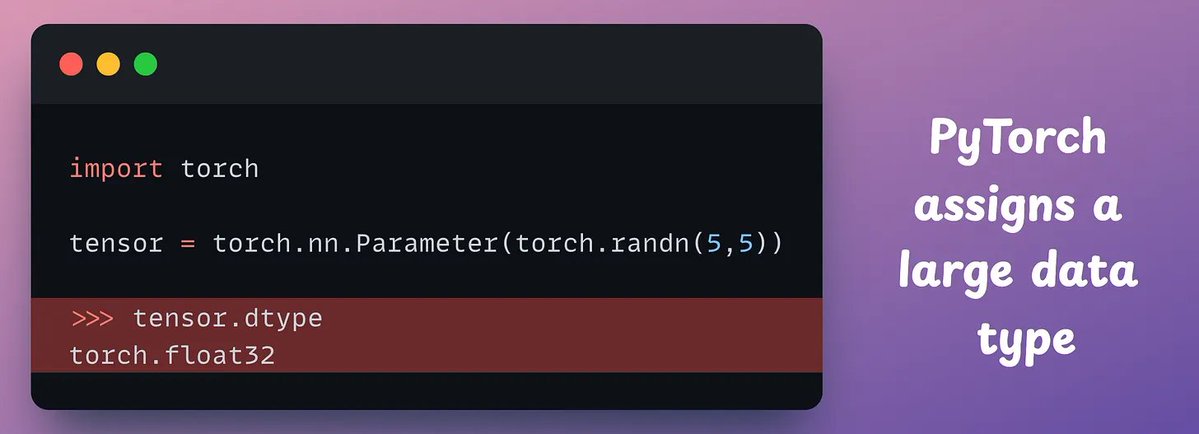
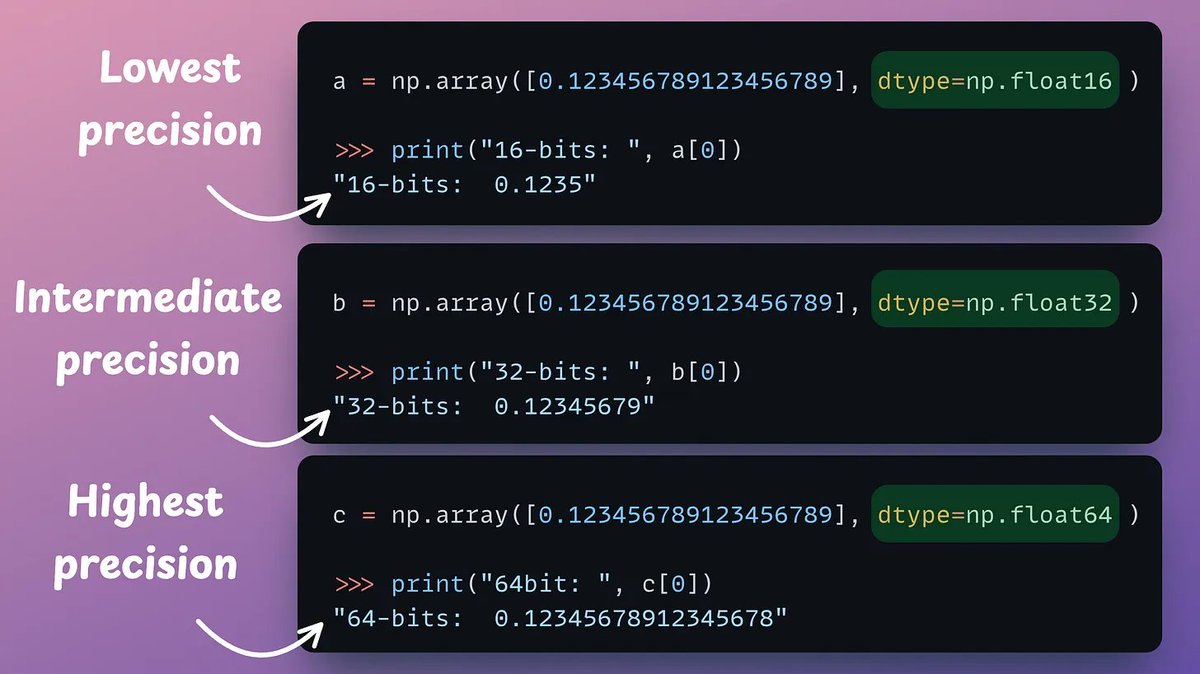
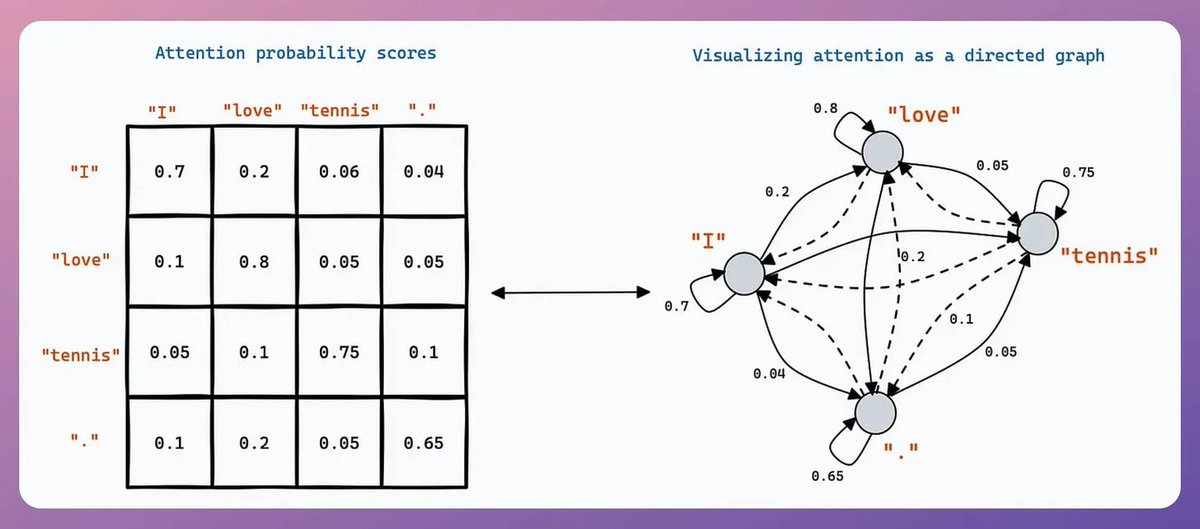
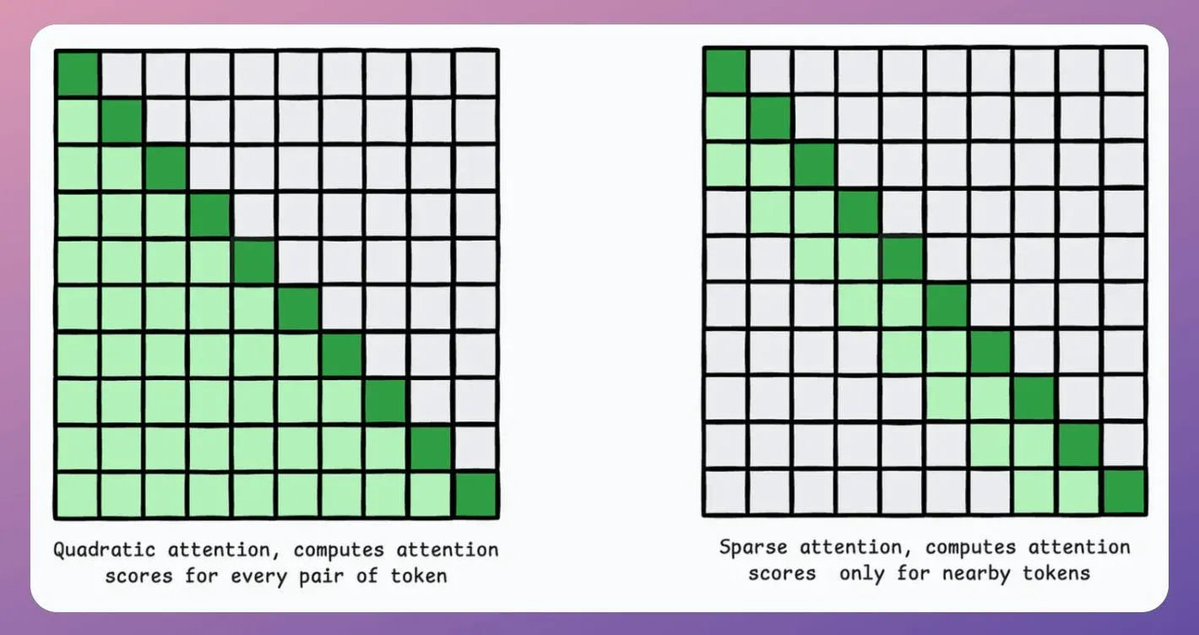
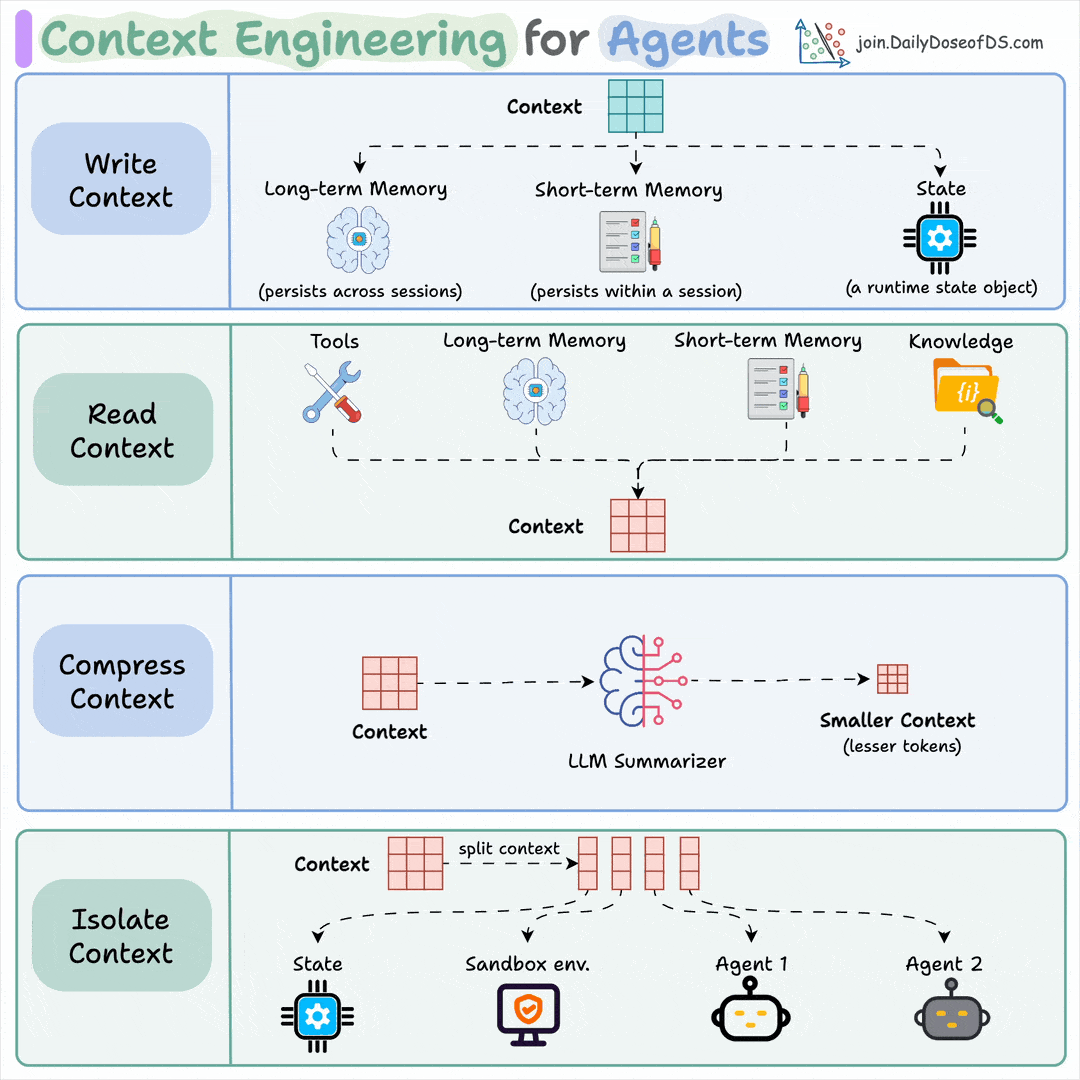
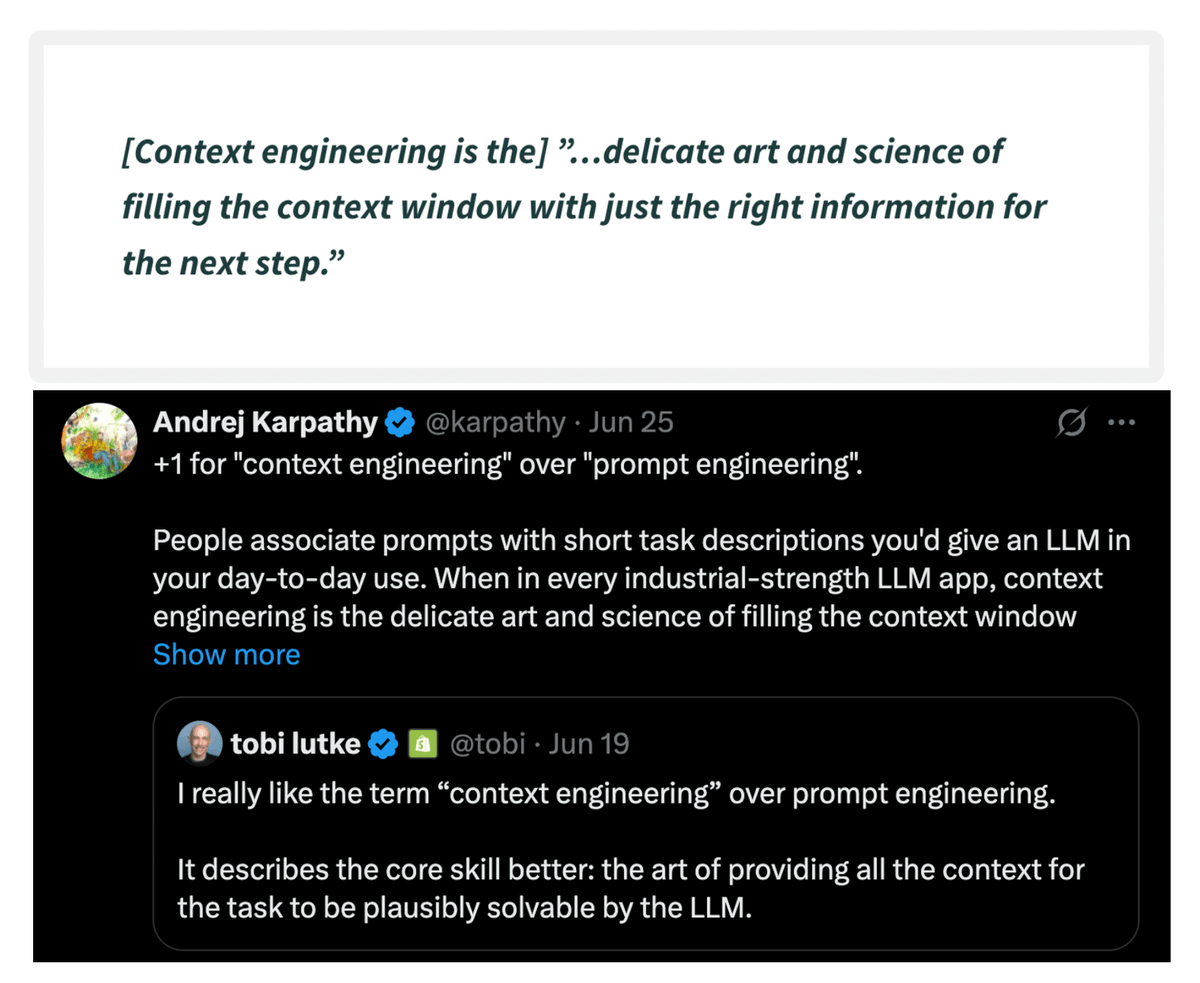
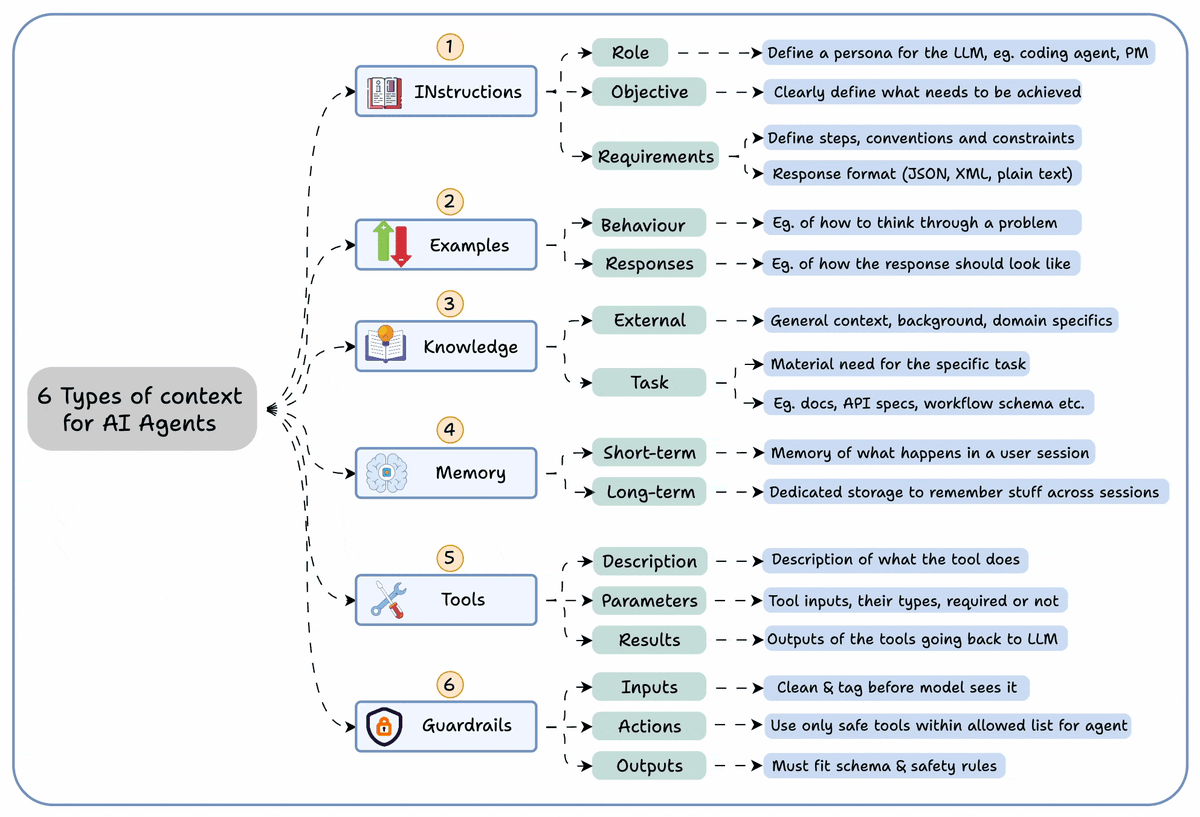
DeepMind built a simple RAG technique that:
- reduces hallucinations by 40%
- improves answer relevancy by 50%
Let's understand how to use it in RAG systems (with code):
- reduces hallucinations by 40%
- improves answer relevancy by 50%
Let's understand how to use it in RAG systems (with code):
Most RAG apps fail due to retrieval. Today, we'll build a RAG system that self-corrects inaccurate retrievals using:
- @firecrawl_dev for scraping
- @milvusio as vectorDB
- @beam_cloud for deployment
- @Cometml Opik for observability
- @Llama_Index for orchestration
Let's go!
- @firecrawl_dev for scraping
- @milvusio as vectorDB
- @beam_cloud for deployment
- @Cometml Opik for observability
- @Llama_Index for orchestration
Let's go!
Here's an overview of what the app does:
- First search the docs with user query
- Evaluate if the retrieved context is relevant using LLM
- Only keep the relevant context
- Do a web search if needed
- Aggregate the context & generate response
Now let's jump into code!
- First search the docs with user query
- Evaluate if the retrieved context is relevant using LLM
- Only keep the relevant context
- Do a web search if needed
- Aggregate the context & generate response
Now let's jump into code!
1️⃣ Setup LLM
We will use gpt-oss as the LLM, locally served using Ollama.
Check this out👇
We will use gpt-oss as the LLM, locally served using Ollama.
Check this out👇

2️⃣ Setup vector DB
Our primary source of knowledge is the user documents that we index and store in a Milvus vectorDB collection.
This will be the first source that will be invoked to fetch context when the user inputs a query.
Check this👇
Our primary source of knowledge is the user documents that we index and store in a Milvus vectorDB collection.
This will be the first source that will be invoked to fetch context when the user inputs a query.
Check this👇

3️⃣ Setup search tool
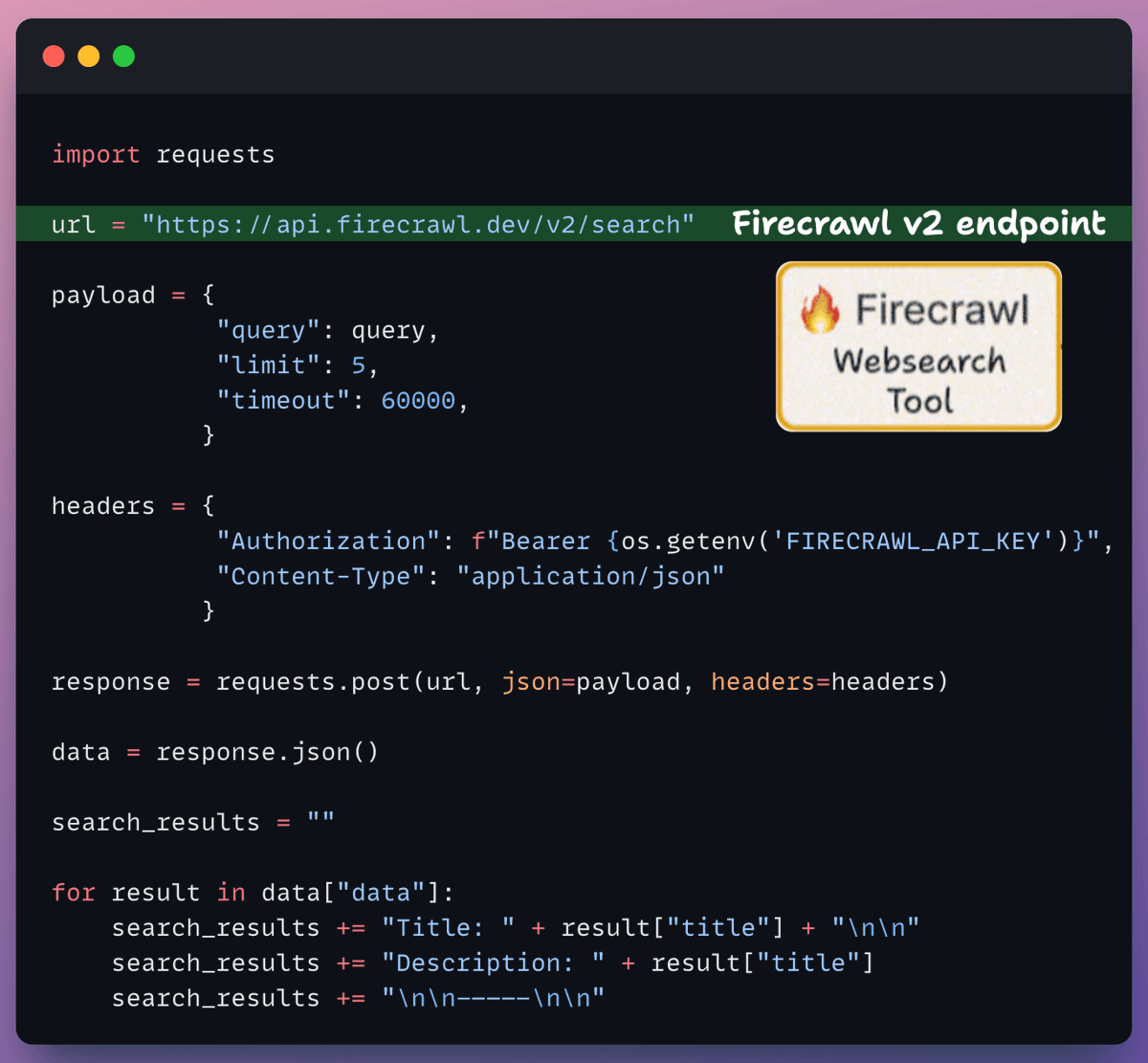
If the context obtained from the vector DB isn't relevant, we resort to web search using Firecrawl.
More specifically, we use the latest v2 endpoint that provides 10x faster scraping, semantic crawling, News & image search, and more.
Check this👇
If the context obtained from the vector DB isn't relevant, we resort to web search using Firecrawl.
More specifically, we use the latest v2 endpoint that provides 10x faster scraping, semantic crawling, News & image search, and more.
Check this👇
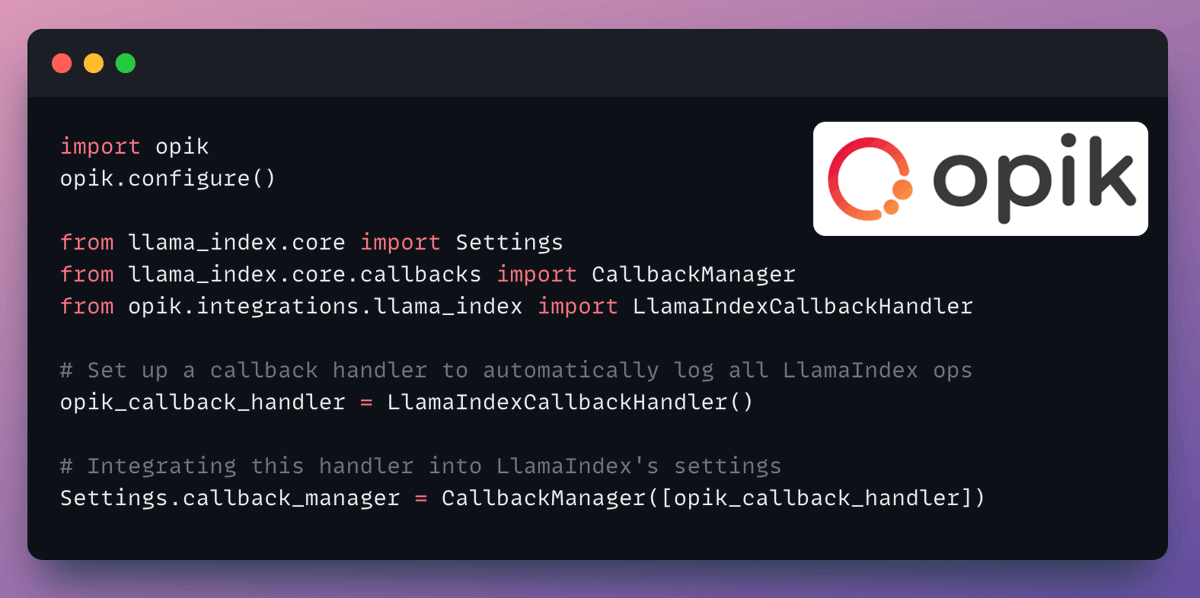
4️⃣ Observability
LlamaIndex offers a seamless integration with CometML's Opik.
We use this to trace every LLM call, monitor, and evaluate our Corrective RAG application.
Check this 👇
LlamaIndex offers a seamless integration with CometML's Opik.
We use this to trace every LLM call, monitor, and evaluate our Corrective RAG application.
Check this 👇
5️⃣ Create the workflow
Now that we have everything set up, it's time to create the event-driven agentic workflow that orchestrates our application.
We pass in the LLM, vector index, and web search tool to initialize the workflow.
Check this 👇
Now that we have everything set up, it's time to create the event-driven agentic workflow that orchestrates our application.
We pass in the LLM, vector index, and web search tool to initialize the workflow.
Check this 👇

7️⃣ Kick off the workflow
Finally, when we have everything ready, we kick off our workflow.
Check this👇
Finally, when we have everything ready, we kick off our workflow.
Check this👇

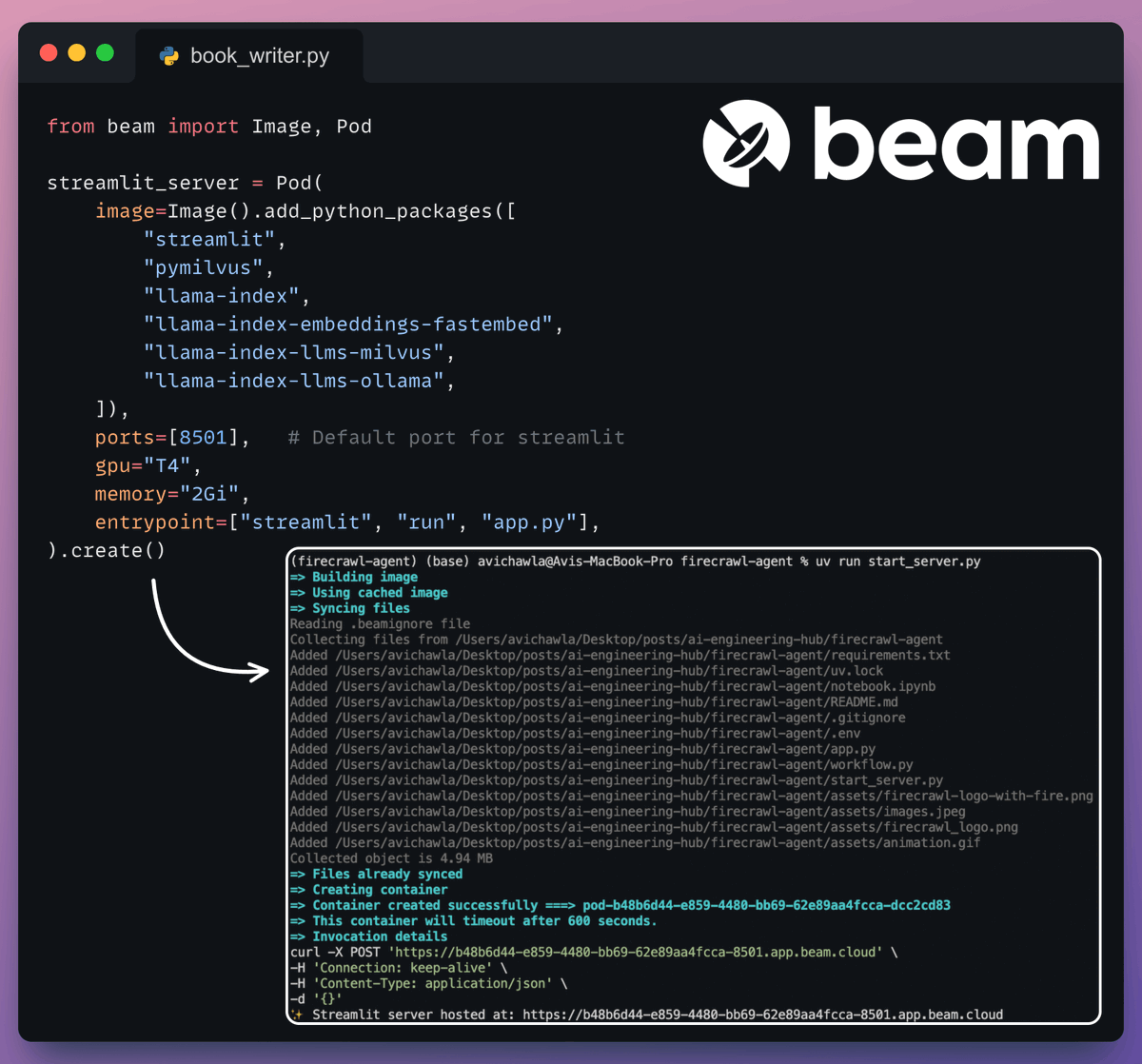
8️⃣ Deployment with Beam
Beam enables ultra-fast serverless deployment of any AI workflow.
Thus, we wrap our app in a Streamlit interface, specify the Python libraries, and the compute specifications for the container.
Finally, we deploy it in a few lines of code👇
Beam enables ultra-fast serverless deployment of any AI workflow.
Thus, we wrap our app in a Streamlit interface, specify the Python libraries, and the compute specifications for the container.
Finally, we deploy it in a few lines of code👇
Run the app
Beam launches the container and deploys our streamlit app as an HTTPS server that can be accessed from a web browser.
In the video, our workflow is able to answer a query that's unrelated to the document. The evaluation step makes this possible.
Check this 👇
Beam launches the container and deploys our streamlit app as an HTTPS server that can be accessed from a web browser.
In the video, our workflow is able to answer a query that's unrelated to the document. The evaluation step makes this possible.
Check this 👇
That's a wrap!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
https://twitter.com/1175166450832687104/status/1958053890831872065
• • •
Missing some Tweet in this thread? You can try to
force a refresh