This is amazing. But I'm a bit more extreme than Maxime.
I hate to maintain any more code than necessary. To me, code is debt.
So I'd replace the raw 60-liner here with just a 2-liner.
I hate to maintain any more code than necessary. To me, code is debt.
So I'd replace the raw 60-liner here with just a 2-liner.
https://twitter.com/MaximeRivest/status/1959713203291607281
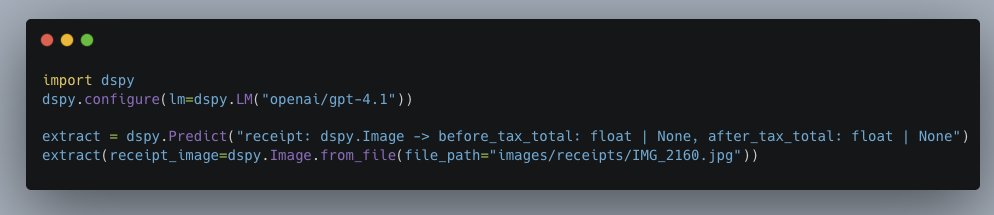
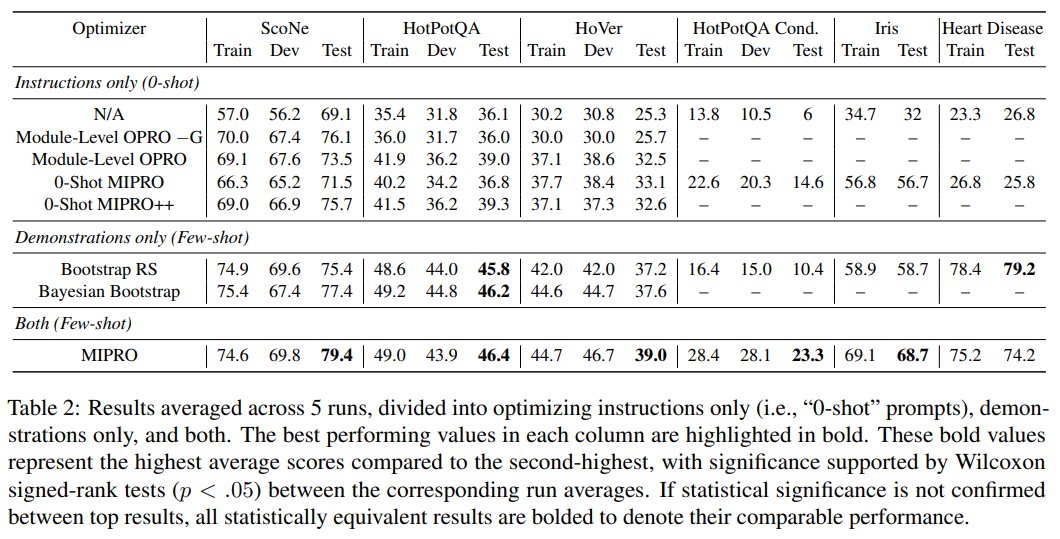
If not obvious, these 2 lines are doing the work of 60 lines, but better. They come with lots of implicit functionality for reliability, portability, and readiness for optimization.
I don't think the 2-liner is special. I think the 60-liners are dumb:
I don't think the 2-liner is special. I think the 60-liners are dumb:
https://x.com/lateinteraction/status/1959710213780443528
This is perhaps an important point.
So much of the argument for DSPy isn't something like "the paradigm is amazing and super powerful".
Way too much of it for my taste is just that "the BS things you have to do otherwise are unbearably stupid". Wish we could focus on strengths.
So much of the argument for DSPy isn't something like "the paradigm is amazing and super powerful".
Way too much of it for my taste is just that "the BS things you have to do otherwise are unbearably stupid". Wish we could focus on strengths.
• • •
Missing some Tweet in this thread? You can try to
force a refresh