The best explanation of LLMs I've ever seen is in this new book.
"Foundations of LLMs 2025."
I've summarized the core concepts into a thread you can read in 3 minutes.
Finally, it all makes sense.
"Foundations of LLMs 2025."
I've summarized the core concepts into a thread you can read in 3 minutes.
Finally, it all makes sense.

To understand LLMs, start with pre-training.
We don’t teach them specific tasks.
We flood them with raw text and let them discover patterns on their own.
This technique is called self-supervised learning and it’s the foundation of everything.
We don’t teach them specific tasks.
We flood them with raw text and let them discover patterns on their own.
This technique is called self-supervised learning and it’s the foundation of everything.
There are 3 ways to pre-train:
→ Unsupervised: No labels at all
→ Supervised: Classic labeled data
→ Self-supervised: Model creates its own labels (e.g., “guess the missing word”)
LLMs use #3 it scales like crazy and teaches them language from scratch.
→ Unsupervised: No labels at all
→ Supervised: Classic labeled data
→ Self-supervised: Model creates its own labels (e.g., “guess the missing word”)
LLMs use #3 it scales like crazy and teaches them language from scratch.
Example of self-supervised learning:
“The early bird catches the worm.”
Mask some words:
→ “The [MASK] bird catches the [MASK]”
The model’s job? Fill in the blanks.
No human labels. The text is the supervision.
“The early bird catches the worm.”
Mask some words:
→ “The [MASK] bird catches the [MASK]”
The model’s job? Fill in the blanks.
No human labels. The text is the supervision.

This leads to 3 main model types:
→ Encoder-only (BERT): Understands text
→ Decoder-only (GPT): Generates next word
→ Encoder-decoder (T5): Translates input to output
Each has strengths. Think of them as different tools for different jobs.
→ Encoder-only (BERT): Understands text
→ Decoder-only (GPT): Generates next word
→ Encoder-decoder (T5): Translates input to output
Each has strengths. Think of them as different tools for different jobs.
Let’s break it down further.
Decoder-only (GPT-style):
Trained to guess the next word:
“The cat sat on the ___” → “mat”
This is called causal language modeling.
Loss is measured by how wrong the guesses are (cross-entropy).
Decoder-only (GPT-style):
Trained to guess the next word:
“The cat sat on the ___” → “mat”
This is called causal language modeling.
Loss is measured by how wrong the guesses are (cross-entropy).
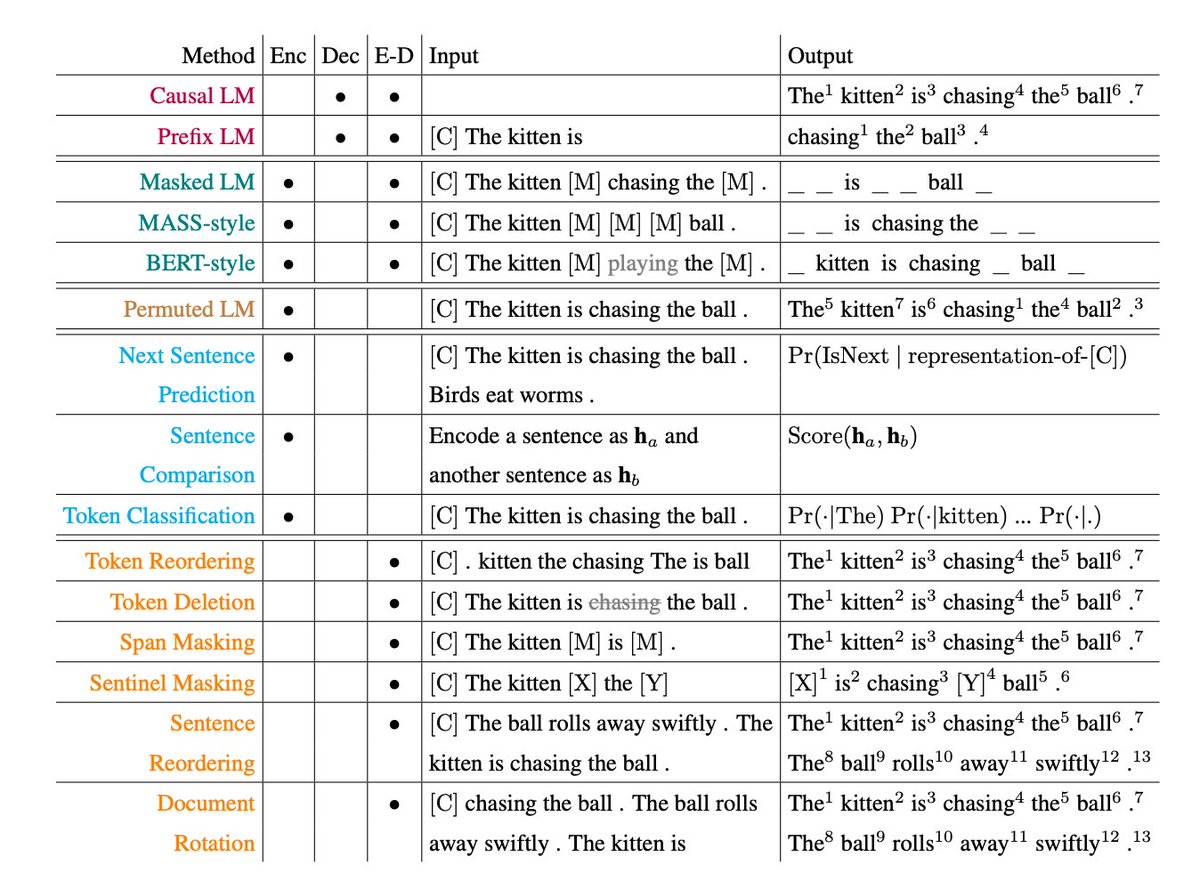
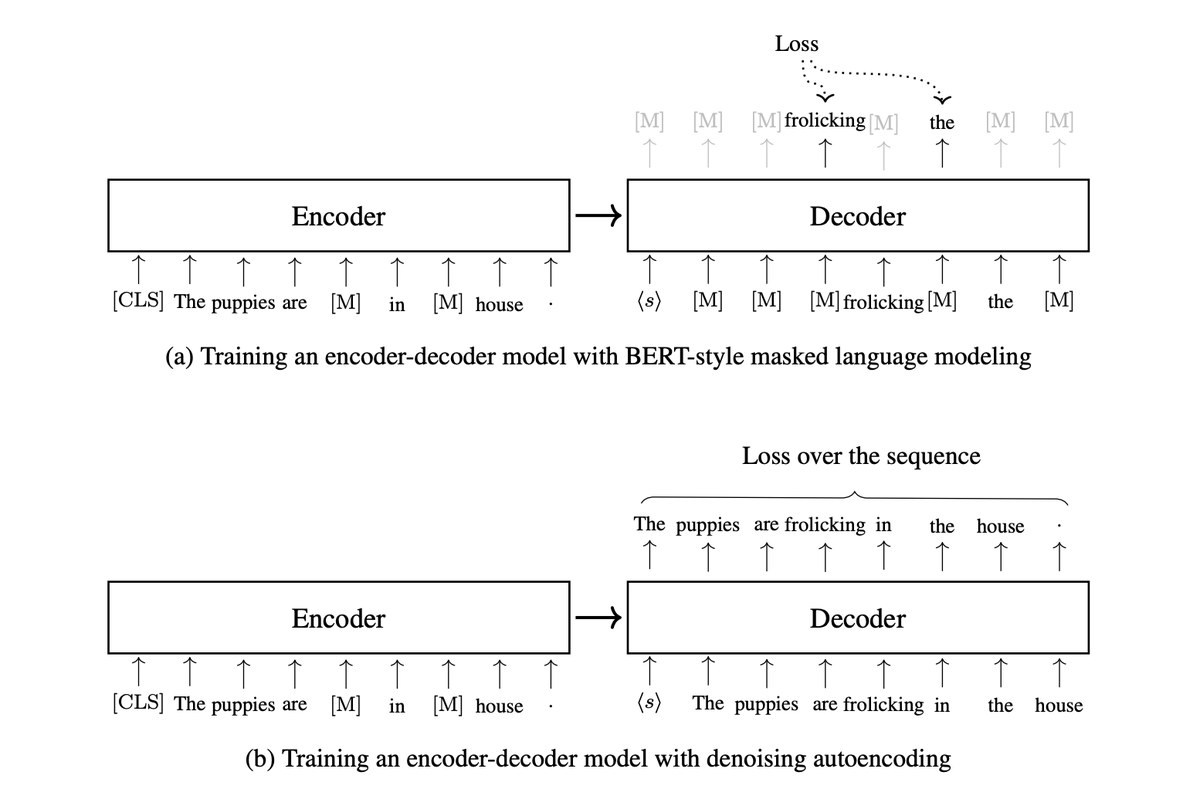
Encoder-only (BERT-style):
Takes the whole sentence.
Randomly hides some words and tries to reconstruct them.
This is masked language modeling uses left and right context.
Great for understanding, not generation.
Takes the whole sentence.
Randomly hides some words and tries to reconstruct them.
This is masked language modeling uses left and right context.
Great for understanding, not generation.
Example:
Original:
→ “The early bird catches the worm”
Masked:
→ “The [MASK] bird catches the [MASK]”
The model predicts “early” and “worm” by understanding the whole sentence.
It’s learning language by solving puzzles.
Original:
→ “The early bird catches the worm”
Masked:
→ “The [MASK] bird catches the [MASK]”
The model predicts “early” and “worm” by understanding the whole sentence.
It’s learning language by solving puzzles.
Encoder-decoder (T5, BART):
Treats everything as a text-to-text task.
Examples:
“Translate English to German: hello” → “hallo”
“Sentiment: I hate this” → “negative”
This setup lets one model do it all: QA, summarization, translation, etc.
Treats everything as a text-to-text task.
Examples:
“Translate English to German: hello” → “hallo”
“Sentiment: I hate this” → “negative”
This setup lets one model do it all: QA, summarization, translation, etc.
Once pre-trained, we have two options:
→ Fine-tune it on a labeled dataset
→ Prompt it cleverly to do new tasks
Fine-tuning adjusts weights.
Prompting? Just tweaks the input text.
Let’s dive into the magic of prompts.
→ Fine-tune it on a labeled dataset
→ Prompt it cleverly to do new tasks
Fine-tuning adjusts weights.
Prompting? Just tweaks the input text.
Let’s dive into the magic of prompts.
Prompting = carefully phrasing input so the model does what you want.
Example:
“I love this movie. Sentiment:”
It’ll likely respond: “positive”
Add a few examples before it? That’s in-context learning no fine-tuning needed.
Example:
“I love this movie. Sentiment:”
It’ll likely respond: “positive”
Add a few examples before it? That’s in-context learning no fine-tuning needed.
Prompting gets deep.
Advanced strategies:
• Chain of thought → “Let’s think step by step...”
• Decomposition → Break complex tasks into parts
• Self-refinement → Ask the model to critique itself
• RAG → Let it fetch real-time data from external sources
Advanced strategies:
• Chain of thought → “Let’s think step by step...”
• Decomposition → Break complex tasks into parts
• Self-refinement → Ask the model to critique itself
• RAG → Let it fetch real-time data from external sources

This is all possible because of the way these models are trained: predict the next word over and over until they internalize language structure, reasoning patterns, and world knowledge.
It's not magic. it's scale.
It's not magic. it's scale.
But raw intelligence isn’t enough.
We need models to align with human goals.
That’s where alignment comes in.
It happens in two major phases after pretraining 👇
We need models to align with human goals.
That’s where alignment comes in.
It happens in two major phases after pretraining 👇
Supervised Fine-Tuning (SFT)
Feed the model good human responses. Let it learn how we want it to reply.
RLHF (Reinforcement Learning w/ Human Feedback)
Train a reward model to prefer helpful answers. Use it to steer the LLM.
This is how ChatGPT was aligned.
RLHF is powerful but tricky.
Newer methods like Direct Preference Optimization (DPO) are rising fast.
Why?
They skip the unstable reward modeling of RL and go straight to optimizing for preferences.
More stable. More scalable.
Feed the model good human responses. Let it learn how we want it to reply.
RLHF (Reinforcement Learning w/ Human Feedback)
Train a reward model to prefer helpful answers. Use it to steer the LLM.
This is how ChatGPT was aligned.
RLHF is powerful but tricky.
Newer methods like Direct Preference Optimization (DPO) are rising fast.
Why?
They skip the unstable reward modeling of RL and go straight to optimizing for preferences.
More stable. More scalable.
Inference how the model runs is just as important as training.
To serve real-time outputs, we use tricks like:
→ Top-k / nucleus sampling
→ Caching past tokens
→ Batching requests
→ Memory-efficient attention
These make LLMs usable at scale.
To serve real-time outputs, we use tricks like:
→ Top-k / nucleus sampling
→ Caching past tokens
→ Batching requests
→ Memory-efficient attention
These make LLMs usable at scale.
So how do LLMs really work?
Trained on massive text
Predict the next word millions of times
Use Transformers to encode dependencies
Adapt via prompting or fine-tuning
Aligned to human preferences
Served with smart inference
Trained on massive text
Predict the next word millions of times
Use Transformers to encode dependencies
Adapt via prompting or fine-tuning
Aligned to human preferences
Served with smart inference
this was based on the brilliant textbook:
"Foundations of Large Language Models" by Tong Xiao and Jingbo Zhu (NiuTrans Research Lab)
arxiv:
highly recommend it if you're serious about understanding LLMs deeply.arxiv.org/abs/2501.09223…
"Foundations of Large Language Models" by Tong Xiao and Jingbo Zhu (NiuTrans Research Lab)
arxiv:
highly recommend it if you're serious about understanding LLMs deeply.arxiv.org/abs/2501.09223…
90% of customers expect instant replies.
Most businesses? Still responding days later.
Meet Droxy AI: Your 24/7 AI employee:
• Handles calls, chats, comments
• Speaks 95+ languages
• Feels human
• Costs $20/mo
Start automating:
try.droxy.ai/now
Most businesses? Still responding days later.
Meet Droxy AI: Your 24/7 AI employee:
• Handles calls, chats, comments
• Speaks 95+ languages
• Feels human
• Costs $20/mo
Start automating:
try.droxy.ai/now
I hope you've found this thread helpful.
Follow me @alxnderhughes for more.
Like/Repost the quote below if you can:
Follow me @alxnderhughes for more.
Like/Repost the quote below if you can:
https://twitter.com/1927203051263184896/status/1955209296465236256
• • •
Missing some Tweet in this thread? You can try to
force a refresh