Everyone talks about AI “memory,” but nobody defines it.
This paper finally does.
It categorizes LLM memory the same way we do for humans:
• Sensory
• Working
• Long-term
Then shows how each part works in GPTs, agents, and tools.
Here's everything you need to know:
This paper finally does.
It categorizes LLM memory the same way we do for humans:
• Sensory
• Working
• Long-term
Then shows how each part works in GPTs, agents, and tools.
Here's everything you need to know:

First, what the survey does:
• Maps human memory concepts → AI memory
• Proposes a unifying 3D–8Q taxonomy
• Catalogues methods in each category
• Surfaces open problems + future directions
Think of it as a blueprint for how agents can remember.
• Maps human memory concepts → AI memory
• Proposes a unifying 3D–8Q taxonomy
• Catalogues methods in each category
• Surfaces open problems + future directions
Think of it as a blueprint for how agents can remember.
Human ↔ AI memory parallels (Figure 1)
• Sensory → perception layer: raw input briefly held, then dropped or passed on.
• Working memory: immediate reasoning & dialogue context.
• Long-term memory: split into explicit (episodic + semantic) and implicit.
• Sensory → perception layer: raw input briefly held, then dropped or passed on.
• Working memory: immediate reasoning & dialogue context.
• Long-term memory: split into explicit (episodic + semantic) and implicit.
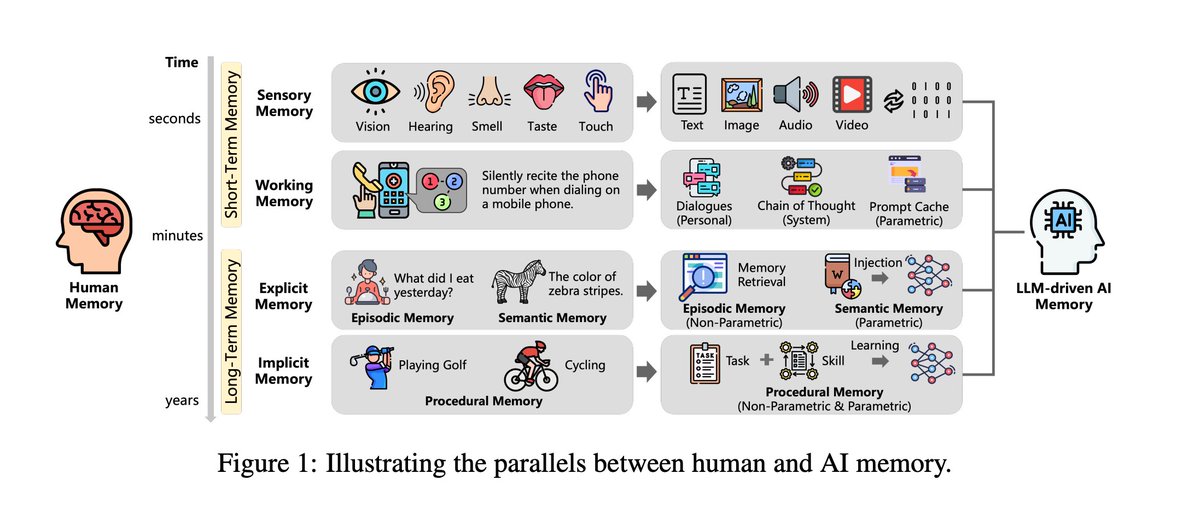
Explicit memory:
Episodic → Non-parametric, long-term (e.g. your preferences in a DB).
Semantic → Parametric, long-term (facts stored in model weights).
Implicit memory: learned skills/patterns, partly parametric, partly non-parametric.
Episodic → Non-parametric, long-term (e.g. your preferences in a DB).
Semantic → Parametric, long-term (facts stored in model weights).
Implicit memory: learned skills/patterns, partly parametric, partly non-parametric.
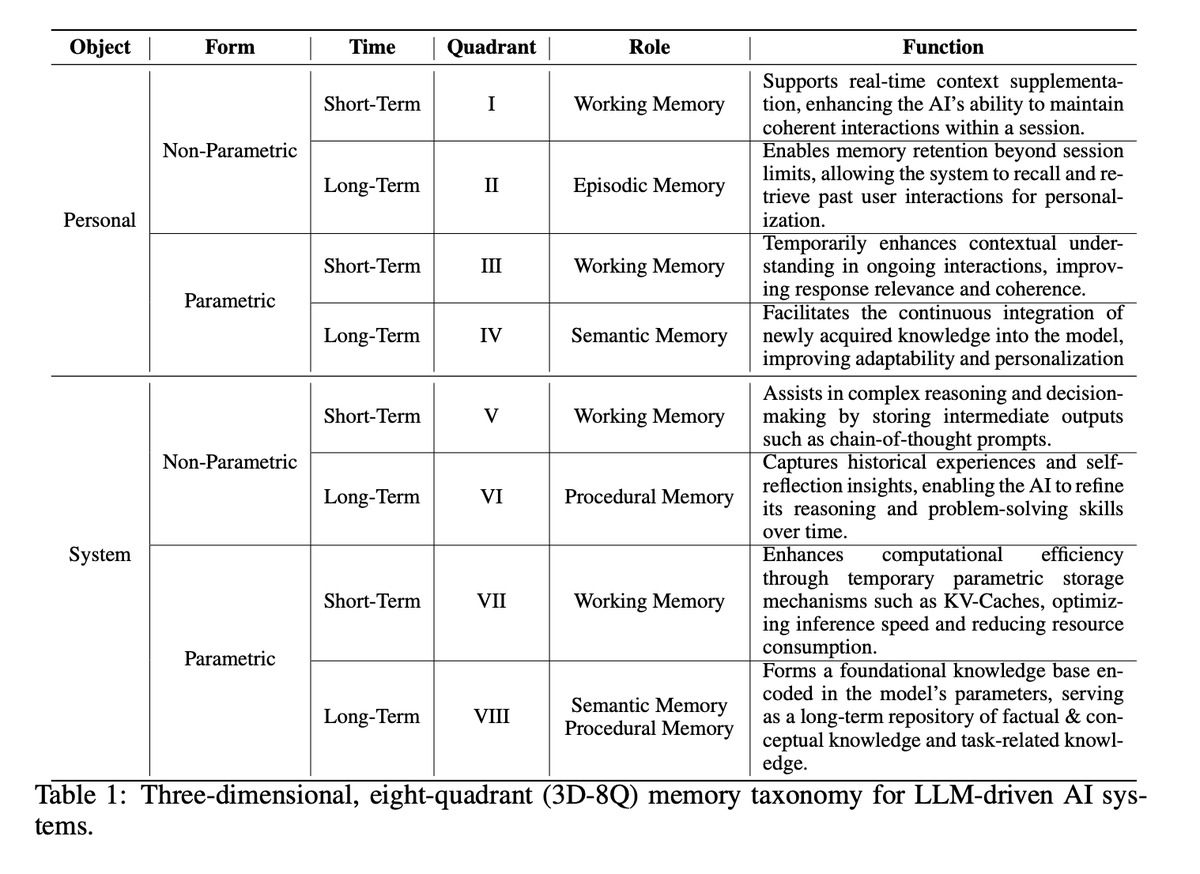
The organizing frame: 3D–8Q taxonomy (Table 1).
Memory is classified along 3 axes:
• Object: Personal vs System
• Form: Non-parametric vs Parametric
• Time: Short- vs Long-term
8 quadrants, each with a role.
Memory is classified along 3 axes:
• Object: Personal vs System
• Form: Non-parametric vs Parametric
• Time: Short- vs Long-term
8 quadrants, each with a role.
Quick rundown of the quadrants:
QI: Personal, non-parametric, short-term → dialogue context.
QII: Personal, non-parametric, long-term → user-specific history.
QIII: Personal, parametric, short-term → prompt/context caching.
QIV: Personal, parametric, long-term → knowledge editing.
QI: Personal, non-parametric, short-term → dialogue context.
QII: Personal, non-parametric, long-term → user-specific history.
QIII: Personal, parametric, short-term → prompt/context caching.
QIV: Personal, parametric, long-term → knowledge editing.
Personal memory (Sections 3.1–3.2): how the system remembers you.
It captures your inputs and preferences → boosts personalization.
Two forms:
Non-parametric (external DB, graphs, vectors)
Parametric (internalized inside the model)
It captures your inputs and preferences → boosts personalization.
Two forms:
Non-parametric (external DB, graphs, vectors)
Parametric (internalized inside the model)
QI: Non-parametric, short-term.
Classic chat memory: using recent turns for coherent, intent-aware responses.
Example: context window in GPT-style chatbots.
Classic chat memory: using recent turns for coherent, intent-aware responses.
Example: context window in GPT-style chatbots.
QII: Non-parametric, long-term.
Cross-session memory: storing user history for personalization.
Pipeline has 4 steps:
• Construction
• Management
• Retrieval
• Usage
Benchmarks exist for eval.
Cross-session memory: storing user history for personalization.
Pipeline has 4 steps:
• Construction
• Management
• Retrieval
• Usage
Benchmarks exist for eval.
QIII: Parametric, short-term.
Caching contextualized chunks or attention states.
Helps with RAG + multi-turn settings.
Lower cost, faster response.
Caching contextualized chunks or attention states.
Helps with RAG + multi-turn settings.
Lower cost, faster response.
QIV: Parametric, long-term.
Personal traits embedded into model parameters.
Methods: fine-tuning, editing.
Bucket = knowledge editing.
Personal traits embedded into model parameters.
Methods: fine-tuning, editing.
Bucket = knowledge editing.
System memory (Section 4): how the agent remembers its own work.
Definition: intermediate states generated during problem-solving.
Key use: improve reasoning, planning, and self-evolution.
Definition: intermediate states generated during problem-solving.
Key use: improve reasoning, planning, and self-evolution.
QV: Non-parametric, short-term.
Reasoning + planning traces.
Think: ReAct, Reflexion.
Reasoning + planning traces.
Think: ReAct, Reflexion.
QVI: Non-parametric, long-term.
Reflections consolidated into reusable workflows.
Examples: BoT, AWM, TiM, Voyager, Retroformer, ExpeL.
Reflections consolidated into reusable workflows.
Examples: BoT, AWM, TiM, Voyager, Retroformer, ExpeL.
QVII: Parametric, short-term.
Efficiency layer.
KV-cache management, compression, quantization.
Systems: vLLM, ChunkKV.
Efficiency layer.
KV-cache management, compression, quantization.
Systems: vLLM, ChunkKV.
QVIII: Parametric, long-term.
Knowledge integrated into weights over time.
Frameworks: MemoryLLM, WISE.
Designs: dual-memory routing, self-updating LLMs.
Knowledge integrated into weights over time.
Frameworks: MemoryLLM, WISE.
Designs: dual-memory routing, self-updating LLMs.
Why this taxonomy matters
It gives builders a checklist:
Whose memory is this for?
Where does it live?
How long should it last?
That clarity = intentional design.
It gives builders a checklist:
Whose memory is this for?
Where does it live?
How long should it last?
That clarity = intentional design.
Open problems (future directions):
• Multimodal memory (text + image + audio + video)
• Stream memory (real-time, continuous)
• Comprehensive integration of all memory types
• Shared memory across models
• Group-level privacy
• Automated self-evolution
• Multimodal memory (text + image + audio + video)
• Stream memory (real-time, continuous)
• Comprehensive integration of all memory types
• Shared memory across models
• Group-level privacy
• Automated self-evolution
Practical takeaways:
• Design against the 3 axes: object, form, time.
• Always pair QV (trace) with QVI (reflection).
• Engineer for retrieval first.
• Budget for speed (KV caches).
• Be deliberate with editing.
This paper = the clearest roadmap to AI memory so far.
• Design against the 3 axes: object, form, time.
• Always pair QV (trace) with QVI (reflection).
• Engineer for retrieval first.
• Budget for speed (KV caches).
• Be deliberate with editing.
This paper = the clearest roadmap to AI memory so far.
Read the full paper: arxiv.org/abs/2506.02153…
P.S.
Are you running a business?
AI can help you automate all your tasks for you.
Join us here at Sentient Automations and learn how to scale with AI for free:
whop.com/sentient-ai-au…
Are you running a business?
AI can help you automate all your tasks for you.
Join us here at Sentient Automations and learn how to scale with AI for free:
whop.com/sentient-ai-au…
I hope you've found this thread helpful.
Follow me @ChrisLaubAI for more.
Like/Repost the quote below if you can:
Follow me @ChrisLaubAI for more.
Like/Repost the quote below if you can:
https://twitter.com/1598365749940310019/status/1960687486532976908
• • •
Missing some Tweet in this thread? You can try to
force a refresh