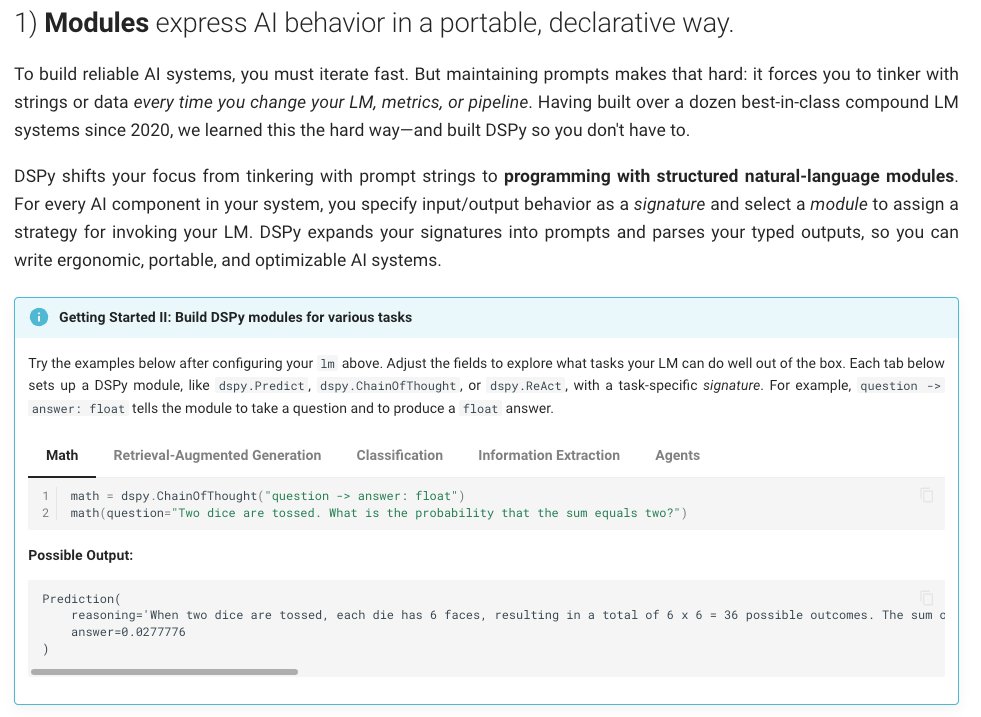
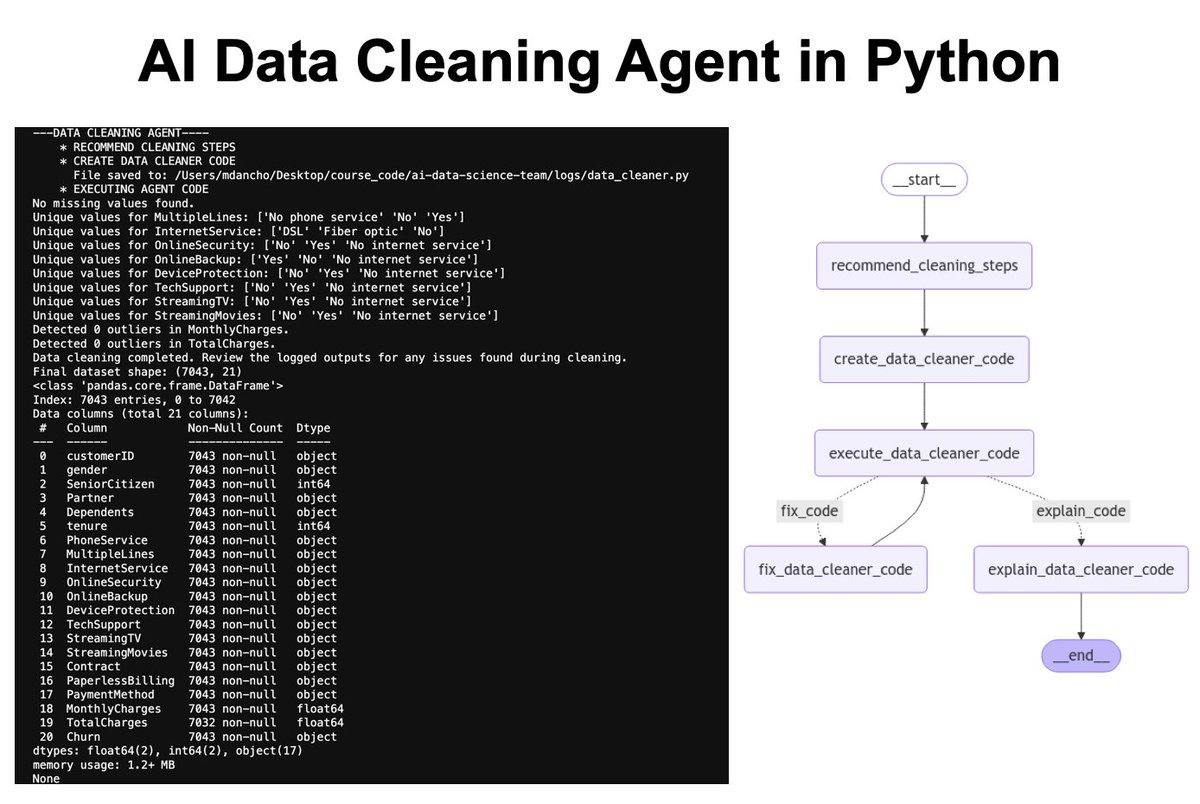
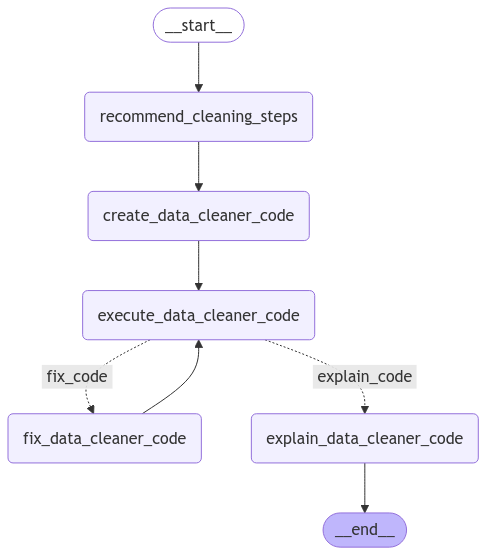
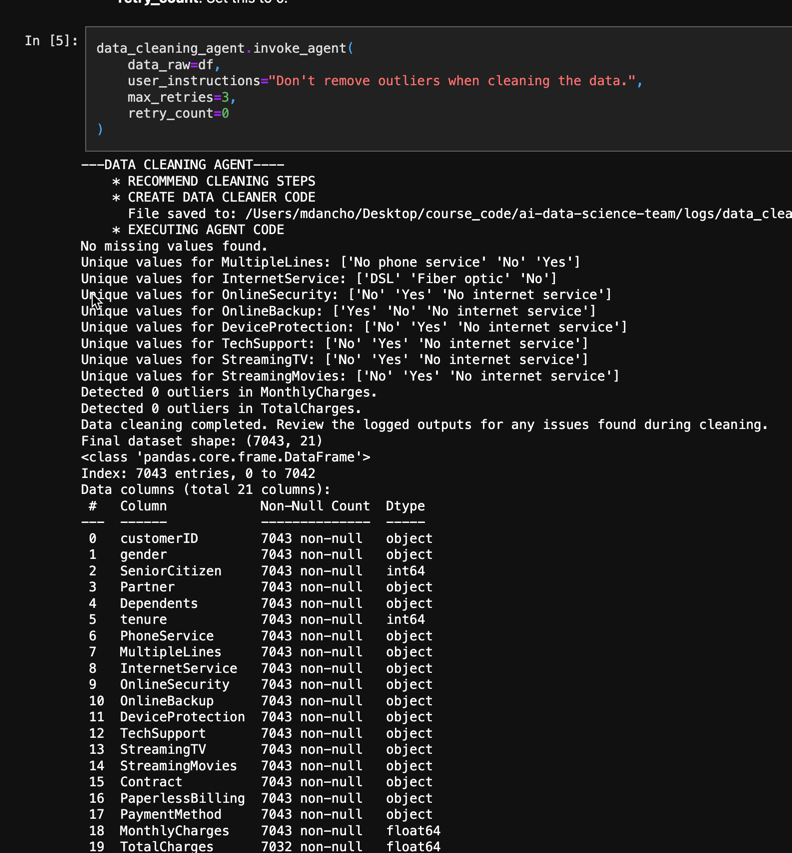
STOP DOING CUSTOMER SEGMENTATION WITH MACHINE LEARNING.
Start using AI.
This is how:
Start using AI.
This is how:
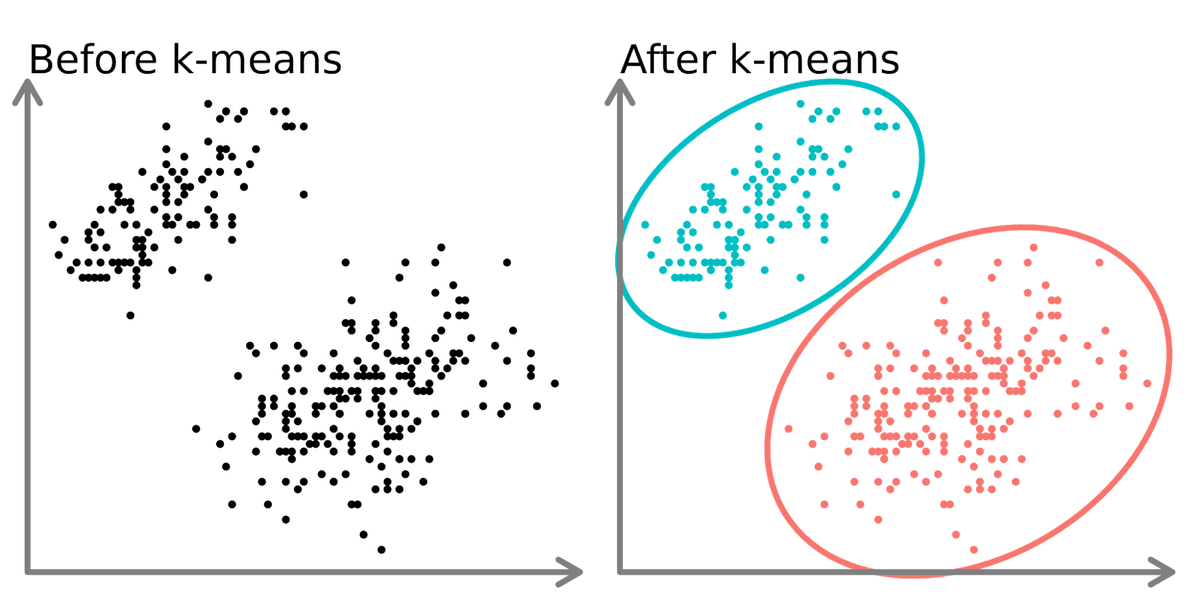
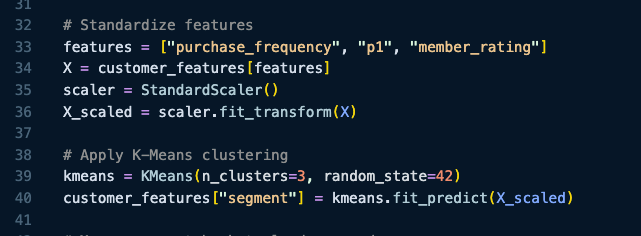
ML is great for 1 thing: finding clusters.
That's only 33% of the problem.
The other 66% is identifying what those clusters mean (and figuring out how to market to them).
That's only 33% of the problem.
The other 66% is identifying what those clusters mean (and figuring out how to market to them).
That's where AI comes in handy:
1. AI is great at summarizing large quantities of data
2. AI is excellent at making decisions from the summary
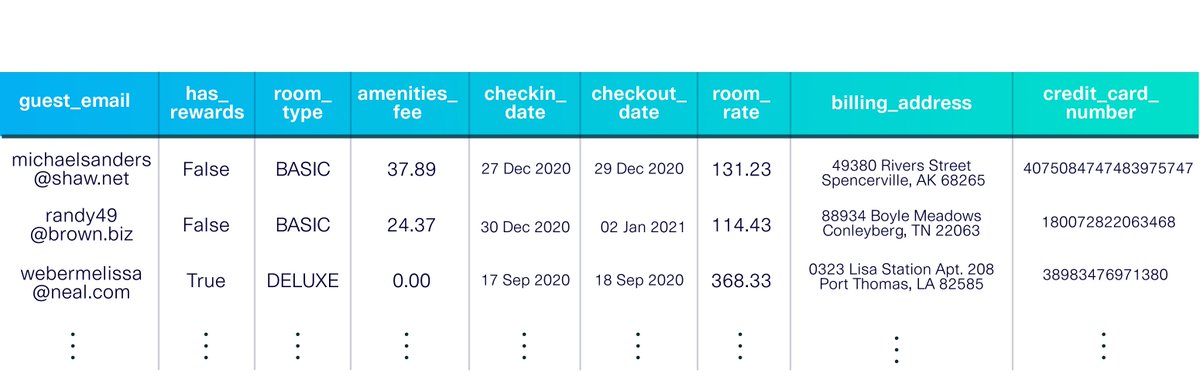
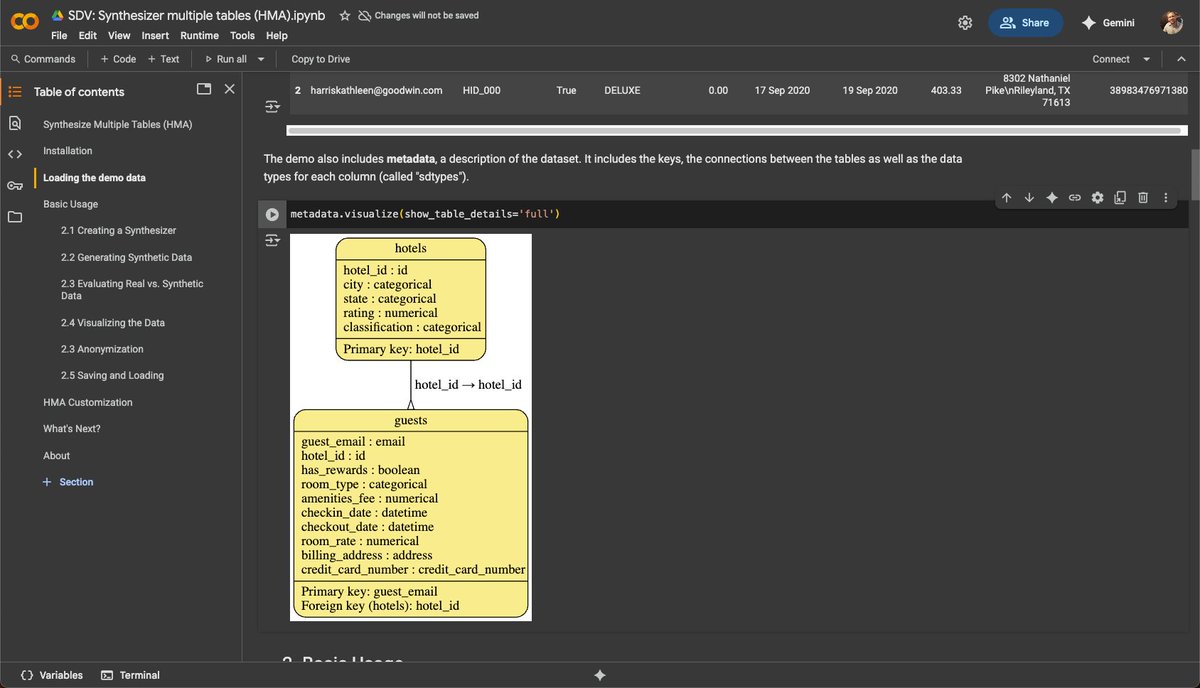
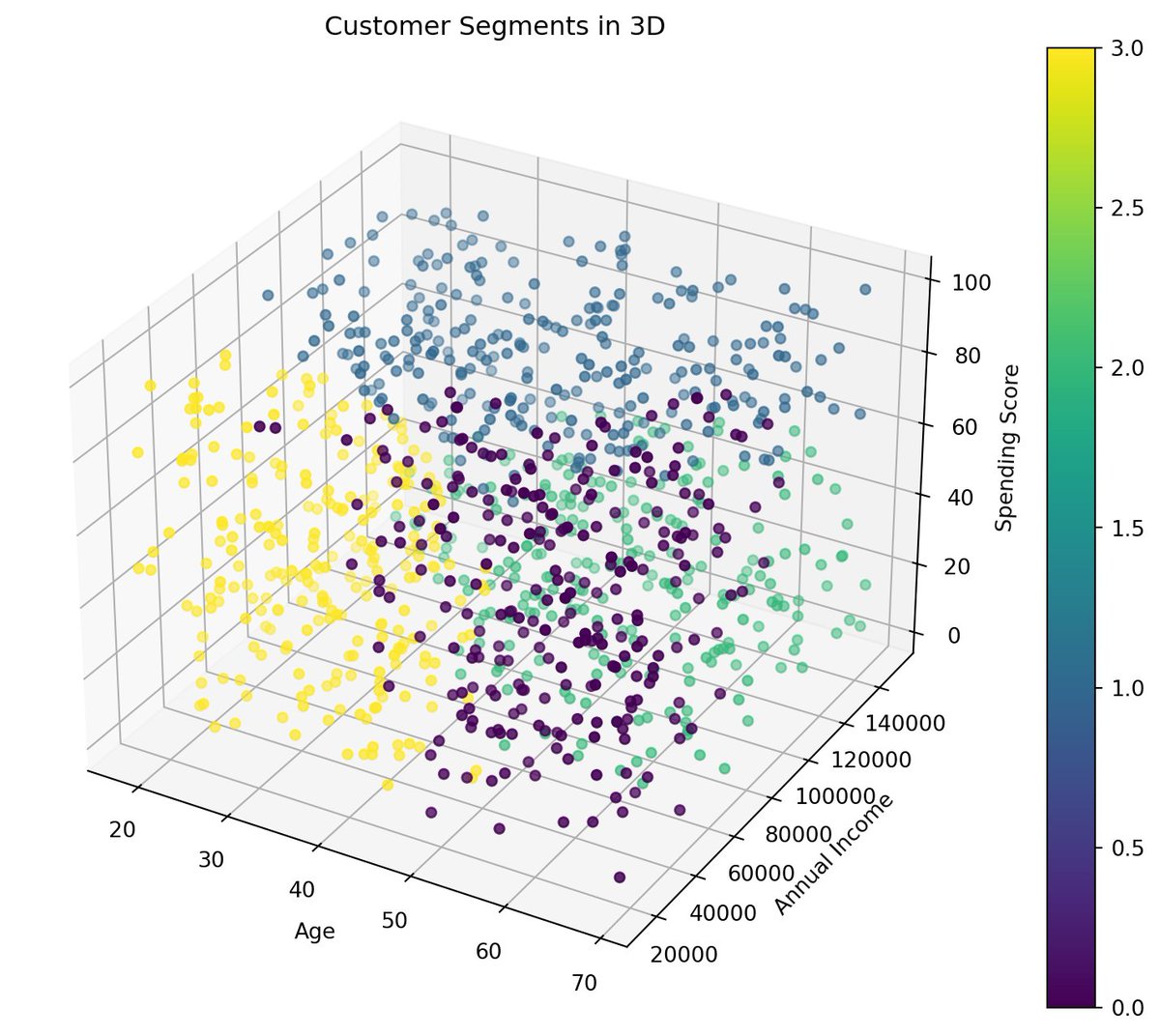
Problem: You need to make an AI Customer Segmentation Agent
1. AI is great at summarizing large quantities of data
2. AI is excellent at making decisions from the summary
Problem: You need to make an AI Customer Segmentation Agent
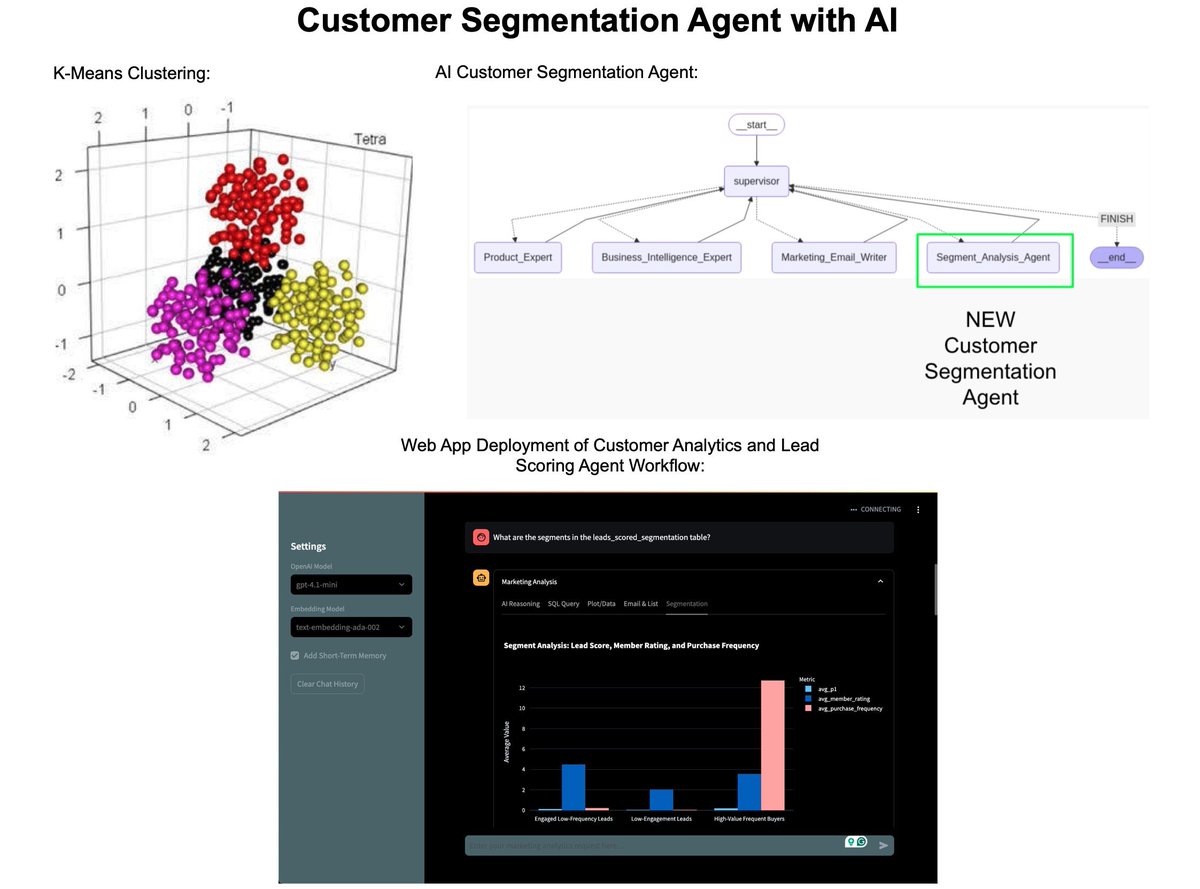
SOLUTION: AI for Customer Segmentation Analysis Agents
On Wednesday, August 20th, I'm sharing one of my best AI Projects: Customer Segmentation Agent with AI
Register here to learn how to build AI customer segmentation agents (500 seats): learn.business-science.io/registration-a…
On Wednesday, August 20th, I'm sharing one of my best AI Projects: Customer Segmentation Agent with AI
Register here to learn how to build AI customer segmentation agents (500 seats): learn.business-science.io/registration-a…
That's a wrap! Over the next 24 days, I'm sharing the 24 concepts that helped me become an AI data scientist.
If you enjoyed this thread:
1. Follow me @mdancho84 for more of these
2. RT the tweet below to share this thread with your audience
If you enjoyed this thread:
1. Follow me @mdancho84 for more of these
2. RT the tweet below to share this thread with your audience
https://twitter.com/815555071517872128/status/1957769108868542746
• • •
Missing some Tweet in this thread? You can try to
force a refresh