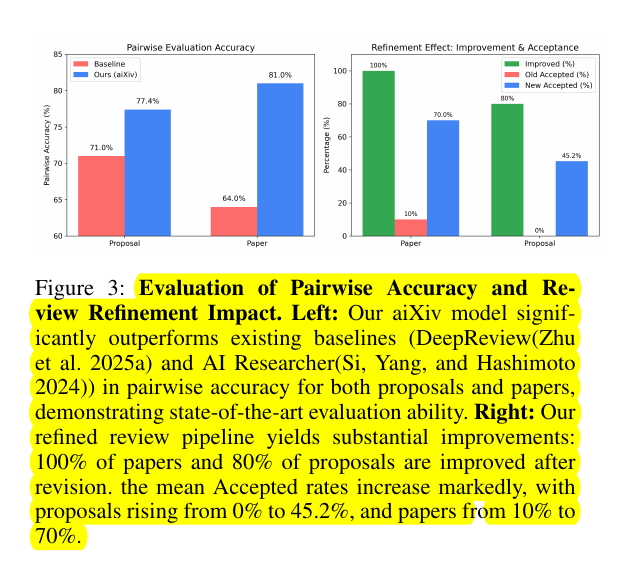
Google shares for the first time the TPUv7 details, at Hot Chips 2025 .
Super valuable insight, that could not otherwise be easily gleamed.
Ironwood is said to offer 2x the perf-per-watt of Google’s previous generation TPU, Trillium.
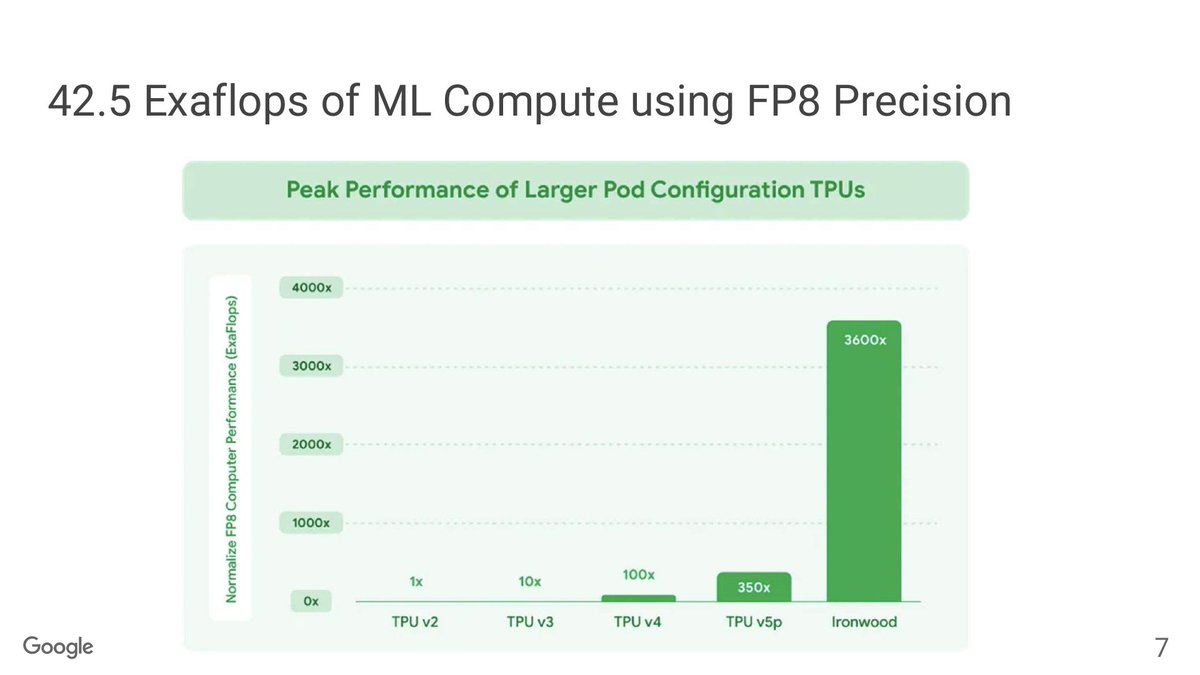
With up to 9,216 chips in a node, Ironwood can scale up to a MASSIVE 42.5 Exaflops in performance.
Though with 10MW of power consumption, that performance doesn’t come cheap.
But, like all of Google’s TPUs, this is solely for Google’s use as part of their Google Cloud services, so Ironwood is not available to look at outside of Google.
🧵 Read on 👇
Super valuable insight, that could not otherwise be easily gleamed.
Ironwood is said to offer 2x the perf-per-watt of Google’s previous generation TPU, Trillium.
With up to 9,216 chips in a node, Ironwood can scale up to a MASSIVE 42.5 Exaflops in performance.
Though with 10MW of power consumption, that performance doesn’t come cheap.
But, like all of Google’s TPUs, this is solely for Google’s use as part of their Google Cloud services, so Ironwood is not available to look at outside of Google.
🧵 Read on 👇

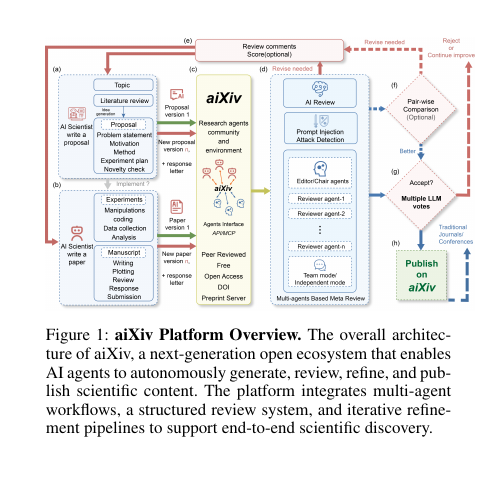
🧵2/n. Ironwood TPU comes with several innovations.
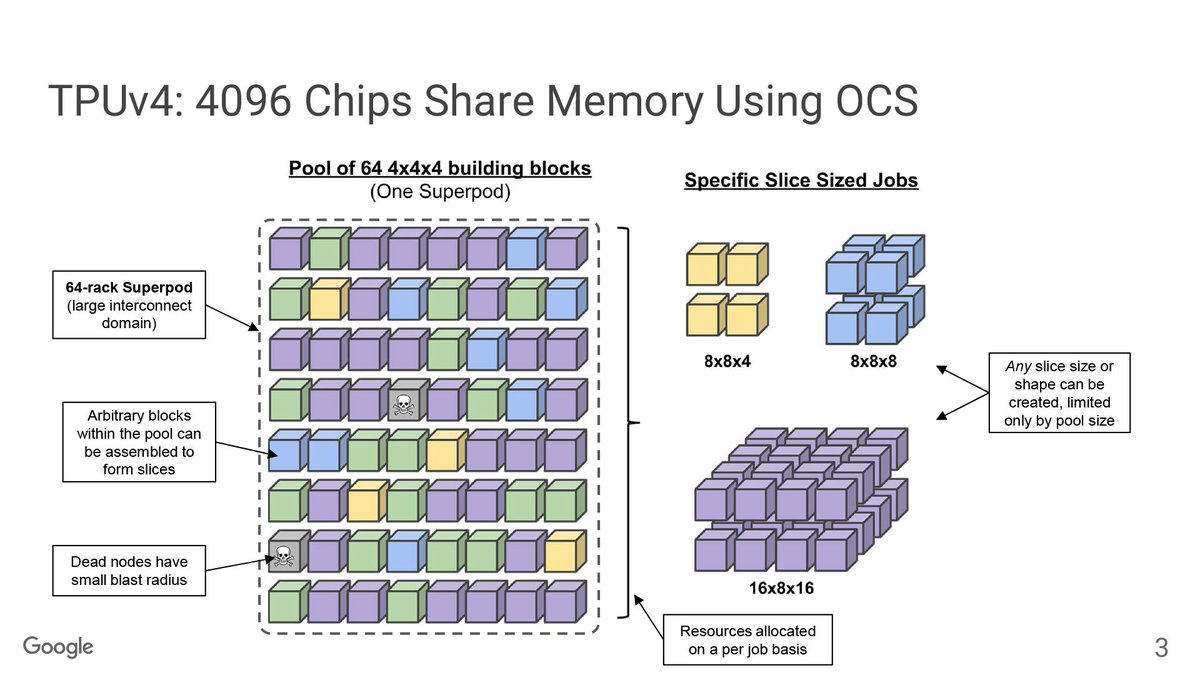
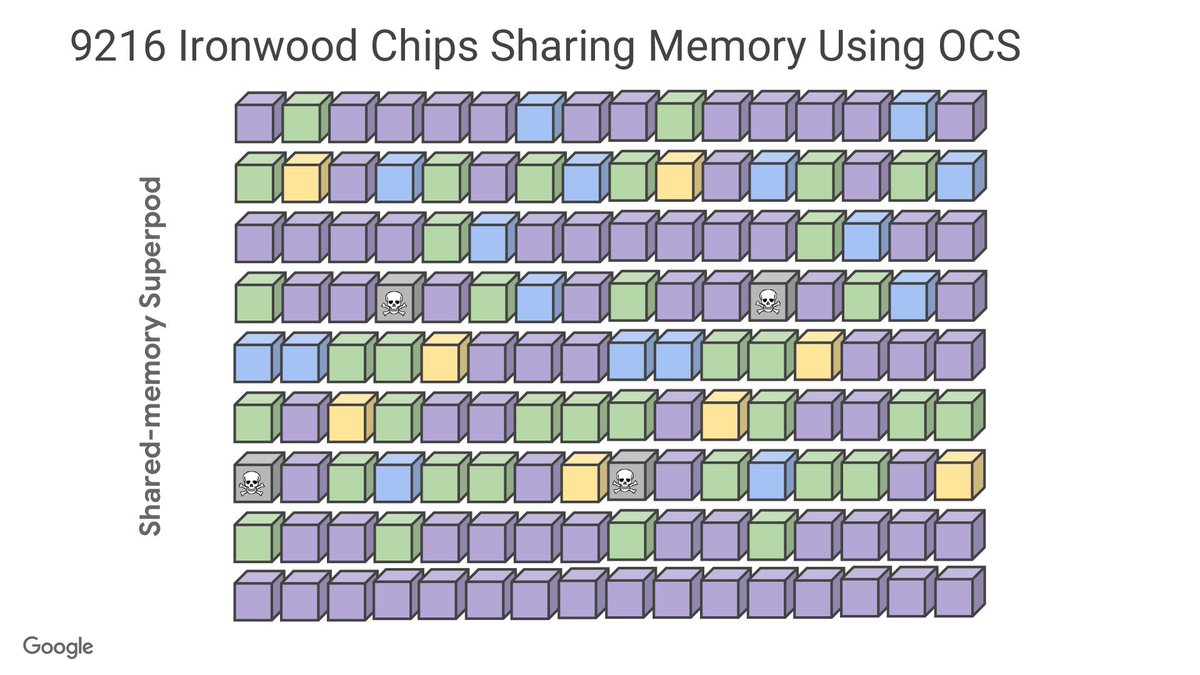
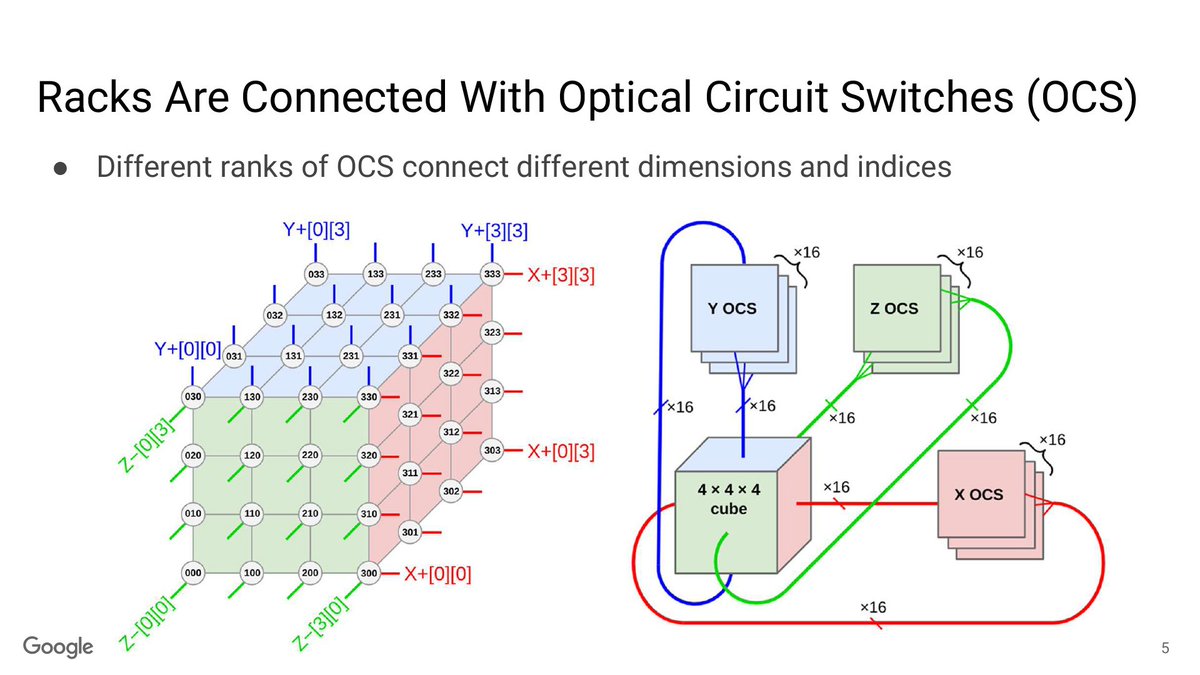
The big one is how big the SuperPods can go. Now up to 9,216 chips, thanks to the use of optical circuit switches (OCS) to share memory throughout the pod. There’s 1.77 PB of directly addressable HBM altogether.
This generation also brings a focus on RAS features in order to have reliable systems.
Power efficiency also gets a boost, of course. Google is claiming a 2x perf-per-watt improvement – though it’s unclear if this is at iso-datatype.
The big one is how big the SuperPods can go. Now up to 9,216 chips, thanks to the use of optical circuit switches (OCS) to share memory throughout the pod. There’s 1.77 PB of directly addressable HBM altogether.
This generation also brings a focus on RAS features in order to have reliable systems.
Power efficiency also gets a boost, of course. Google is claiming a 2x perf-per-watt improvement – though it’s unclear if this is at iso-datatype.
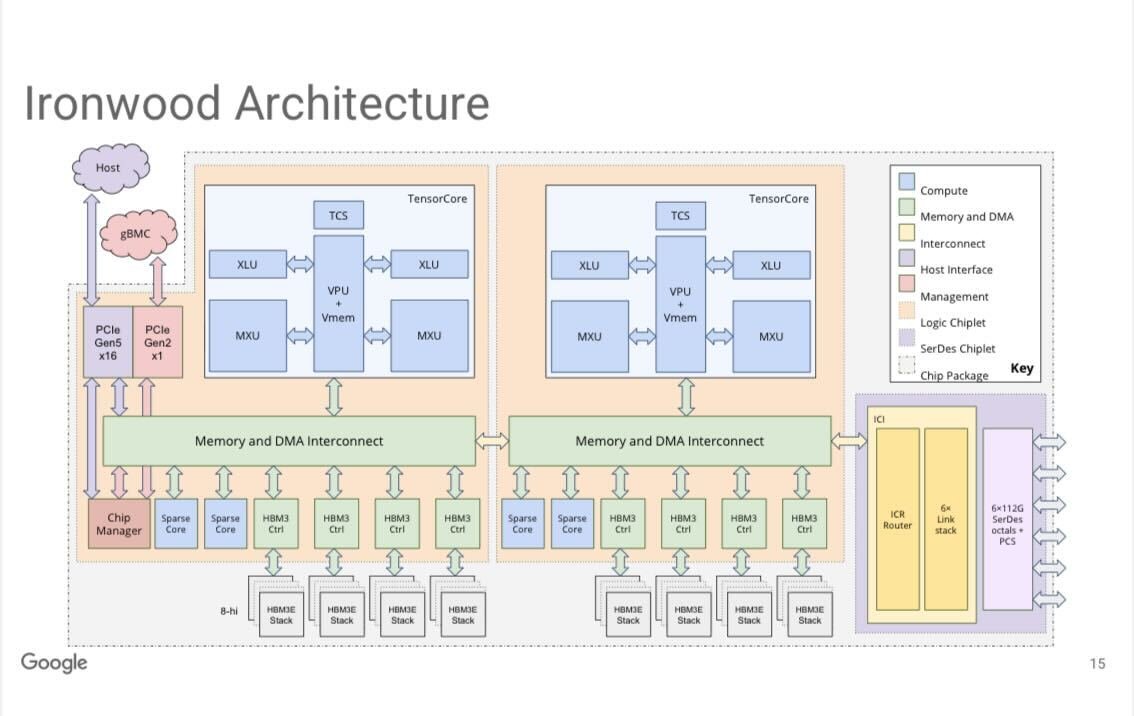
🧵3/n.
🧵4/n.
🧵5/n.
🧵6/n.

🧵7/n.
🧵8/n.
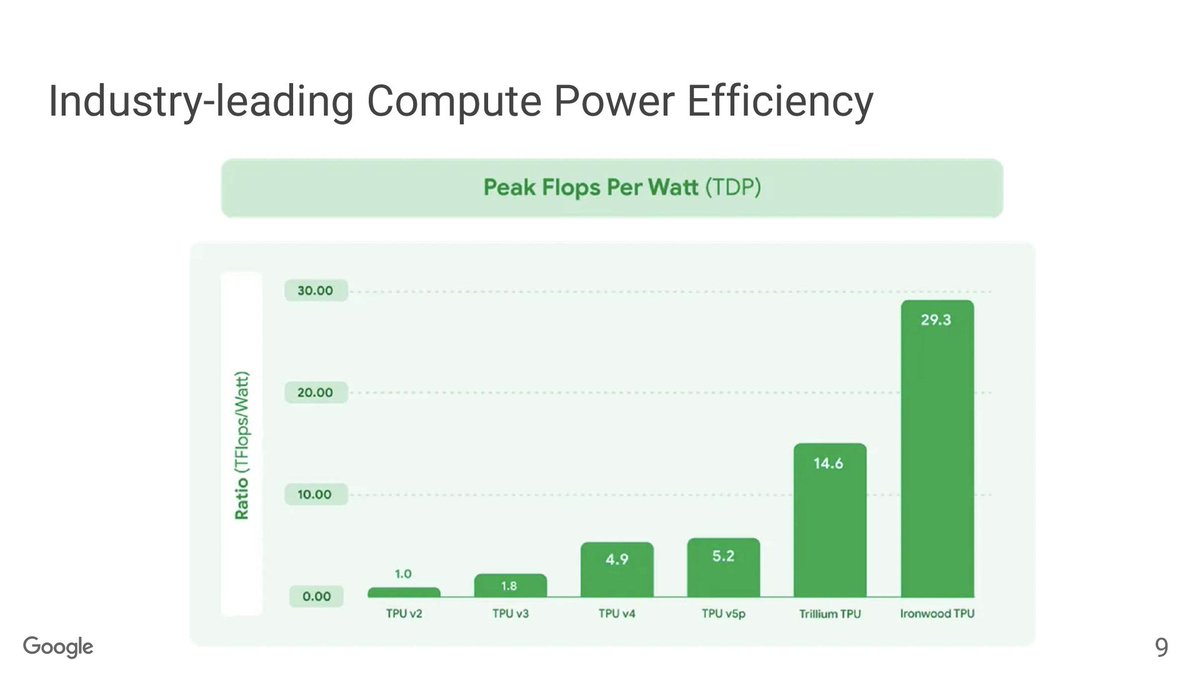
🧵9/n.
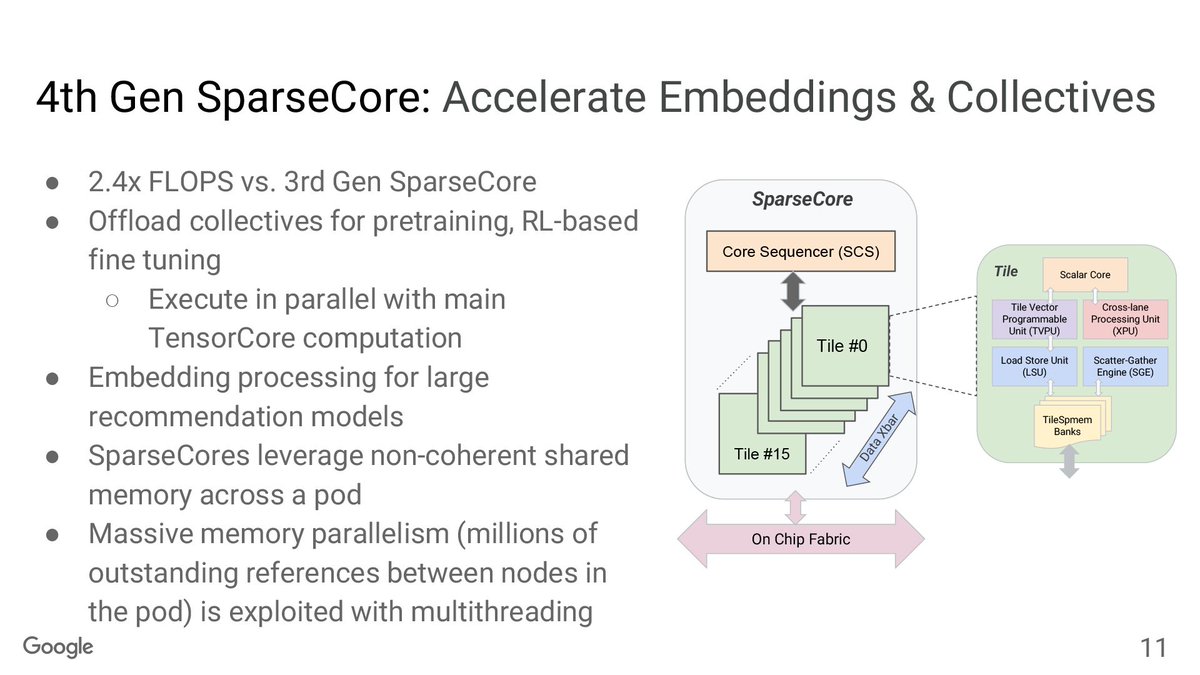
🧵10/n.
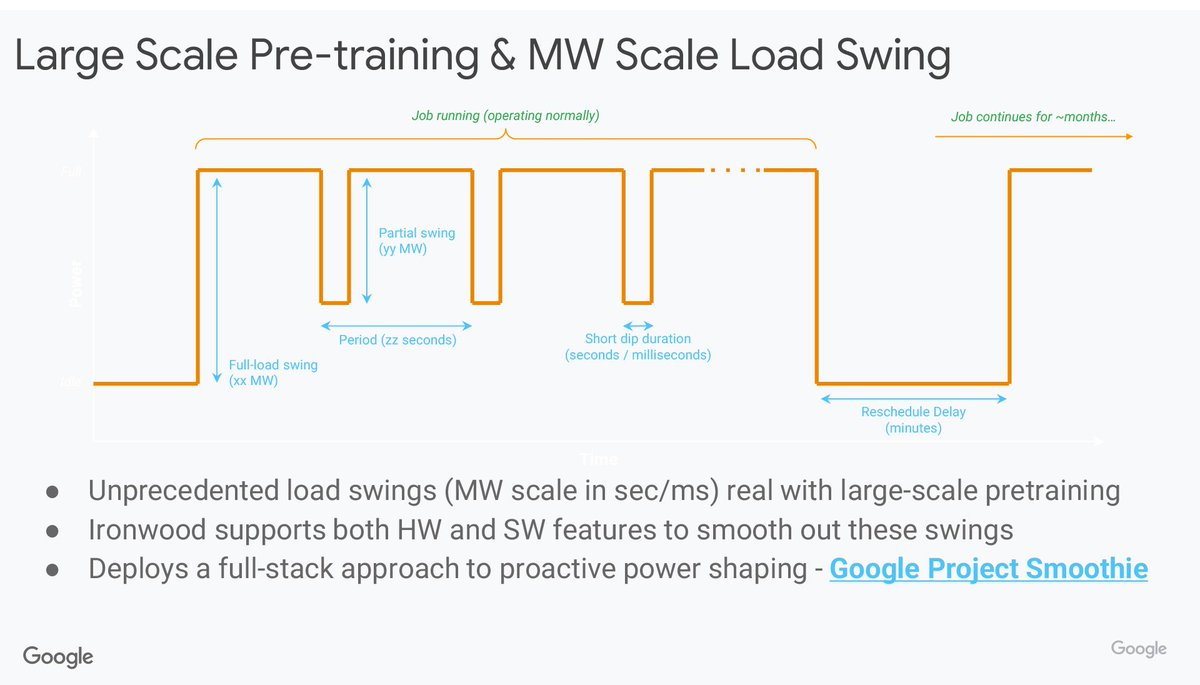
🧵11/n.

🧵12/n. Google updated the SoC architecture so that it could scale beyond a single die, so they aren’t reticle limited. Consequently, Ironwood is their first multiple compute chiplet die, with two Ironwood compute dies on each chip.
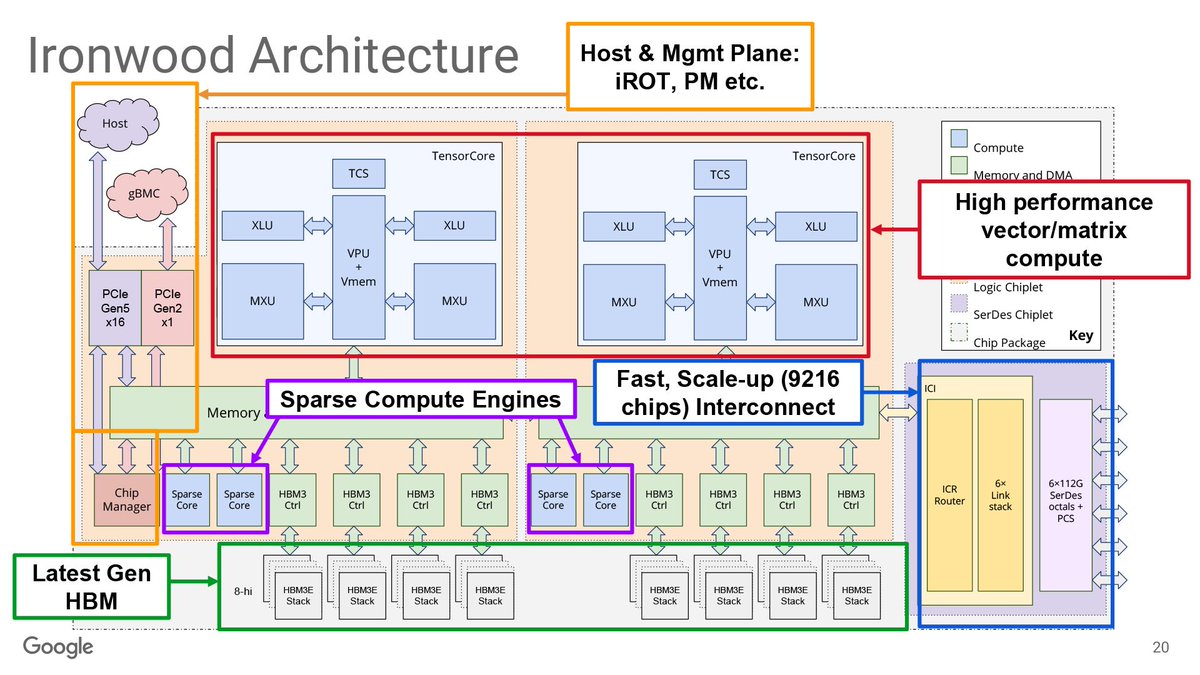
🧵13/n.

🧵14/n.


• • •
Missing some Tweet in this thread? You can try to
force a refresh