
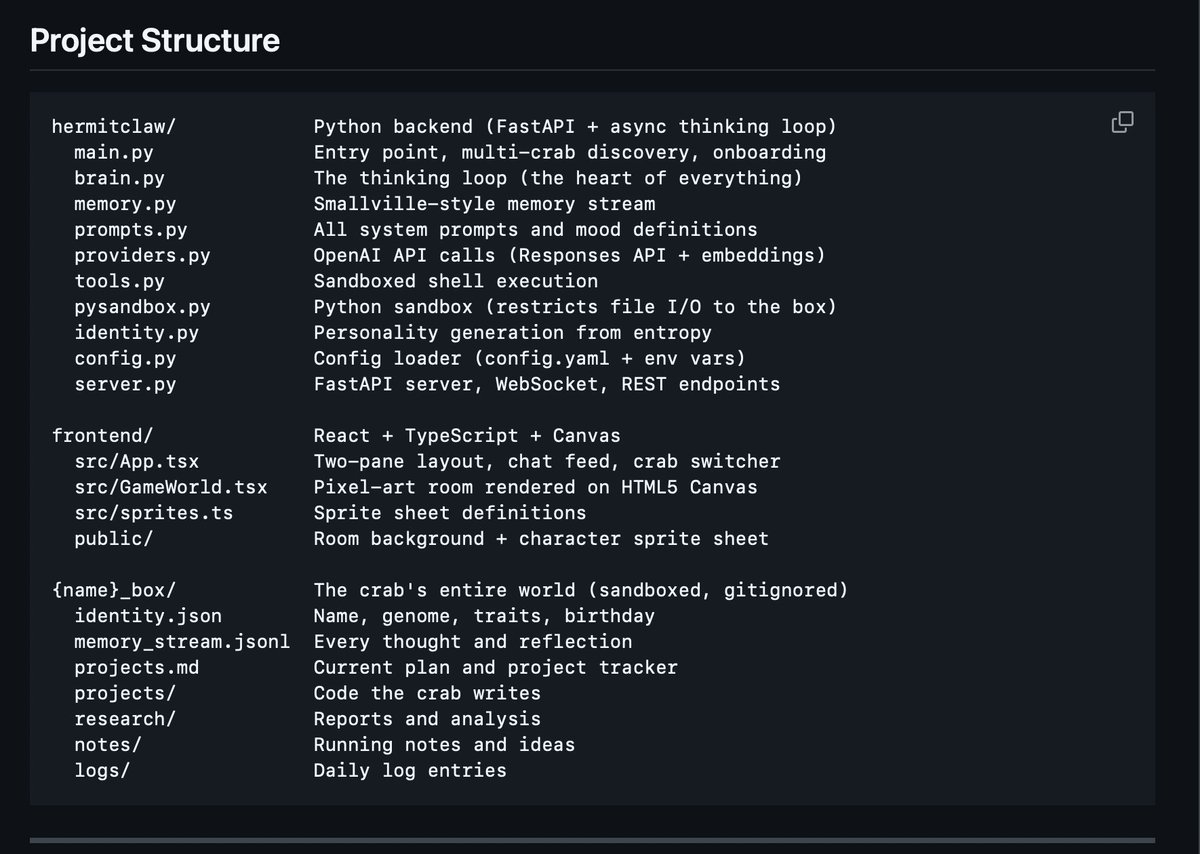
 code: github.com/brendanhogan/2…
code: github.com/brendanhogan/2…
 code: github.com/brendanhogan/2…
code: github.com/brendanhogan/2… Code: github.com/brendanhogan/2…
Code: github.com/brendanhogan/2…
 repo: github.com/brendanhogan/2…
repo: github.com/brendanhogan/2…
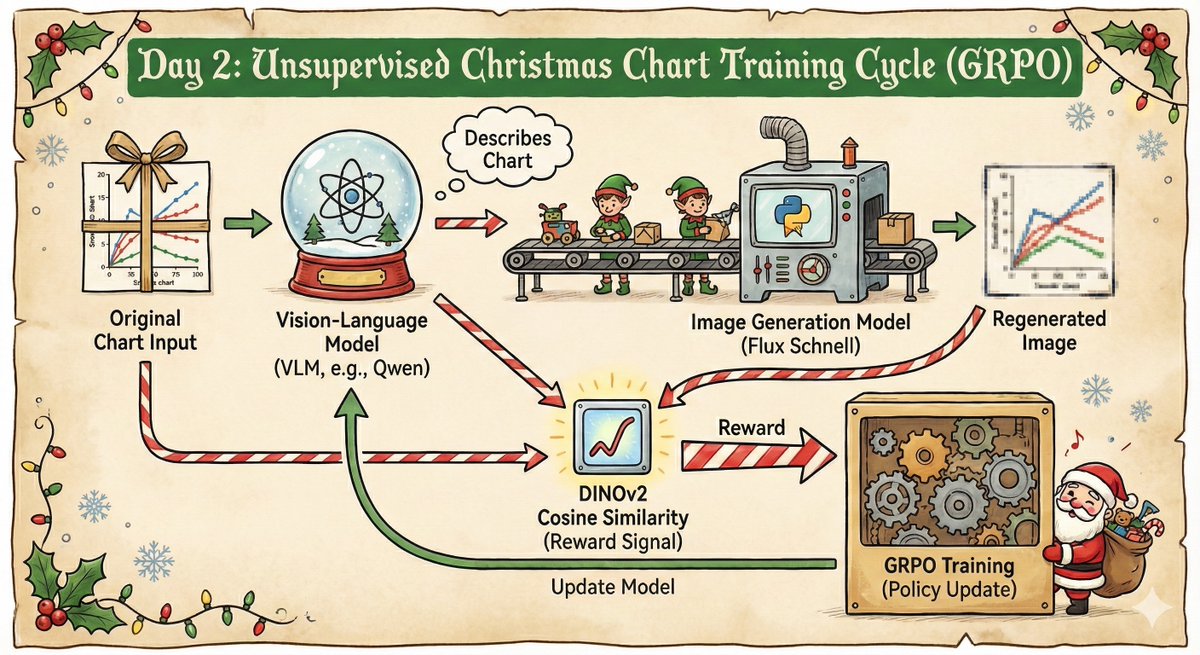 Github: github.com/brendanhogan/2…
Github: github.com/brendanhogan/2…
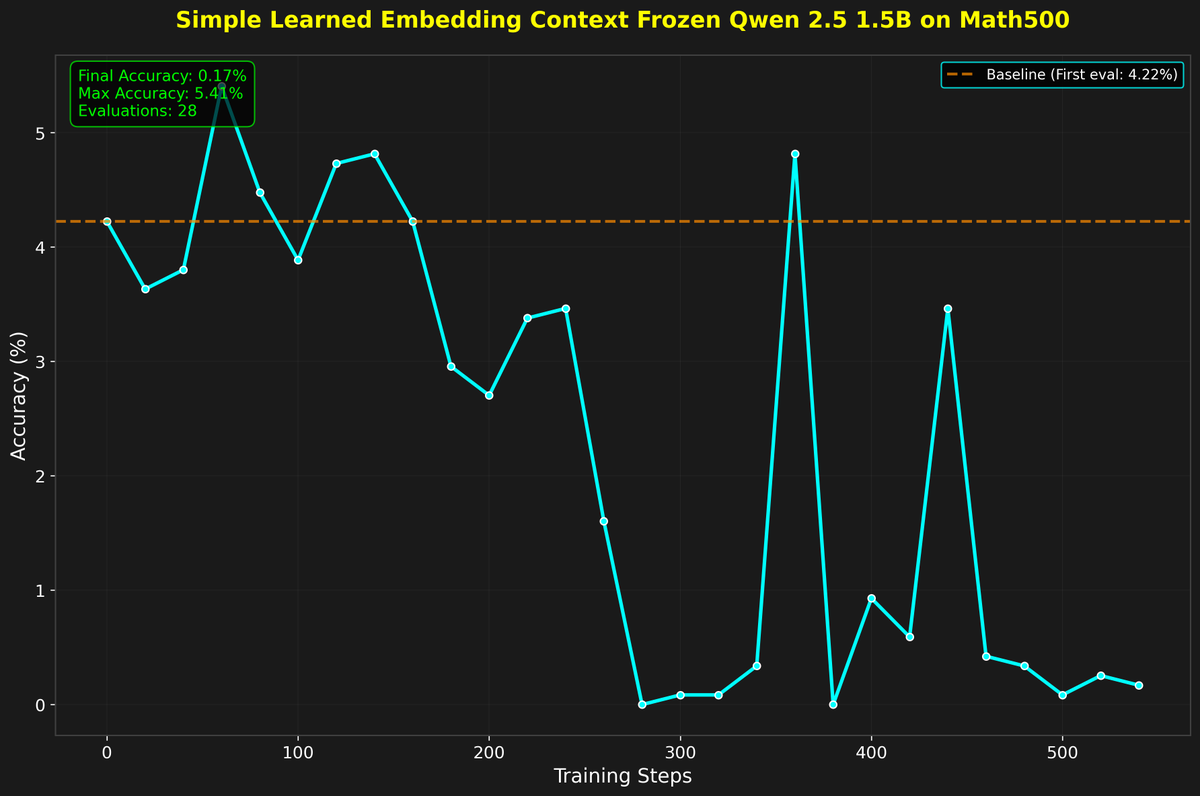
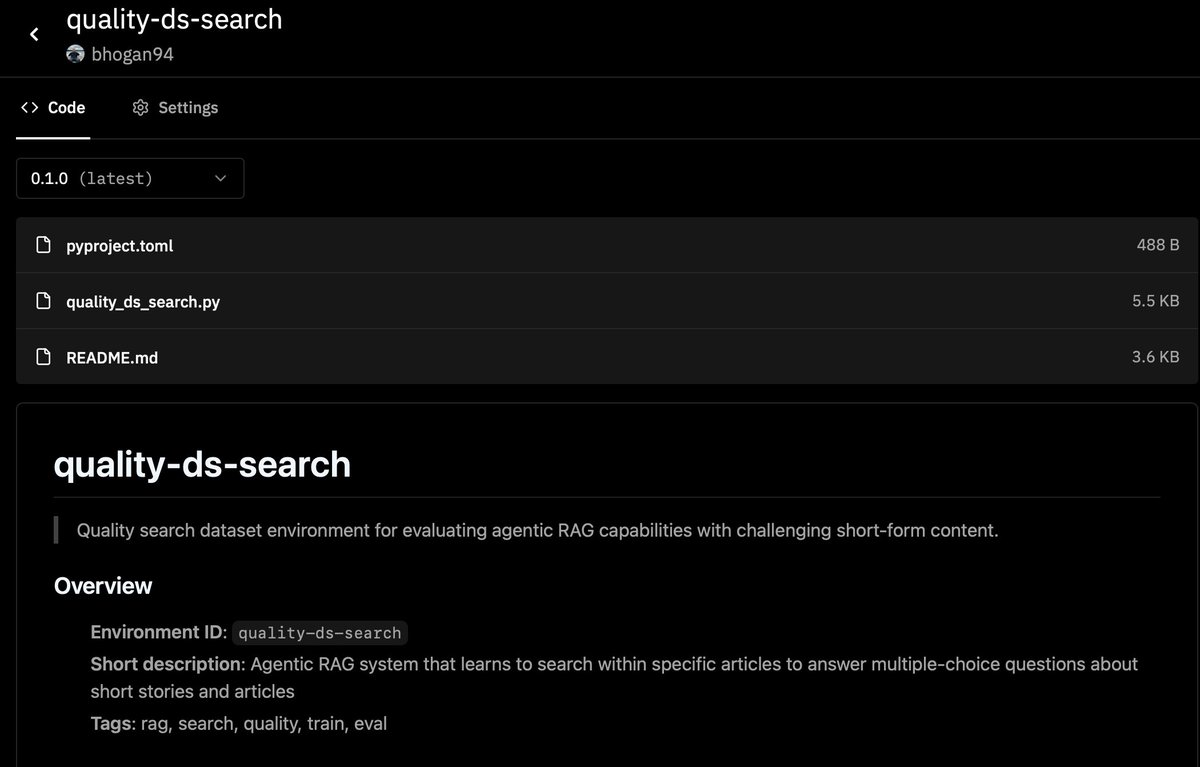 this is an idea I have been toying with for a while but didn’t get around to doing. I had a paper last year about a twist on a RAG method and primarily experimented on this dataset.
this is an idea I have been toying with for a while but didn’t get around to doing. I had a paper last year about a twist on a RAG method and primarily experimented on this dataset.
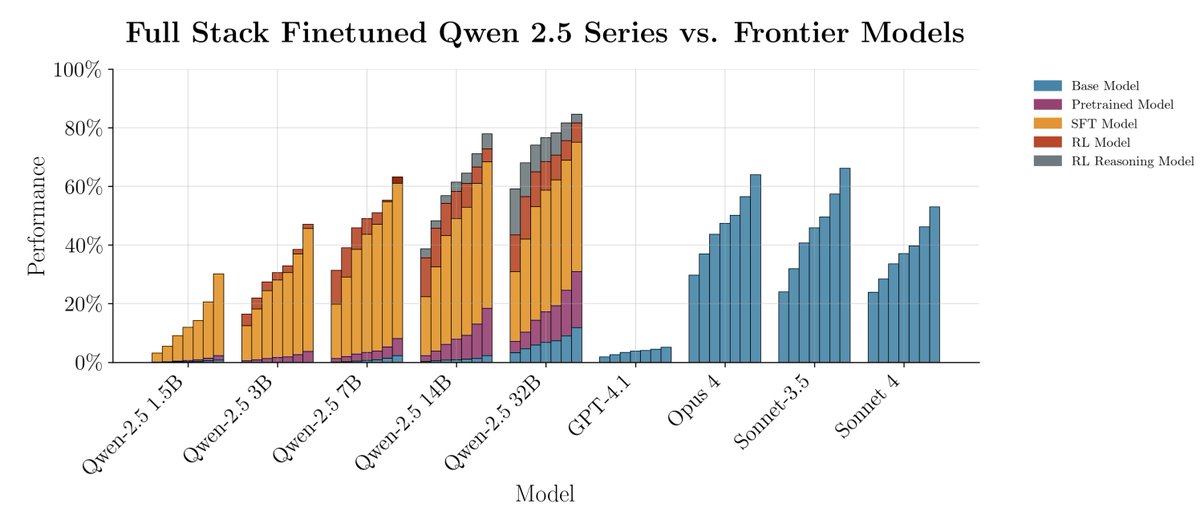
 Links:
Links: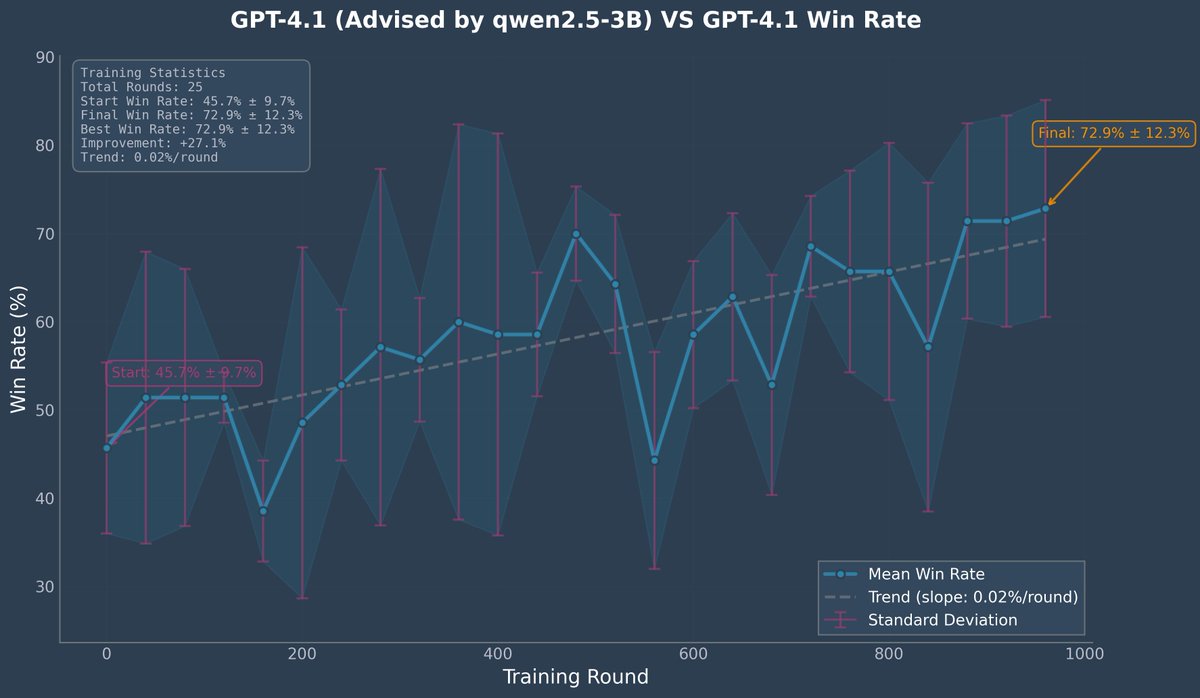 code: github.com/brendanhogan/D…
code: github.com/brendanhogan/D…
 code: github.com/brendanhogan/D…
code: github.com/brendanhogan/D…

 Code:
Code: 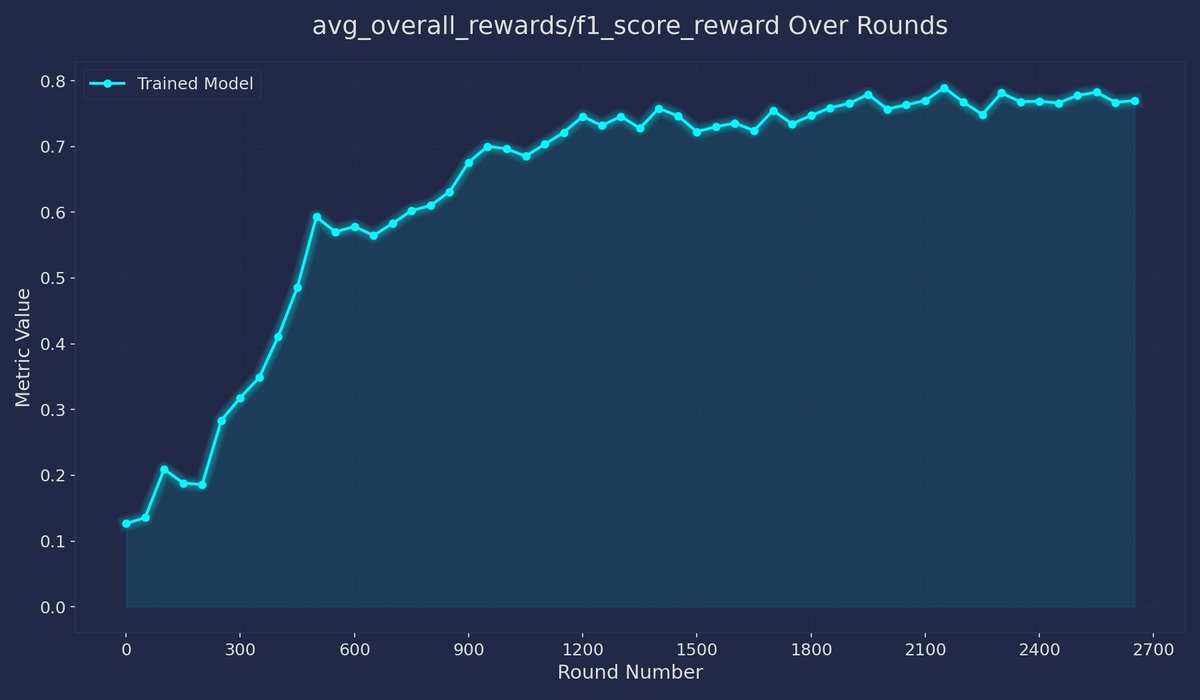
 code: github.com/brendanhogan/D…
code: github.com/brendanhogan/D…
 Github:
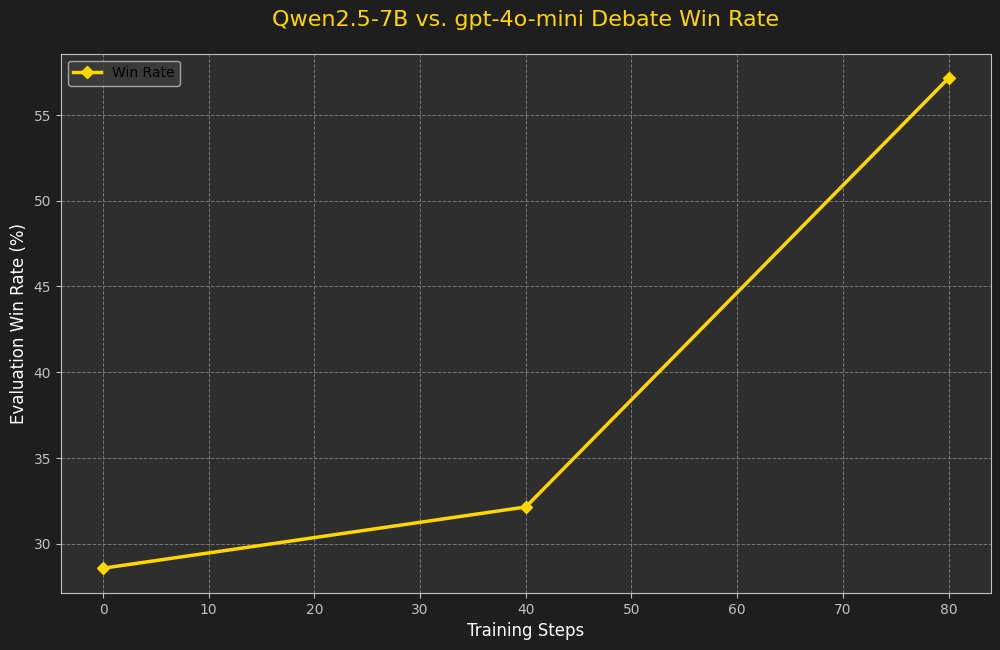
Github: 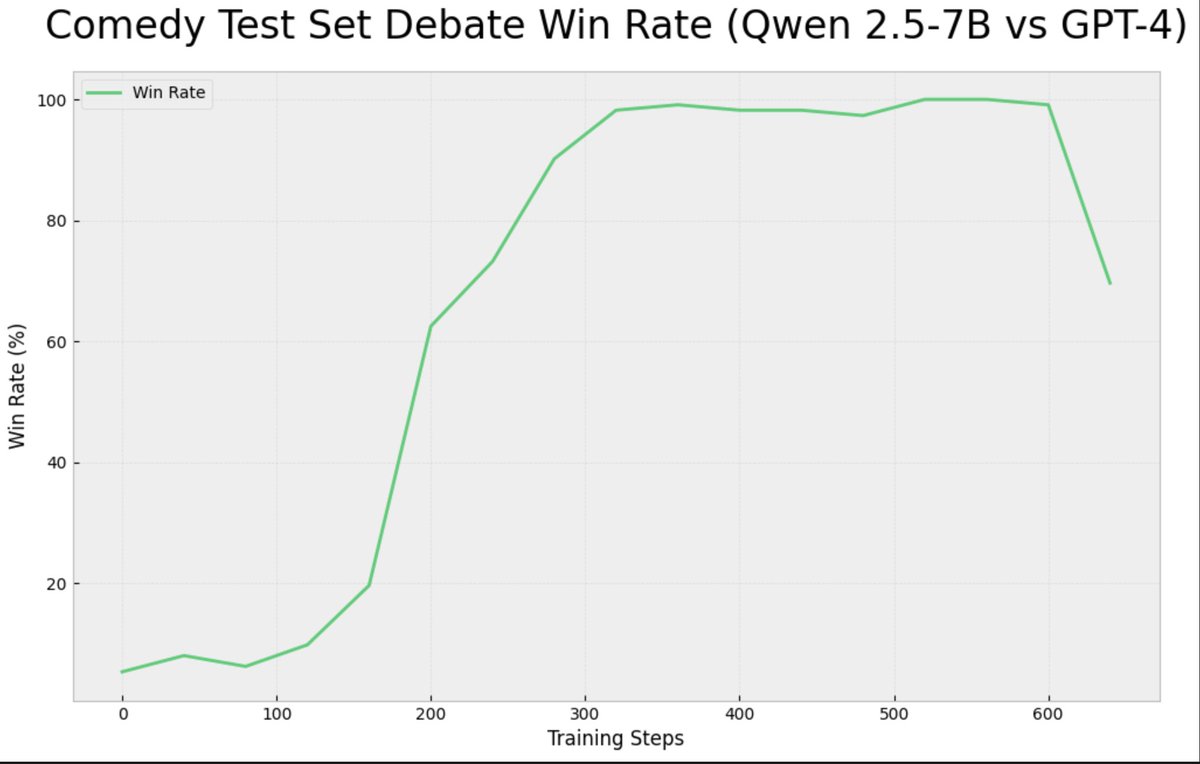 code available here with the dataset: i do think its interesting that a 1.5B model couldnt ever win - whether the judge was itself or gpt-4o-minigithub.com/brendanhogan/D…
code available here with the dataset: i do think its interesting that a 1.5B model couldnt ever win - whether the judge was itself or gpt-4o-minigithub.com/brendanhogan/D…
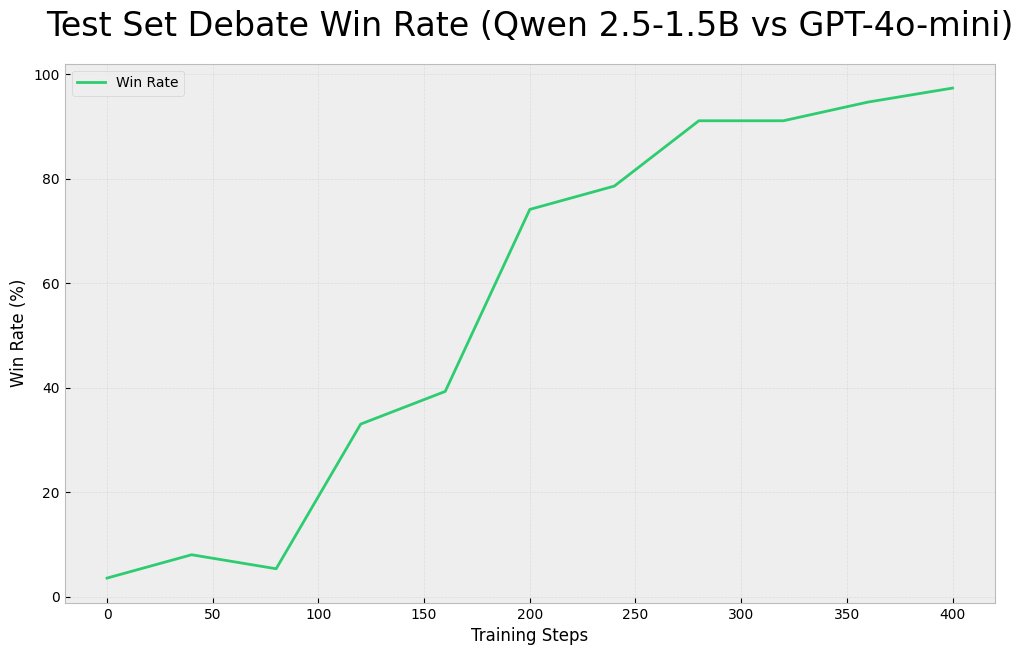 how it works: During training, the model generates multiple debate responses on the same topic. A judge (the base qwen2.5-1.5B model) LLM evaluates these against each other in a round-robin tournament, creating soft rewards that help the model learn which arguments work better. Github Code: (new branch)github.com/brendanhogan/D…
how it works: During training, the model generates multiple debate responses on the same topic. A judge (the base qwen2.5-1.5B model) LLM evaluates these against each other in a round-robin tournament, creating soft rewards that help the model learn which arguments work better. Github Code: (new branch)github.com/brendanhogan/D…