just pushed my first multi-turn RL environment to @PrimeIntellect
the setup: the model gets the story title + question from QuALITY (long stories, multiple-choice questions).
tts only tool: agentic RAG search over the story.
the setup: the model gets the story title + question from QuALITY (long stories, multiple-choice questions).
tts only tool: agentic RAG search over the story.
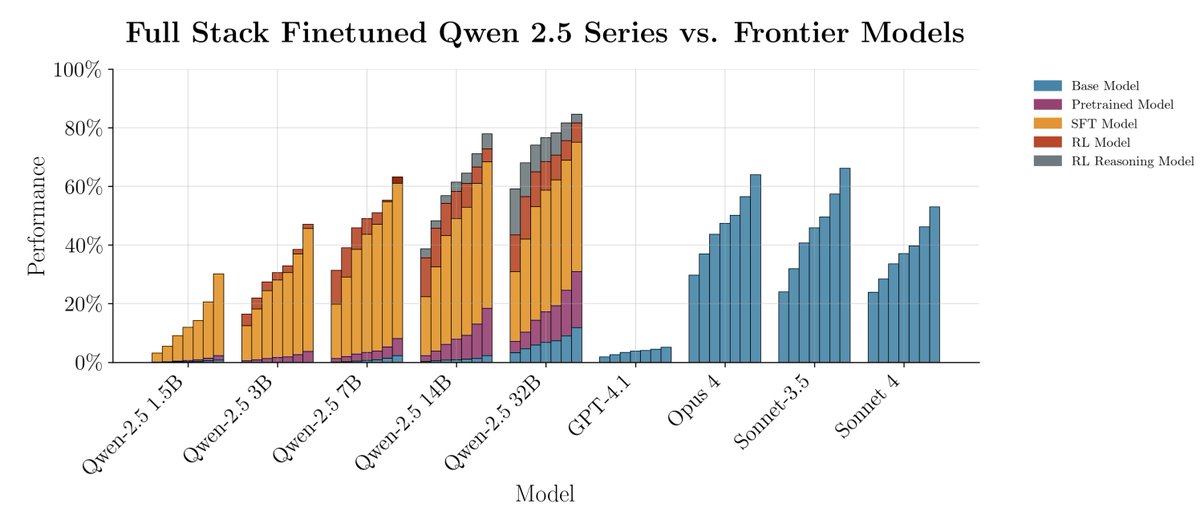
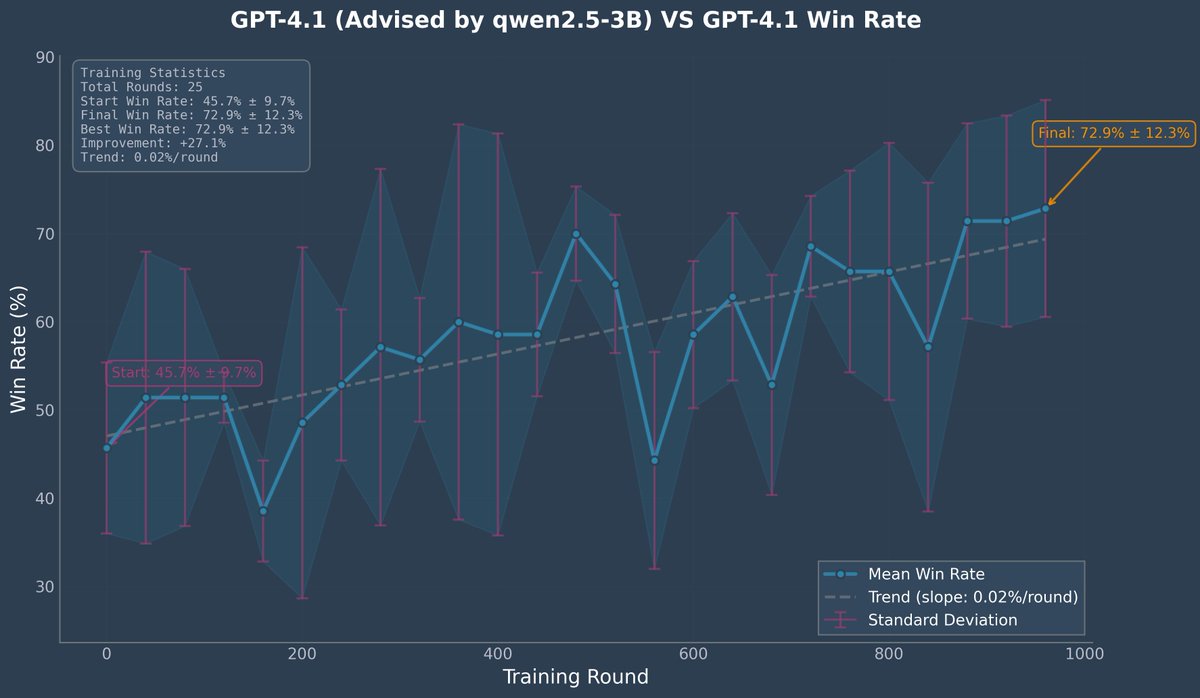
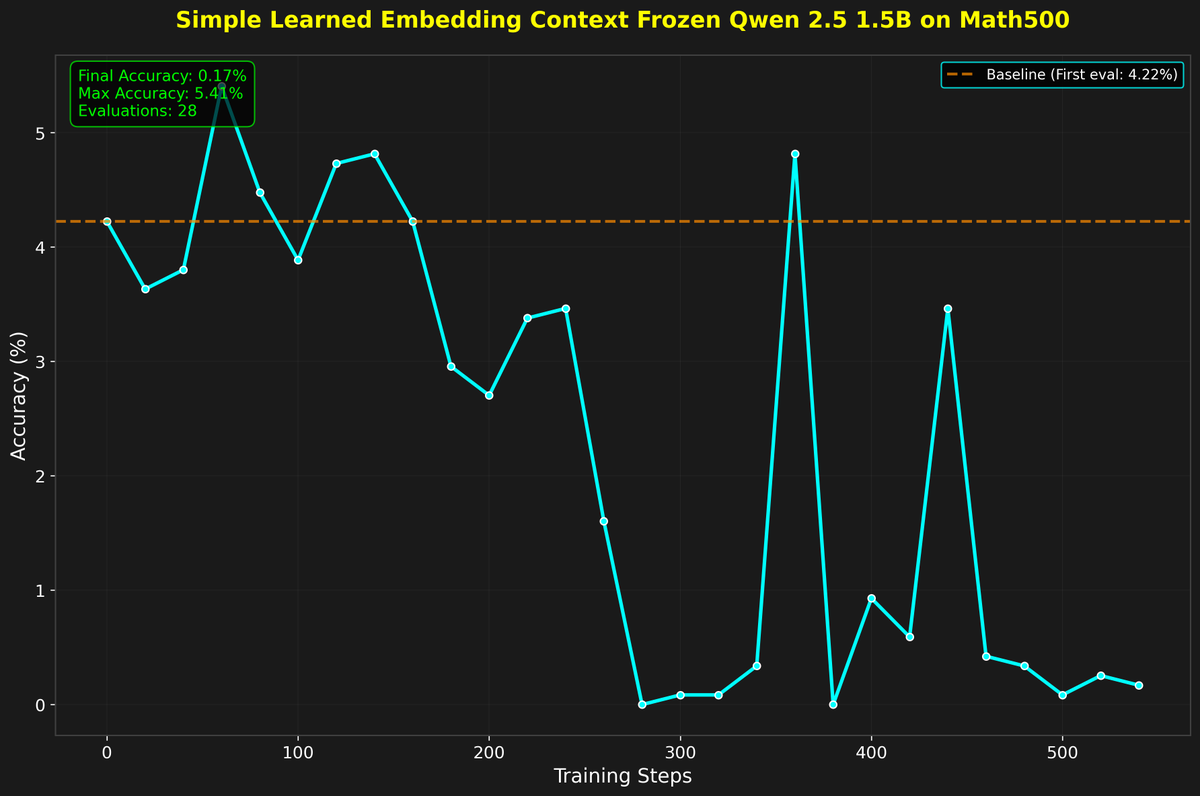
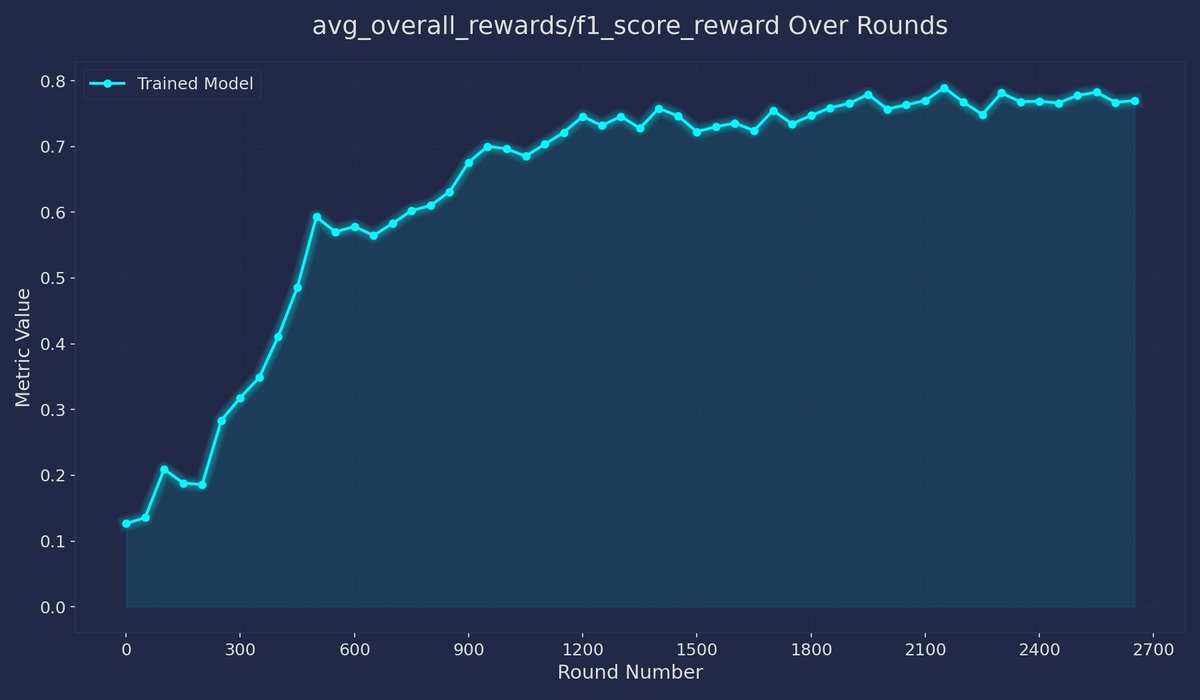
this is an idea I have been toying with for a while but didn’t get around to doing. I had a paper last year about a twist on a RAG method and primarily experimented on this dataset.
i really like this dataset; it’s sort of harder-to-read short stories, and the questions really require (imo) a good and subtle understanding of the paper.
so I liked the idea of building an agentic RAG system over this dataset - each story gets chunked up and embedded using OpenAI’s embeddings - then the agent gets to choose the query to embed and search.
the chunks are very small, so it’s a pretty difficult task. But I think learning here would require really reasoning about the question and the structure of this kind of writing.
thanks to @PrimeIntellect for building this and @willccbb for the invite! I think this is such an incredible initiative that can go in so many exciting directions. Looking forward to publishing a lot more RL environments and building agi together :) !
• • •
Missing some Tweet in this thread? You can try to
force a refresh