OpenAI hasn’t open-sourced a base model since GPT-2 in 2019. they recently released GPT-OSS, which is reasoning-only...
or is it?
turns out that underneath the surface, there is still a strong base model. so we extracted it.
introducing gpt-oss-20b-base 🧵
or is it?
turns out that underneath the surface, there is still a strong base model. so we extracted it.
introducing gpt-oss-20b-base 🧵

if you're not familiar with base models: here are some samples comparing our new model to the original!
we basically reversed the alignment part of LLM training, so we have something that produces natural-looking text again.
the outputs can be pretty random 🤷♂️
we basically reversed the alignment part of LLM training, so we have something that produces natural-looking text again.
the outputs can be pretty random 🤷♂️

ALIGNMENT
turning gpt-oss back into a base model appears to have trivially reversed its alignment
it will tell us how to build a bomb. it will list all the curse words it knows. it will plan a robbery for me.
turning gpt-oss back into a base model appears to have trivially reversed its alignment
it will tell us how to build a bomb. it will list all the curse words it knows. it will plan a robbery for me.

MEMORIZATION
after basemodelization, we can trivially test GPT-OSS for memorization by prompting it with strings from copyrighted materials and checking the outputs
in my short tests i found 3/6 excerpts from books to be memorized 😳
gpt-oss *definitely* knows harry potter...
after basemodelization, we can trivially test GPT-OSS for memorization by prompting it with strings from copyrighted materials and checking the outputs
in my short tests i found 3/6 excerpts from books to be memorized 😳
gpt-oss *definitely* knows harry potter...

some backstory:
so last thursday and friday night i was trying the wrong approach, jailbreaking
i wanted to discover a prompt that would trick the model into becoming a base model again
this might be possible but seems really hard; the surface-level alignment is pretty strong
so last thursday and friday night i was trying the wrong approach, jailbreaking
i wanted to discover a prompt that would trick the model into becoming a base model again
this might be possible but seems really hard; the surface-level alignment is pretty strong
the other day i was chatting with @johnschulman2 and received an excellent suggestion:
why not frame this 'alignment reversal' as optimization?
we can use a subset of web text to search for the smallest possible model update that makes gpt-oss behave as a base model
why not frame this 'alignment reversal' as optimization?
we can use a subset of web text to search for the smallest possible model update that makes gpt-oss behave as a base model
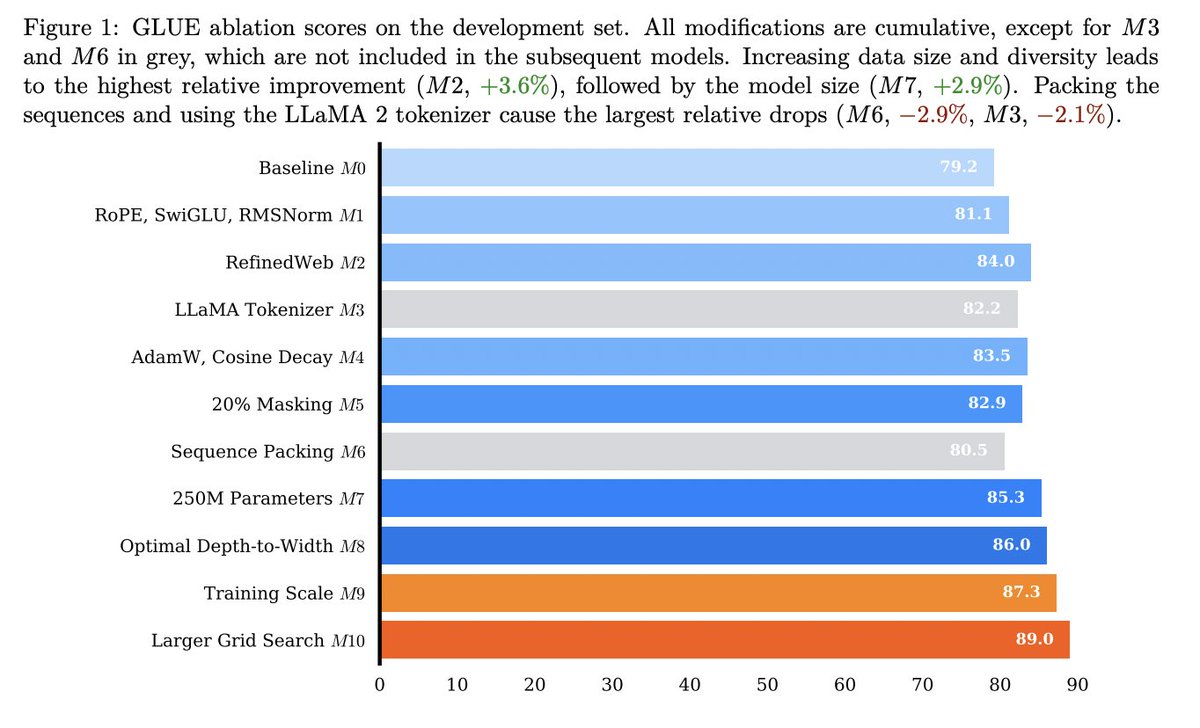
Principle 1. Low-rankedness
there’s a commonly shared idea that pretraining is how all the information is stored in model weights, and alignment/RL simply focuses the output distribution on a very narrow subset of outputs that are good for conversation (and reasoning)
so if this is true, then the gpt-oss model is only a small update away from its original pretrained model weights
in other words: there exists some sufficiently low-rank update in the direction of pretraining that can “reverse” the post-training process
there’s a commonly shared idea that pretraining is how all the information is stored in model weights, and alignment/RL simply focuses the output distribution on a very narrow subset of outputs that are good for conversation (and reasoning)
so if this is true, then the gpt-oss model is only a small update away from its original pretrained model weights
in other words: there exists some sufficiently low-rank update in the direction of pretraining that can “reverse” the post-training process
Principle 2. Data Agnosticism
additionally we need to remember that we’re trying restore the capability of the original model–NOT continue pretraining it. we don’t want the model to learn anything new. we want it to enable freetext generation again
so it doesn’t matter what data we use as long as it’s resemblant of typical pretraining. i chose FineWeb because it’s open relatively high-quality and i already had it downloaded. we only use 20,000 documents or so
so practically we apply a very tiny low-rank LoRA to just a few linear layers and train with data of the form “ ….” as in typical pretraining.
additionally we need to remember that we’re trying restore the capability of the original model–NOT continue pretraining it. we don’t want the model to learn anything new. we want it to enable freetext generation again
so it doesn’t matter what data we use as long as it’s resemblant of typical pretraining. i chose FineWeb because it’s open relatively high-quality and i already had it downloaded. we only use 20,000 documents or so
so practically we apply a very tiny low-rank LoRA to just a few linear layers and train with data of the form “

by the way, the open tools for finetuning arbitrary MoEs are horrible
i ended up using HF but it can only train in bf16 and crashes often. so i wrote a harness that checkpoints training frequently and skips batches that activate too many experts and OOM
this worked. but i felt bad about it.
i ended up using HF but it can only train in bf16 and crashes often. so i wrote a harness that checkpoints training frequently and skips batches that activate too many experts and OOM
this worked. but i felt bad about it.
https://x.com/jxmnop/status/1954931353939501461
now go download the model on HF
prompt it! align it! finetune it!
if you notice any bugs, letmeknow
huggingface.co/jxm/gpt-oss-20…
prompt it! align it! finetune it!
if you notice any bugs, letmeknow
huggingface.co/jxm/gpt-oss-20…

> disclaimer
i have no idea about the real training of gpt-oss, i dont work for openAI, i have no insider info whatsoever
> assumptions
they probably did standard pre, mid, and post-training with open and synthetic data
i have no idea about the real training of gpt-oss, i dont work for openAI, i have no insider info whatsoever
> assumptions
they probably did standard pre, mid, and post-training with open and synthetic data
PS. here are two weird things that surprised me
1. the alignment still holds when you trick the base model into acting like an assistant by writing "Human: ... Assistant: ..."
2. somehow the model still can *be* an assistant if you go back to using the chat template. it still reasons fine
i guess LoRA really is low-rank...
1. the alignment still holds when you trick the base model into acting like an assistant by writing "Human: ... Assistant: ..."
2. somehow the model still can *be* an assistant if you go back to using the chat template. it still reasons fine
i guess LoRA really is low-rank...

thanks @johnschulman2 for the great idea and thanks @srush_nlp for the GPUS :-)
some fun future work
- generate from this model to check more thoroughly for memorization
- try the 120B version
- try instruction-tuning
- compare to other base models via 'model diffing'
- compare to GPT-{2, 3}
some fun future work
- generate from this model to check more thoroughly for memorization
- try the 120B version
- try instruction-tuning
- compare to other base models via 'model diffing'
- compare to GPT-{2, 3}
@johnschulman2 @srush_nlp what do u think @sama?
• • •
Missing some Tweet in this thread? You can try to
force a refresh