
Data Quality x Privacy |
PhD @mldcmu | Founding Team @datologyai |
BTech @iitdelhi
🦋: https://t.co/LWId4rfbvQ
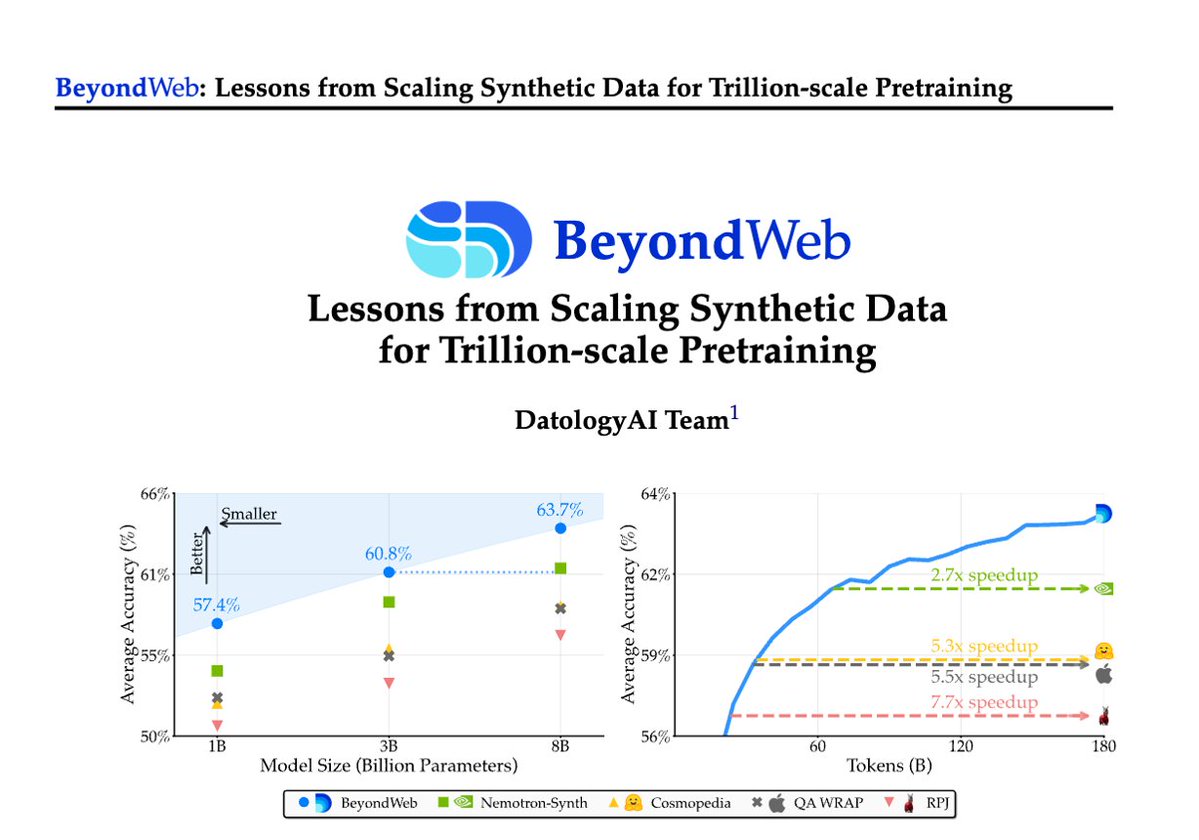 2/Synthetic data has been the rage with all frontier models (Qwen3, KimiK2, GPT5) using large amounts of synth data. But there is little science. We’ve been working on this for 2+yrs & we are excited to share BeyondWeb.
2/Synthetic data has been the rage with all frontier models (Qwen3, KimiK2, GPT5) using large amounts of synth data. But there is little science. We’ve been working on this for 2+yrs & we are excited to share BeyondWeb. 2/Let's first understand why this is hard: LLMs are trained on trillions of tokens, and usually for just one epoch. This means you likely see any data point only “once”. Models no longer overfit to the train set. This makes the long-studied problem of "membership inference" hard.
2/Let's first understand why this is hard: LLMs are trained on trillions of tokens, and usually for just one epoch. This means you likely see any data point only “once”. Models no longer overfit to the train set. This makes the long-studied problem of "membership inference" hard.