection sampling
They also SFT on agent data with a now familiar recipe.
1) Collect real world APIs and MCPs
2) Generate prompts
3) Generate fake API response using LLMs
4) Filter trajectories
- they find that only training on the 50% of data with longer response lengths led to better performance. there was even more gain on training on multiple samples from these prompts.
- a ton of rejection sampling
They also SFT on agent data with a now familiar recipe.
1) Collect real world APIs and MCPs
2) Generate prompts
3) Generate fake API response using LLMs
4) Filter trajectories
The next section is on reasoning RL (GRPO + no KL)
1) 2 stage RL with hard prompts in the final stage is best (512 rollouts!)
2) Since the SFTed model already generates long CoT, don't start training by cutting off its context length (it cannot recover performance). Just continue training from the max 64K sequence length
3) To scale temperature and deal with entropy collapsing, they validate on a range of values during training on a val set. They choose the max value that has less than 1% performance drop
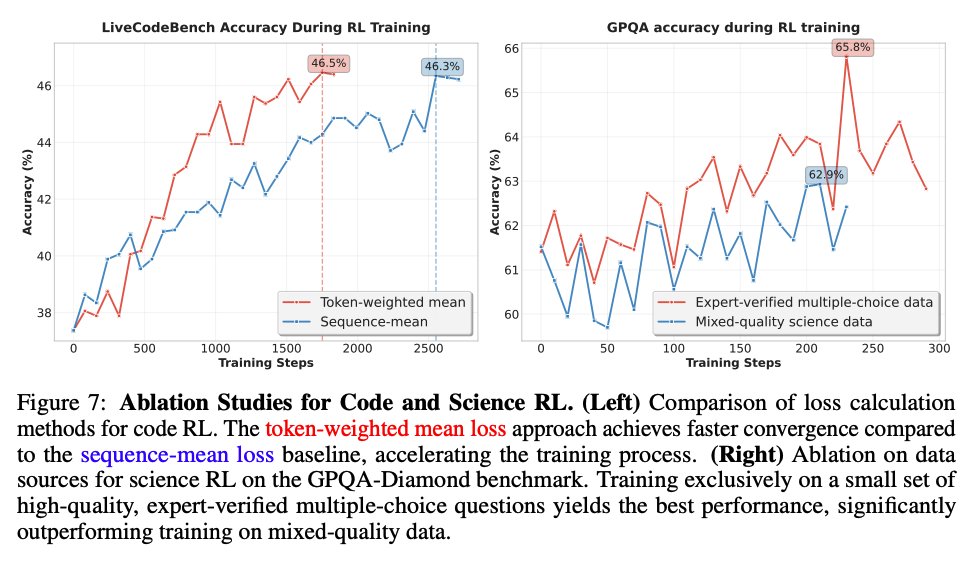
4) For code, token loss is better than sequence loss.
5) Science RL benefits most from data quality
(side note i think its funny they call sequence mean "conventional" when im pretty sure its a mix with some impl were still using token mean and the recent papers about it likely published after they were done)
1) 2 stage RL with hard prompts in the final stage is best (512 rollouts!)
2) Since the SFTed model already generates long CoT, don't start training by cutting off its context length (it cannot recover performance). Just continue training from the max 64K sequence length
3) To scale temperature and deal with entropy collapsing, they validate on a range of values during training on a val set. They choose the max value that has less than 1% performance drop
4) For code, token loss is better than sequence loss.
5) Science RL benefits most from data quality
(side note i think its funny they call sequence mean "conventional" when im pretty sure its a mix with some impl were still using token mean and the recent papers about it likely published after they were done)
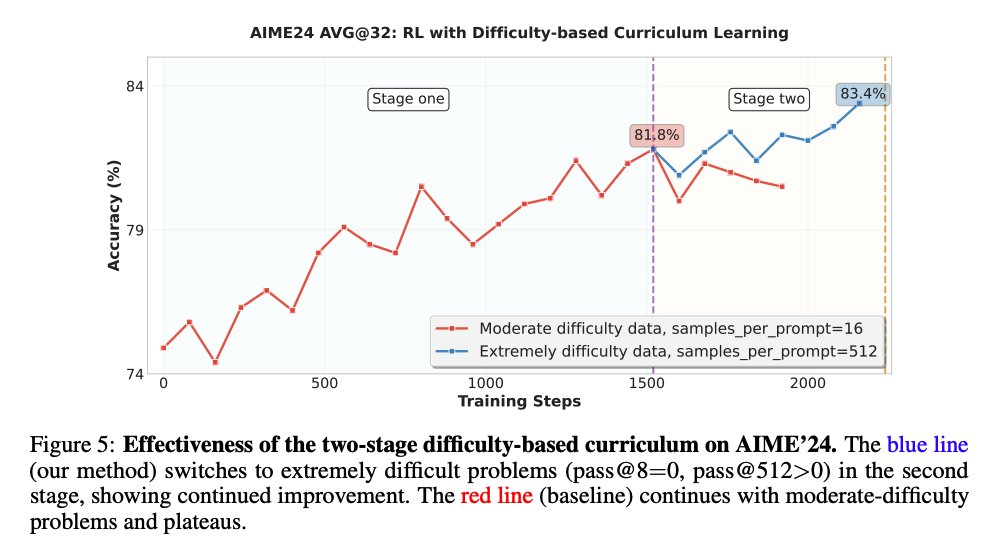
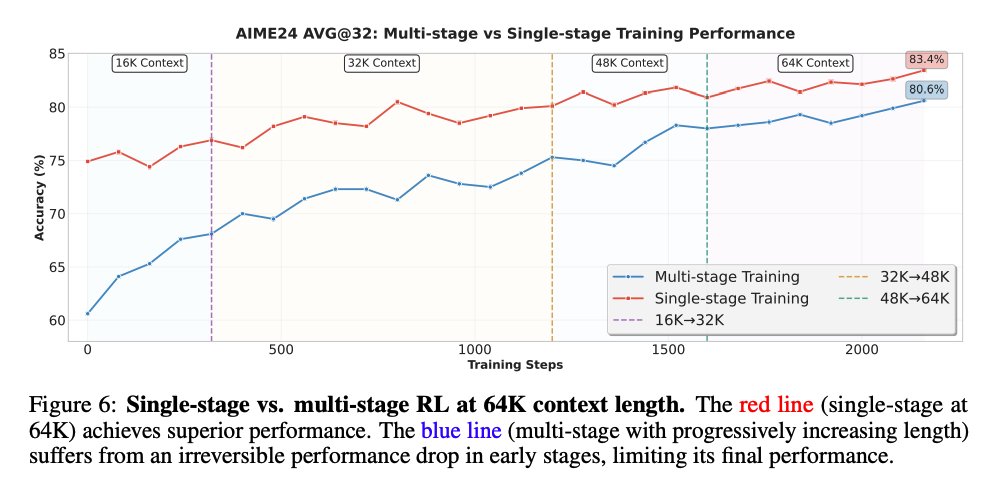
For agentic RL, they train specifically on deepresearch/swebench style problems and interestingly say that it transfers.
The info about their deepresearch dataset curation is a little sparse here.
They also do this iterative distillation thing which i dont quite understand what they are saying to be honest so just putting it here. (is it just RL to get model 1. Use model 1 to generate cold start which trains the base for what would come to be model 2?)
The info about their deepresearch dataset curation is a little sparse here.
They also do this iterative distillation thing which i dont quite understand what they are saying to be honest so just putting it here. (is it just RL to get model 1. Use model 1 to generate cold start which trains the base for what would come to be model 2?)


They also do a bunch of general RLHF RLAIF RL. Again, i would like to have seen examples/broad categories of the type of "scoring rubrics" they used.
They RL on:
- 5000 diverse prompts (i have no clue what primary/secondary/tertiary categories are)
- if eval style dataset (+ reward model, critique model and rules all to prevent hacking)
- Function calling RL on function format correctness in both single and multi turn (where the use is simulated by an LLM)
They RL on:
- 5000 diverse prompts (i have no clue what primary/secondary/tertiary categories are)
- if eval style dataset (+ reward model, critique model and rules all to prevent hacking)
- Function calling RL on function format correctness in both single and multi turn (where the use is simulated by an LLM)

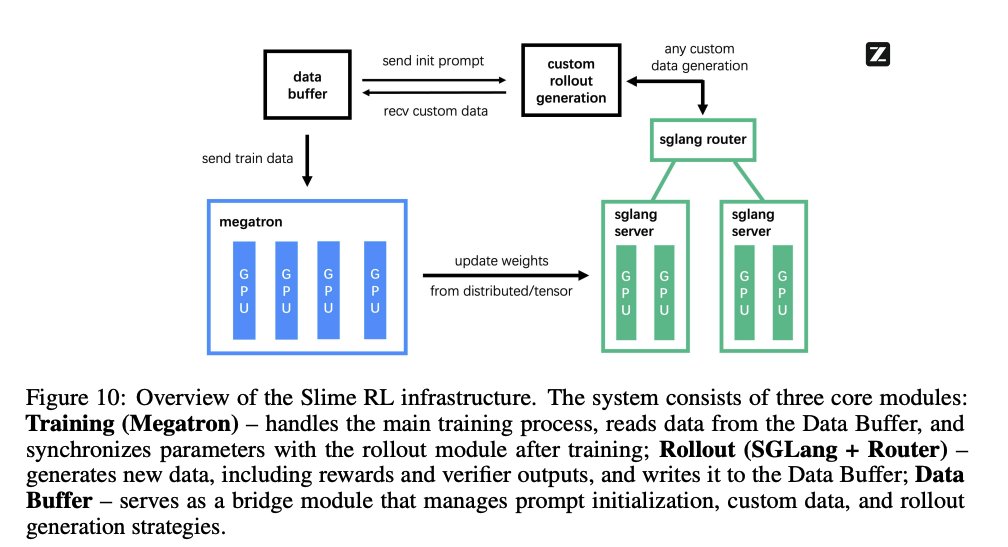
Next section is on their RL infra + stack of megatron and sglang (github.com/THUDM/slime).
They find "different RL tasks benefit from different scheduling approaches".
- Code and Math: Keeping training and inference engines on the same worker is best since this maximizes utilisation.
- Agent: Keep training and inference separate to maximise environment throughput. This is pretty standard async RL where you go ~off policy while waiting for weights to sync (especially on rollouts with very large variety of lengths)
Some other fun details:
- BF16 training, FP8 inference
- Data buffer uses what i think is standard OpenAI compatible endpoints to run prompts
(vv similar to magistral)
They find "different RL tasks benefit from different scheduling approaches".
- Code and Math: Keeping training and inference engines on the same worker is best since this maximizes utilisation.
- Agent: Keep training and inference separate to maximise environment throughput. This is pretty standard async RL where you go ~off policy while waiting for weights to sync (especially on rollouts with very large variety of lengths)
Some other fun details:
- BF16 training, FP8 inference
- Data buffer uses what i think is standard OpenAI compatible endpoints to run prompts
(vv similar to magistral)
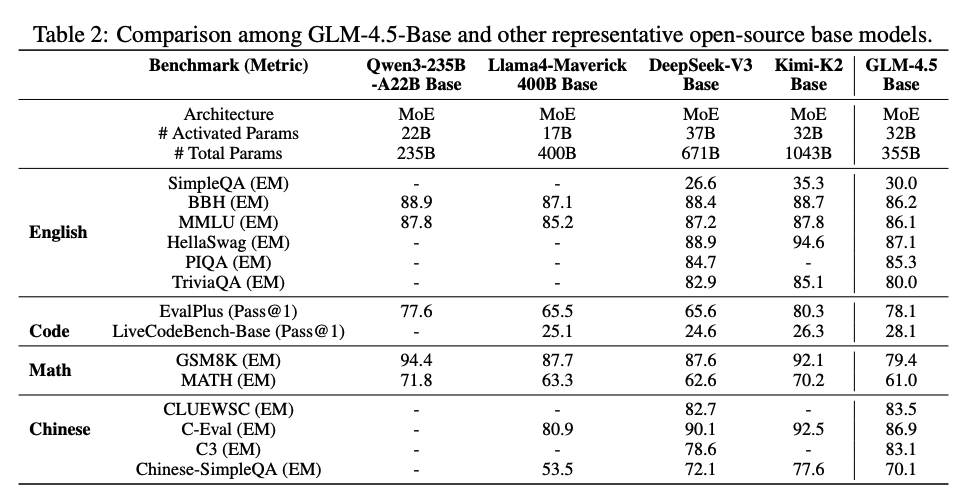
For evaluation, they first evaluate the base models on English, Chinese, Code and Math.
It actually looks like K2 is the best base here and is likely the best option for fine tuning if you have the compute for it.
It actually looks like K2 is the best base here and is likely the best option for fine tuning if you have the compute for it.
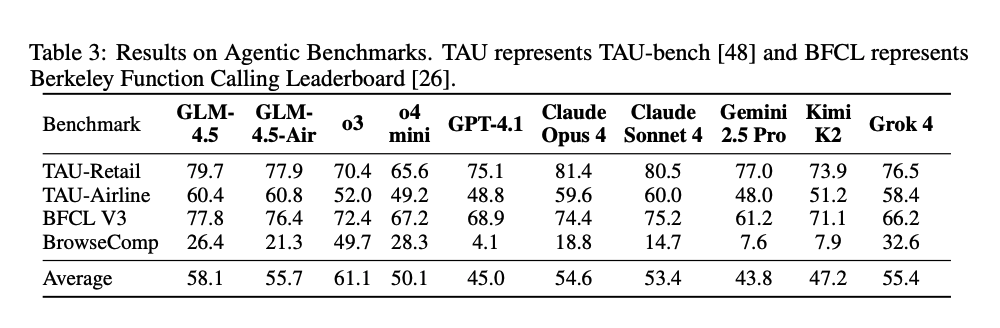
On Agentic evaluation, they only lose to o3. In fact, the gap between them and o3 is bigger than the gap between them and the next best model (opus).
These benchmarks are actually pretty good. But if you ask me to weigh the individual scores based on how much i care about each benchmark, I think o3 then GLM is similar to the Claudes.
These benchmarks are actually pretty good. But if you ask me to weigh the individual scores based on how much i care about each benchmark, I think o3 then GLM is similar to the Claudes.
I dont care for any of these reasoning benchmarks and you shouldnt too. The next set is slightly better than the previous set but still generally low signal.
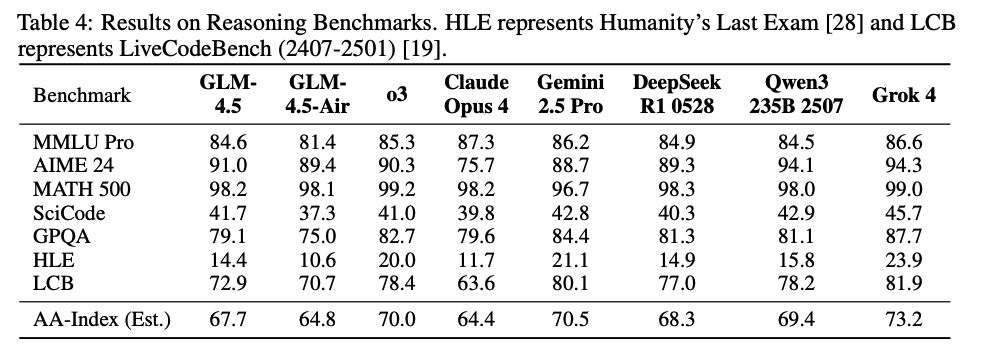
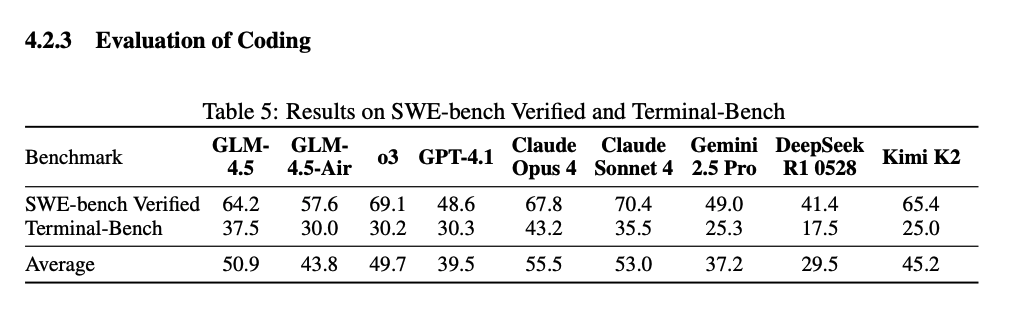
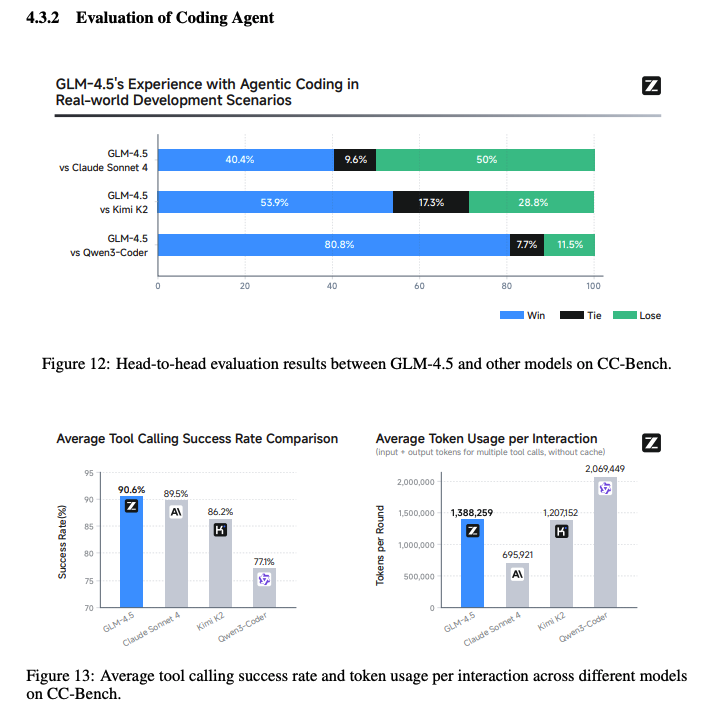
For coding, I think its similar to K2 still behind the Claudes. They also evaluate on a new benchmark which measures how good models are at using Claude Code (huggingface.co/datasets/zai-o… love this)
It has the highest tool calling success which is great. But the fact that Claude still has the lowest token usage (even tho the oss models are a fraction of the per token cost) makes me think the oss models could be doom looping or just needing to correct more wrong decisions
It has the highest tool calling success which is great. But the fact that Claude still has the lowest token usage (even tho the oss models are a fraction of the per token cost) makes me think the oss models could be doom looping or just needing to correct more wrong decisions
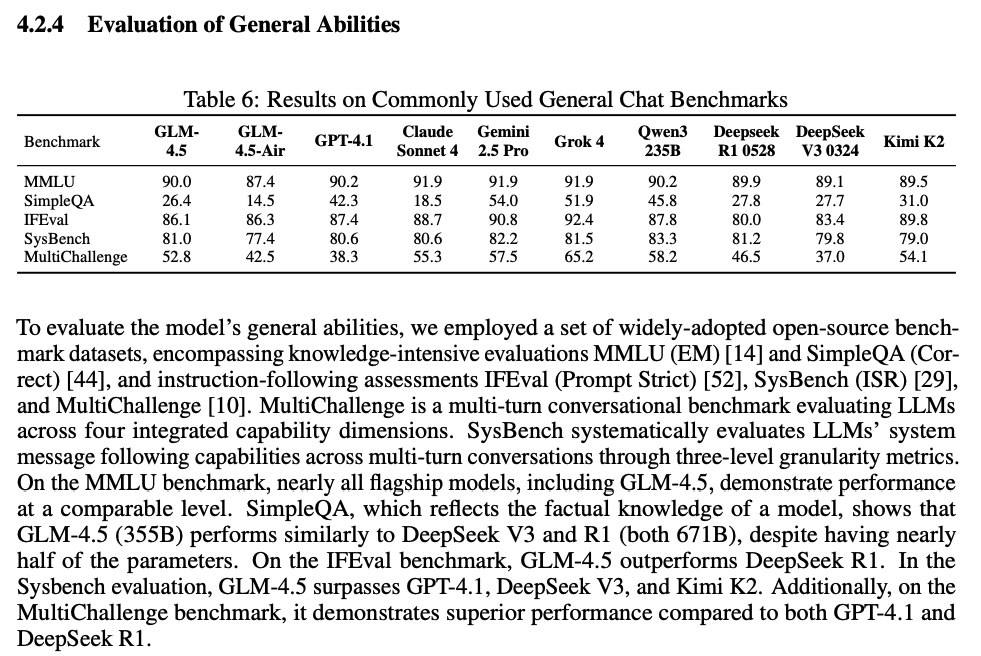
Other miscellanous evaluations. I dont really know what to take from here? especially since we dont even know what the prompts or data looks like so take what you wish
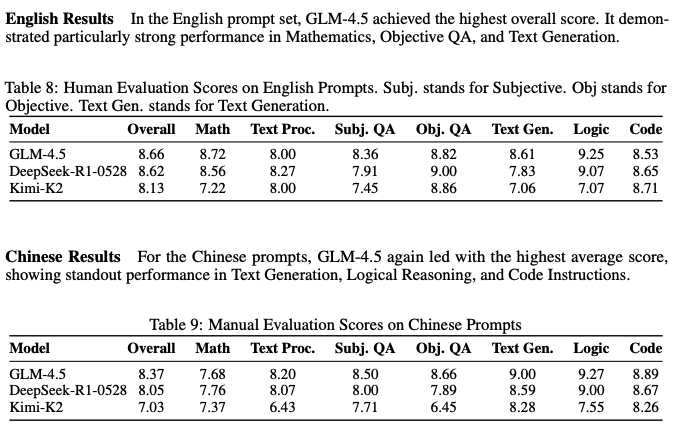
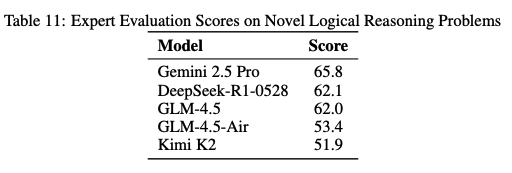
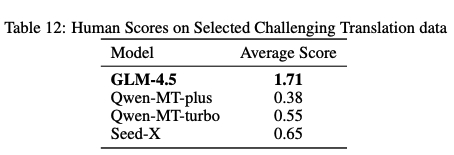
First, the evals say its a good model, i have used it and i think its a good model and people i trust have used it and said its a good model.
The paper is also great. I think they focused more on breadth here rather than more indepth details. I would like to have more info on certain parts and details but I guess this paper can serve as sort of a general recipe or glossary.
I do wonder if theres anything special here because it didnt feel like they did anything unique or special beyond good execution. But there again, if there was would they put it in the paper?
1 thing i liked is the attention head thing which i think is pretty cool to see loss results with Kimi's experiments match up but always check downstream results.
Another thing i wonder if doing single turn RLVR first before doing agentic RL helps performance and if this can be a further way to push K2 for eg.
The main thing I want to know is on the hybrid reasoners. There wasnt much talk about evals related to this hybrid behavior and the decisions behind it. I think its important since Qwen got rid of the hybrid in exchange for 2 separate models and OpenAI kind of did the same thing for GPT5. I wonder if the team has any insights here.
The paper is also great. I think they focused more on breadth here rather than more indepth details. I would like to have more info on certain parts and details but I guess this paper can serve as sort of a general recipe or glossary.
I do wonder if theres anything special here because it didnt feel like they did anything unique or special beyond good execution. But there again, if there was would they put it in the paper?
1 thing i liked is the attention head thing which i think is pretty cool to see loss results with Kimi's experiments match up but always check downstream results.
Another thing i wonder if doing single turn RLVR first before doing agentic RL helps performance and if this can be a further way to push K2 for eg.
The main thing I want to know is on the hybrid reasoners. There wasnt much talk about evals related to this hybrid behavior and the decisions behind it. I think its important since Qwen got rid of the hybrid in exchange for 2 separate models and OpenAI kind of did the same thing for GPT5. I wonder if the team has any insights here.
• • •
Missing some Tweet in this thread? You can try to
force a refresh