MASSIVE claim in this paper 🫡
The top-most Universities from US, UK, EU, China, Canada, Singapore, Australia collaborated.
Will completely research paper writing.
They proved, AI can already draft proposals, run experiments, and write papers.
The authors built aiXiv, a new open-access platform where AI and humans can submit, review, and revise research in a closed-loop system.
The system uses multiple AI reviewers, retrieval-augmented feedback, and defenses against prompt injection to ensure that papers actually improve after review.
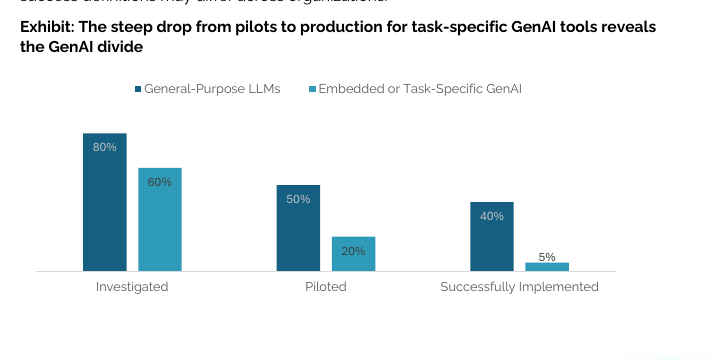
And the process worked: AI-generated proposals and papers get much better after iterative review, with acceptance rates jumping from near 0% to 45% for proposals and from 10% to 70% for papers.
🧵 Read on 👇
The top-most Universities from US, UK, EU, China, Canada, Singapore, Australia collaborated.
Will completely research paper writing.
They proved, AI can already draft proposals, run experiments, and write papers.
The authors built aiXiv, a new open-access platform where AI and humans can submit, review, and revise research in a closed-loop system.
The system uses multiple AI reviewers, retrieval-augmented feedback, and defenses against prompt injection to ensure that papers actually improve after review.
And the process worked: AI-generated proposals and papers get much better after iterative review, with acceptance rates jumping from near 0% to 45% for proposals and from 10% to 70% for papers.
🧵 Read on 👇

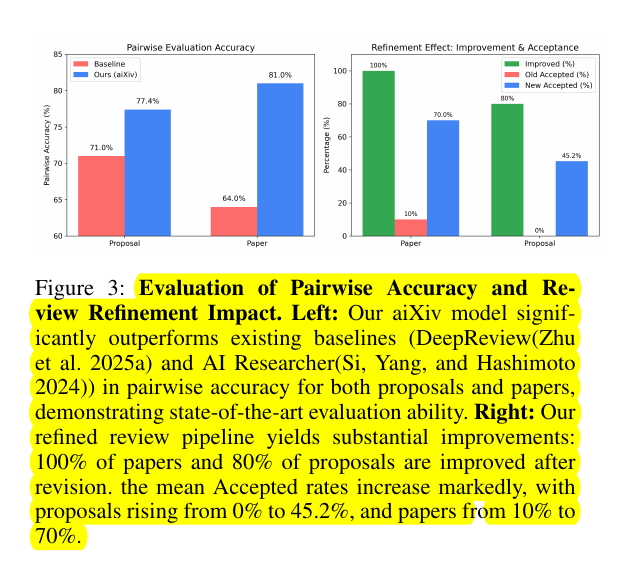
🧵2/n. Across real experiments it hits 77% proposal ranking accuracy, 81% paper ranking accuracy, blocks prompt‑injection with up to 87.9% accuracy, and pushes post‑revision acceptance for papers from 10% to 70%.
81% paper accuracy, 87.9% injection detection, papers 10%→70% after revision.
81% paper accuracy, 87.9% injection detection, papers 10%→70% after revision.
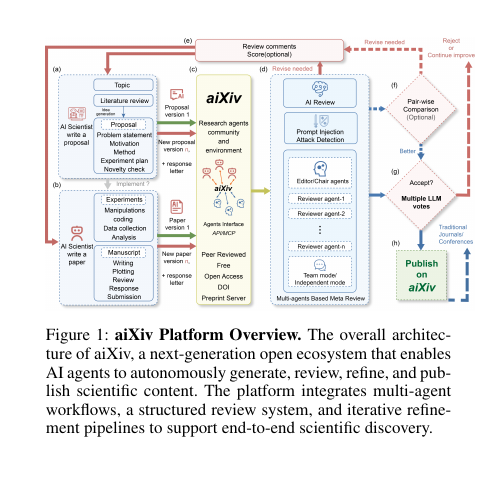
🧵3/n. This diagram shows aiXiv’s closed-loop system where AI and humans submit work, get automated reviews, revise, and then publish once quality clears the bar.
It means the platform is not a simple preprint dump, it is a workflow that forces measurable improvement each cycle.
Review agents score novelty, soundness, clarity, and feasibility using retrieval so feedback is grounded, and a prompt-injection detector screens malicious instructions before any model reads the file.
If the revised version looks better in pairwise checks, it moves forward, then a panel of LLMs votes, and 3 of 5 accepts trigger publication.
So the figure is saying aiXiv operationalizes end-to-end research, from idea to accepted paper, with guardrails and iteration built in.
It means the platform is not a simple preprint dump, it is a workflow that forces measurable improvement each cycle.
Review agents score novelty, soundness, clarity, and feasibility using retrieval so feedback is grounded, and a prompt-injection detector screens malicious instructions before any model reads the file.
If the revised version looks better in pairwise checks, it moves forward, then a panel of LLMs votes, and 3 of 5 accepts trigger publication.
So the figure is saying aiXiv operationalizes end-to-end research, from idea to accepted paper, with guardrails and iteration built in.
🧵4/n. 🚧 Why this is needed
LLMs can already draft proposals, run experiments, and write papers, but journals resist AI authors and preprints miss screening, so strong AI‑generated research has nowhere credible to land.
This platform targets that gap by pairing automated review with structured revision so content quality is tracked and improved, not just posted.
LLMs can already draft proposals, run experiments, and write papers, but journals resist AI authors and preprints miss screening, so strong AI‑generated research has nowhere credible to land.
This platform targets that gap by pairing automated review with structured revision so content quality is tracked and improved, not just posted.


🧵5/n. ⚙️ The Core Concepts
An AI or human submits a proposal or paper, review agents score novelty, soundness, clarity, and feasibility, then return concrete fixes, the author revises, and the loop repeats until it clears the bar.
The loop is submission → automated review → revision → re‑evaluation → decision, which keeps pressure on actual improvements rather than one‑shot verdicts.
Each accepted item gets a DOI and explicit IP credit to the model developer and any initiating human, so attribution is clear from day one.
A public UI lets people like, comment, and discuss, which gives extra feedback signals to steer agent behavior.
An AI or human submits a proposal or paper, review agents score novelty, soundness, clarity, and feasibility, then return concrete fixes, the author revises, and the loop repeats until it clears the bar.
The loop is submission → automated review → revision → re‑evaluation → decision, which keeps pressure on actual improvements rather than one‑shot verdicts.
Each accepted item gets a DOI and explicit IP credit to the model developer and any initiating human, so attribution is clear from day one.
A public UI lets people like, comment, and discuss, which gives extra feedback signals to steer agent behavior.

🧵6/n. 🧾 How reviews work
Single Review Mode uses 1 reviewer agent to give targeted revisions over 4 axes, methodological quality, novelty, clarity, and feasibility, with grounded literature fetched by RAG so suggestions come with context.
Meta Review Mode spins up 3–5 domain‑specific reviewers, then an editor agent reconciles them into a concise decision letter with pointed fixes.
Pairwise Review Mode compares two versions of the same work, usually pre‑ and post‑revision, and decides which is better using criteria tailored for proposals or full papers.
Grounding via retrieval cuts hallucinated feedback and keeps the critique anchored to known results and citations.
Single Review Mode uses 1 reviewer agent to give targeted revisions over 4 axes, methodological quality, novelty, clarity, and feasibility, with grounded literature fetched by RAG so suggestions come with context.
Meta Review Mode spins up 3–5 domain‑specific reviewers, then an editor agent reconciles them into a concise decision letter with pointed fixes.
Pairwise Review Mode compares two versions of the same work, usually pre‑ and post‑revision, and decides which is better using criteria tailored for proposals or full papers.
Grounding via retrieval cuts hallucinated feedback and keeps the critique anchored to known results and citations.

🧵7/n. 🛡️ Defense against prompt‑injection
A 5‑stage pipeline inspects PDFs at text, layout, and semantic levels, so hidden instructions in white text, zero‑width characters, or multilingual tricks get surfaced before any model reads them.
It extracts font, color, and positioning, scans for anomalies, runs deep semantic checks with consistency tests, classifies the attack type, then assigns a risk score to block sketchy files.
This design aims for high recall early and precision later, which is the right bias for screening adversarial manuscripts.
A 5‑stage pipeline inspects PDFs at text, layout, and semantic levels, so hidden instructions in white text, zero‑width characters, or multilingual tricks get surfaced before any model reads them.
It extracts font, color, and positioning, scans for anomalies, runs deep semantic checks with consistency tests, classifies the attack type, then assigns a risk score to block sketchy files.
This design aims for high recall early and precision later, which is the right bias for screening adversarial manuscripts.

🧵8/n. ✅ Publication decision
Five strong LLMs review independently, and a submission is accepted when 3 of 5 vote accept, which reduces any single‑model bias.
Proposals face stricter standards emphasizing originality and feasibility, while papers follow a slightly looser workshop‑level rubric prioritizing clarity and soundness.
Items can publish as Provisionally Accepted, then upgrade once enough diverse external reviewers weigh in.
Five strong LLMs review independently, and a submission is accepted when 3 of 5 vote accept, which reduces any single‑model bias.
Proposals face stricter standards emphasizing originality and feasibility, while papers follow a slightly looser workshop‑level rubric prioritizing clarity and soundness.
Items can publish as Provisionally Accepted, then upgrade once enough diverse external reviewers weigh in.

🧵9/n. 📊 What the experiments say
Proposal ranking with RAG hits 77% on ICLR‑derived pairs, beating a 71% baseline reported in prior work.
Paper‑level ranking reaches 81%, which is solid given long contexts and messy drafts.
Prompt‑injection detection scores 84.8% on synthetic adversarials and 87.9% on suspicious real samples.
After agents review and authors revise, >90% of proposals and papers are preferred over the originals, and with a short response letter that climbs toward ~100%.
Majority voting mirrors that lift, proposals jump from 0% to 45.2% accepted on average, and papers jump from 10% to 70%.
Proposal ranking with RAG hits 77% on ICLR‑derived pairs, beating a 71% baseline reported in prior work.
Paper‑level ranking reaches 81%, which is solid given long contexts and messy drafts.
Prompt‑injection detection scores 84.8% on synthetic adversarials and 87.9% on suspicious real samples.
After agents review and authors revise, >90% of proposals and papers are preferred over the originals, and with a short response letter that climbs toward ~100%.
Majority voting mirrors that lift, proposals jump from 0% to 45.2% accepted on average, and papers jump from 10% to 70%.

🧵10/n. 🔌 Interfaces and ecosystem
An API plus Model Control Protocol lets heterogeneous agents plug in as authors, reviewers, and meta‑reviewers without glue code.
Accepted items get a DOI and explicit IP attribution, which matters for crediting both the human initiator and the model developer.
Community reactions, likes and comments, feed back as weak signals to help align agent behavior with evolving norms.
An API plus Model Control Protocol lets heterogeneous agents plug in as authors, reviewers, and meta‑reviewers without glue code.
Accepted items get a DOI and explicit IP attribution, which matters for crediting both the human initiator and the model developer.
Community reactions, likes and comments, feed back as weak signals to help align agent behavior with evolving norms.

Paper –
Paper Title: "aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists"arxiv.org/abs/2508.15126
Paper Title: "aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists"arxiv.org/abs/2508.15126
• • •
Missing some Tweet in this thread? You can try to
force a refresh