
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳
- 3B LLMs beat 8B models🚀
- Pareto frontier for performance
- 3B LLMs beat 8B models🚀
- Pareto frontier for performance
2/Synthetic data has been the rage with all frontier models (Qwen3, KimiK2, GPT5) using large amounts of synth data. But there is little science. We’ve been working on this for 2+yrs & we are excited to share BeyondWeb.
Blog: blog.datologyai.com/beyondweb
Arxiv: arxiv.org/abs/2508.10975
Blog: blog.datologyai.com/beyondweb
Arxiv: arxiv.org/abs/2508.10975
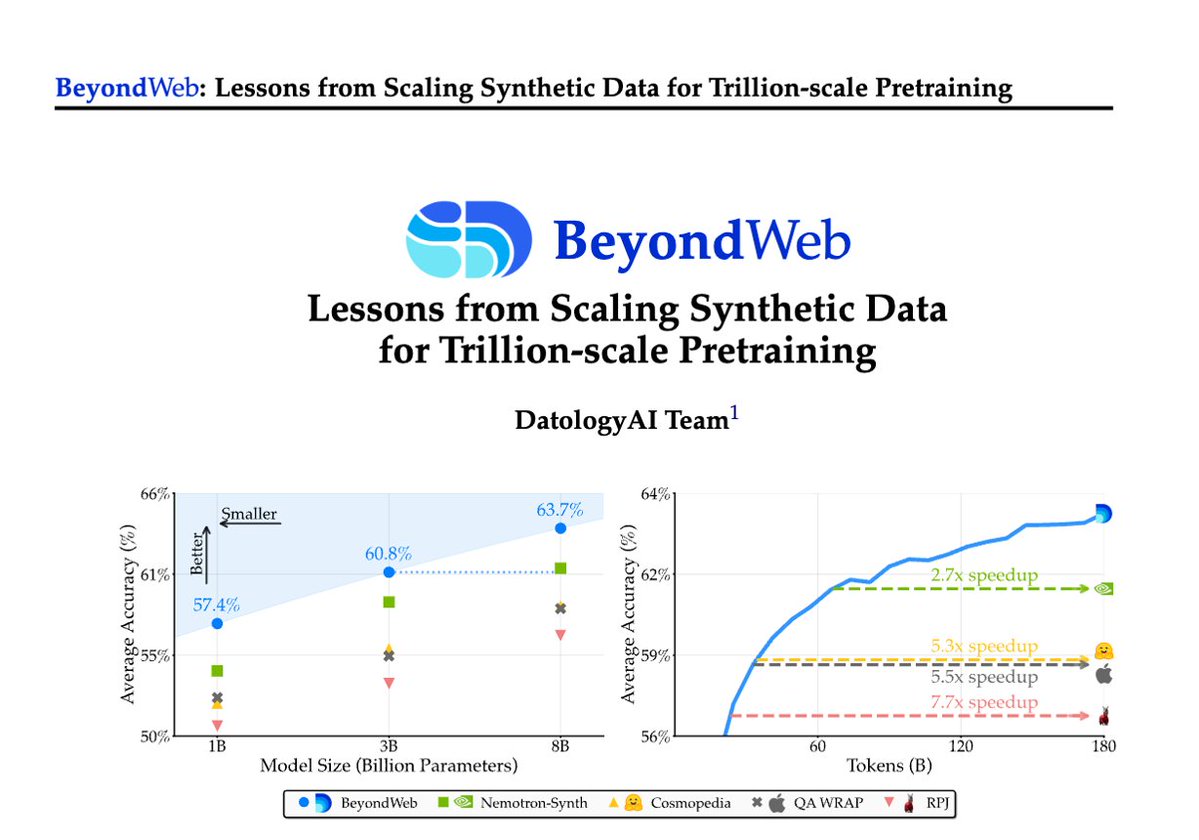
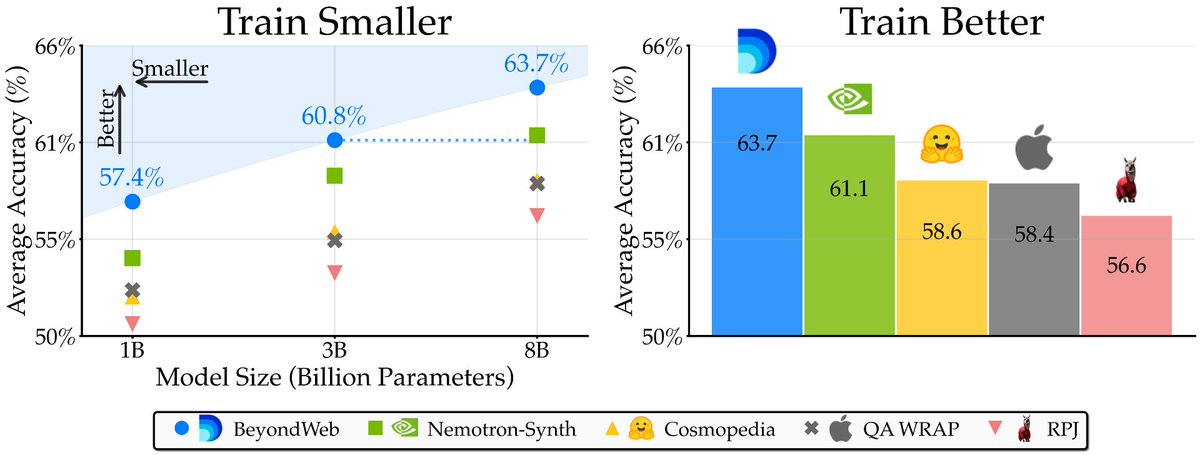
3/First, the results 📊 BeyondWeb outperforms the strongest baselines like Cosmopedia, WRAP by > 5.1% and Nemotron-Synth by 2.6%. And all of this, while slashing training time by more than half. In fact, our 3B LLMs outperform most 8B baselines!
4/Key insight: No one magic bullet solves synthetic data; naive approaches yield little benefit at huge costs. But thoughtful design, like targeted rephrasing of web docs, can exceed natural data. Let’s go deep into each of our learnings, posed as Research Questions (RQ)

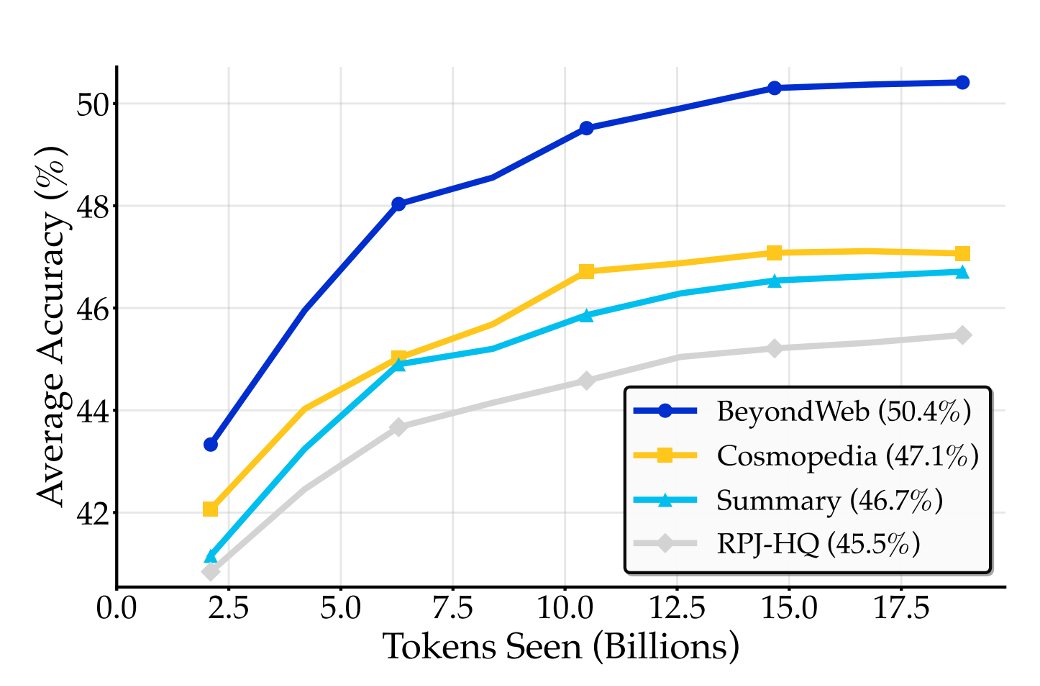
5/RQ #1: Is synthetic data just knowledge distillation? Generator-driven synthetic data (e.g., Cosmopedia) can be approximated by simple summarization. We ~match their perf with basic prompts that boost per-token info density. But BeyondWeb outperforms via intentional strategies
6/RQ #2: Can any synthetic data break the data wall? Synthetic data strategies such as naive continuations barely beat repeating data. The real gains come with thoughtful synthetic data that attempts to fill distributional gaps. BeyondWeb breaches the wall where others can't.

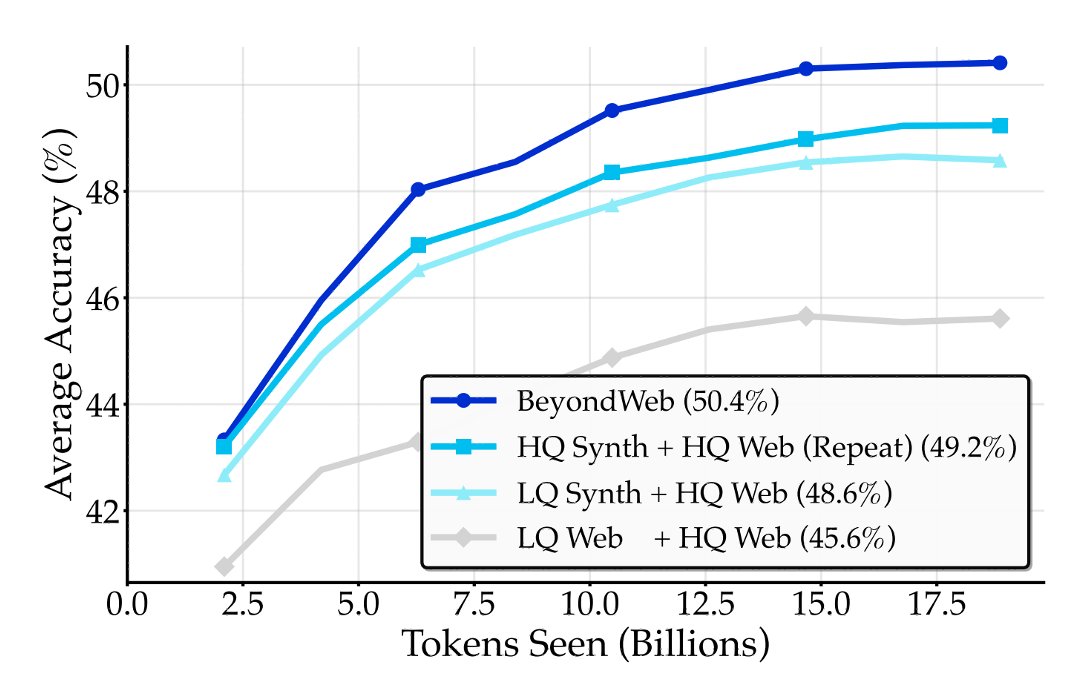
7/RQ #3: High Quality Seed Data >>>. Given limited high-quality data, it is more beneficial to use it as seed data for synthetic rephrasing rather than using low-quality data, despite the possible drawback of repeating knowledge from high-quality sources.
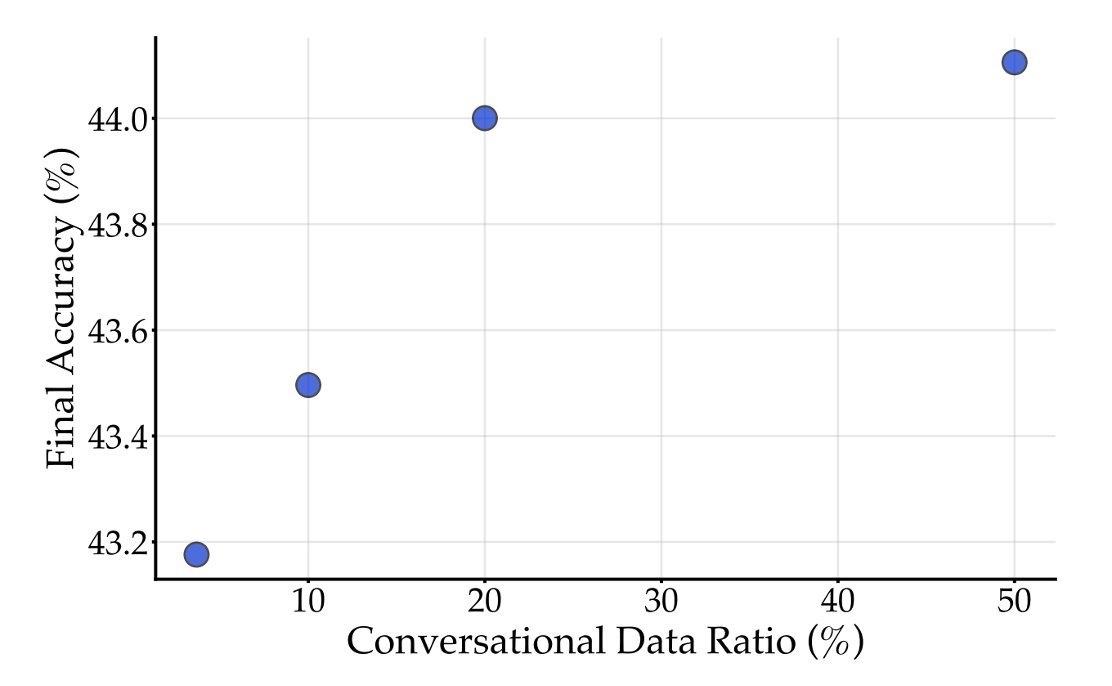
8/RQ #4: Style matching helps. Web data is only 2.7% conversational, but chat is among LLM's main use. Upsampling conversational styles improves downstream tasks; though gains saturate quickly. BeyondWeb aligns training styles with inference for better generalization.
9/RQ #5: Diversity sustains gains at scale. The gains from synthetic data can plateau first if the strategy is static (e.g., fixed textbook style). Diversity-focused approaches like BeyondWeb keep improving over trillions of tokens; critical for long-horizon training.

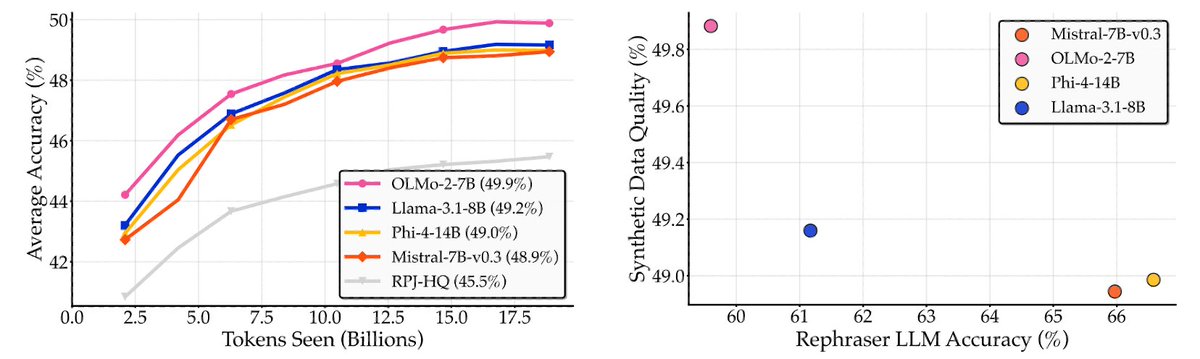
10/RQ #6: Most rephrasers are fine. (1) Synthetic data benefits are largely robust across rephraser model families. (2) Generator model quality is not predictive of synthetic data quality. It may sometimes be anti-correlated with the quality of synthetic data (think benchmaxxing)
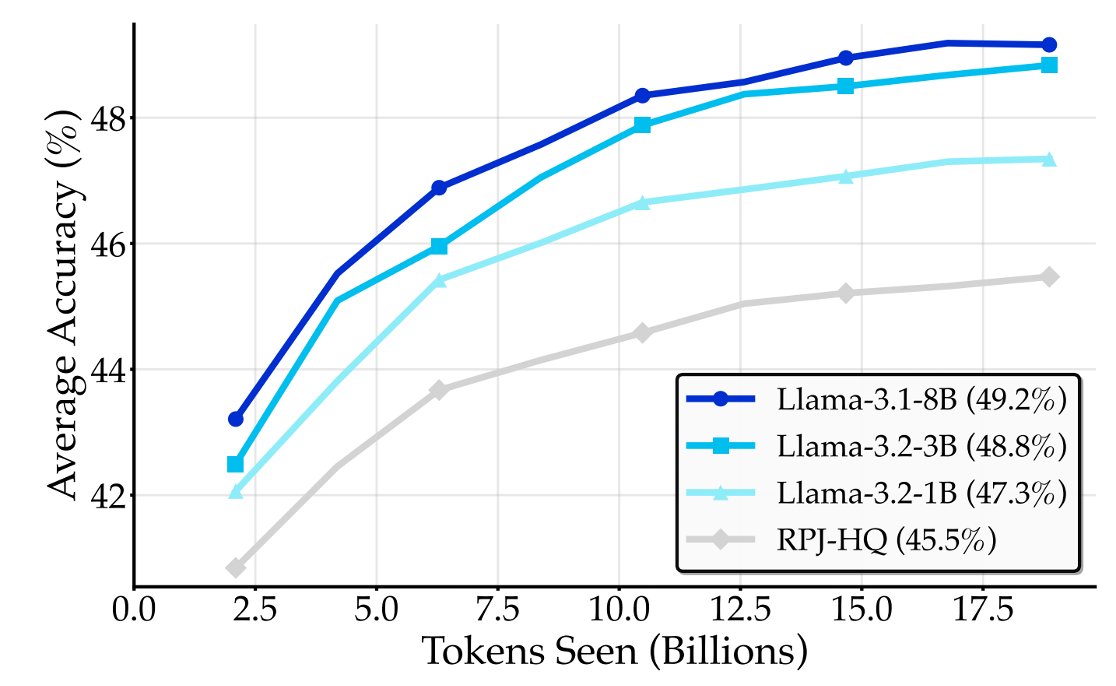
11/RQ #7: Small LLMs can be effective rephrasers. The quality of synthetic data increases when increasing rephraser size from 1B to 3B, then starts to saturate at 8B. The simplicity of rephrasing makes generator size less critical, enabling highly scalable synthetic pretraining.
12/Takeaway: There is no single magic wand that does synthetic data right. We need to jointly optimize for quality, style, diversity, and much more. BeyondWeb sets a new Pareto: train 7.7x faster than raw web, 2.7x faster than Nemotron-Synth.

13/ Implications: @datologyai is here to democratize high-quality synthetic data for all. We show a pathway for generating synthetic data cheaply at scale. We're part of curating 7T tokens for @arcee_ai 's AFM4.5B, which already shows our real-world wins!
https://x.com/LucasAtkins7/status/1950278100874645621
14/ Dive into the full post for recipes, benchmarks, and other cool experiments. Thanks to the @datologyai team, especially @leavittron and @VineethDorna, for their massive contributions that helped shape this up.
Arxiv: arxiv.org/abs/2508.10975
Blog: blog.datologyai.com/beyondweb
Arxiv: arxiv.org/abs/2508.10975
Blog: blog.datologyai.com/beyondweb
15/Needless to say, such a massive undertaking could not have been accomplished without a stellar engineering team that helped us scale our work to trillions of tokens. If you are excited about this, join us jobs.ashbyhq.com/DatologyAI

• • •
Missing some Tweet in this thread? You can try to
force a refresh




