
Asst professor @MIT EECS & CSAIL (@nlp_mit).
Author of https://t.co/VgyLxl0oa1 and https://t.co/ZZaSzaRaZ7 (@DSPyOSS).
Prev: CS PhD @StanfordNLP. Research @Databricks.

 Roadmap:
Roadmap:  📰:
📰: 
 The DSPy vision is to push for a sane **stack** of lower- to higher-level LM frameworks, learning from the DNN abstraction space.
The DSPy vision is to push for a sane **stack** of lower- to higher-level LM frameworks, learning from the DNN abstraction space.
 This is thread #2 (out of three) on late interaction.
This is thread #2 (out of three) on late interaction. Say you have 1M documents. With infinite GPUs, what would your retriever look like?
Say you have 1M documents. With infinite GPUs, what would your retriever look like?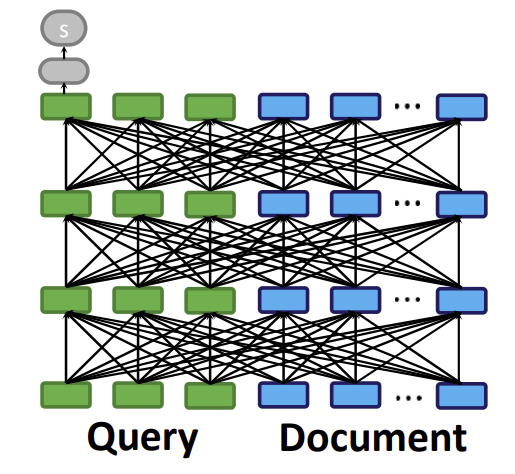
 If you want to do this in a notebook with step-by-step code:
If you want to do this in a notebook with step-by-step code:
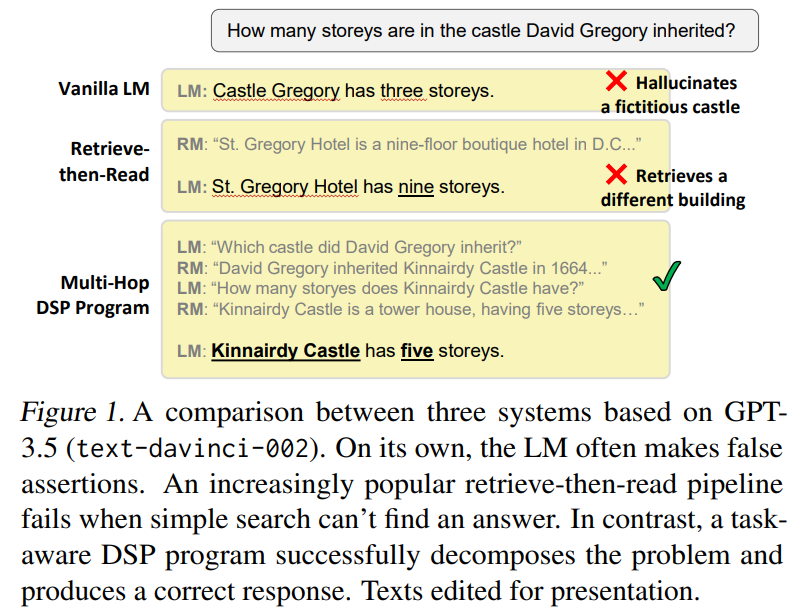 Instead of crafting a prompt for the LM, you write a short 𝗗𝗦𝗣 program that assigns small tasks to the LM and a retrieval model (RM) in deliberate powerful pipelines.
Instead of crafting a prompt for the LM, you write a short 𝗗𝗦𝗣 program that assigns small tasks to the LM and a retrieval model (RM) in deliberate powerful pipelines.