 The main idea is to replace the middle layer FFN with a "KV Cache". Each query token then selects the top K keys and values to compute something that looks like dot product attention
The main idea is to replace the middle layer FFN with a "KV Cache". Each query token then selects the top K keys and values to compute something that looks like dot product attention 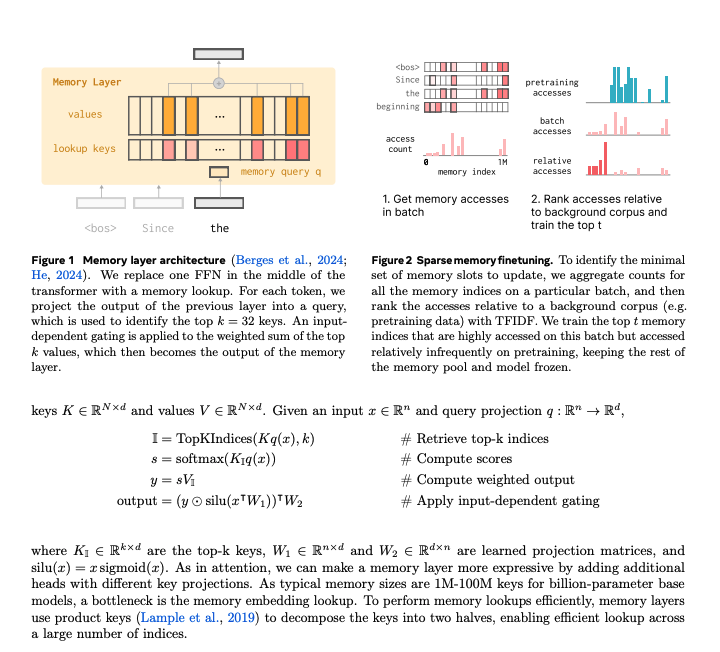
 1) Architecture
1) Architecture 

 The main idea is to learn two tasks. Given input A, learn output B. To verify the quality of the output B, the model tries to reconstruct the input A'. The quality of the output is then evaluated based on how similar A and A' is.
The main idea is to learn two tasks. Given input A, learn output B. To verify the quality of the output B, the model tries to reconstruct the input A'. The quality of the output is then evaluated based on how similar A and A' is. 

 The main interesting thing about architecture is its load balancing. No aux loss and they use expert biases where they add a bias to the expert scores. The bias is then adjusted after each step to over/undercorrect the load balancing
The main interesting thing about architecture is its load balancing. No aux loss and they use expert biases where they add a bias to the expert scores. The bias is then adjusted after each step to over/undercorrect the load balancing 

 2) An attention sink () for each of the attention heads
2) An attention sink () for each of the attention heads 
 The first section is about Pretraining. Basic info about the model:
The first section is about Pretraining. Basic info about the model: 2) There is an internal (?) experiment that validated 384 experts (from 256 dsv3). I dont fully understand the translation here but I think they find that increasing number of experts by 50% doesn't impact scaling as long as total activate parameters is constant (so increased sparsity is fine)
2) There is an internal (?) experiment that validated 384 experts (from 256 dsv3). I dont fully understand the translation here but I think they find that increasing number of experts by 50% doesn't impact scaling as long as total activate parameters is constant (so increased sparsity is fine)
 The 1st part talks about Mistral's changes to GRPO
The 1st part talks about Mistral's changes to GRPO
 Important to start with some context about Cohere. They aren't trying to train frontier models like Meta/OpenAI/Anthropic. They focus on training models that are intelligent but specifically for enterprise tasks like RAG and multilingualism which can still be efficiently served (on premise)
Important to start with some context about Cohere. They aren't trying to train frontier models like Meta/OpenAI/Anthropic. They focus on training models that are intelligent but specifically for enterprise tasks like RAG and multilingualism which can still be efficiently served (on premise)
 Quick overview on what has been done to train an o1-like model:
Quick overview on what has been done to train an o1-like model: This is the image that has been going around so you probably know how nuts this is but some added context is that Llama 3 405B was trained on 16K H100
This is the image that has been going around so you probably know how nuts this is but some added context is that Llama 3 405B was trained on 16K H100 
 A quick primer on why this is difficult and why we cannot just train on bytes naively. If we wanted to get rid of arbitrary tokenization/segmentation of input sequences, training on bytes is not that straightforward.
A quick primer on why this is difficult and why we cannot just train on bytes naively. If we wanted to get rid of arbitrary tokenization/segmentation of input sequences, training on bytes is not that straightforward.
 The left figure is what they call "reasoning in embedding" space. A sentence with 7 words can be summarized into 2 by clustering them based on semantic similarity. Note that this would theoretically work even if the sentences are in diff languages or not even "sentences" at all but other modalities like images
The left figure is what they call "reasoning in embedding" space. A sentence with 7 words can be summarized into 2 by clustering them based on semantic similarity. Note that this would theoretically work even if the sentences are in diff languages or not even "sentences" at all but other modalities like images
 The idea is pretty straightforward. Instead of mapping back out to token space using lm_head, just concat the output hidden state with the input_embeddings
The idea is pretty straightforward. Instead of mapping back out to token space using lm_head, just concat the output hidden state with the input_embeddings 
 Traditional autoregressive approaches use a tokenisation method such as vqvae or a vit style raster scan. The paper claims that an image patch is naturally related to all patches around it but these approaches enforce a unidirectional approach.
Traditional autoregressive approaches use a tokenisation method such as vqvae or a vit style raster scan. The paper claims that an image patch is naturally related to all patches around it but these approaches enforce a unidirectional approach.
 In language modelling given a prompt x, we want to sample from the distribution q(y|x) to get the token sequence y with the highest conditional probability.
In language modelling given a prompt x, we want to sample from the distribution q(y|x) to get the token sequence y with the highest conditional probability. 
 They define "Shallow Safety Alignment" where llms are likely to refuse unsafe prompts primarily through a refusal prefix "I cannot" etc.
They define "Shallow Safety Alignment" where llms are likely to refuse unsafe prompts primarily through a refusal prefix "I cannot" etc. 
 Claude's chat template is unlike basically all other frontier models. The key idea is that it treats a conversation as a series of user-assistant message pairs
Claude's chat template is unlike basically all other frontier models. The key idea is that it treats a conversation as a series of user-assistant message pairs 
 Another example with 3 models trained on CIFAR 10
Another example with 3 models trained on CIFAR 10 
 I try to peel away many of PyTorch's abstractions, like how Tensors are implemented, how to think about broadcasting and how to build intuitions around backpropagation
I try to peel away many of PyTorch's abstractions, like how Tensors are implemented, how to think about broadcasting and how to build intuitions around backpropagation 