
AI subsidy abuser | Trilingual surfer living overseas since '13 #SovereignLifestyle
 1. THE REAL QUESTION FINDER
1. THE REAL QUESTION FINDER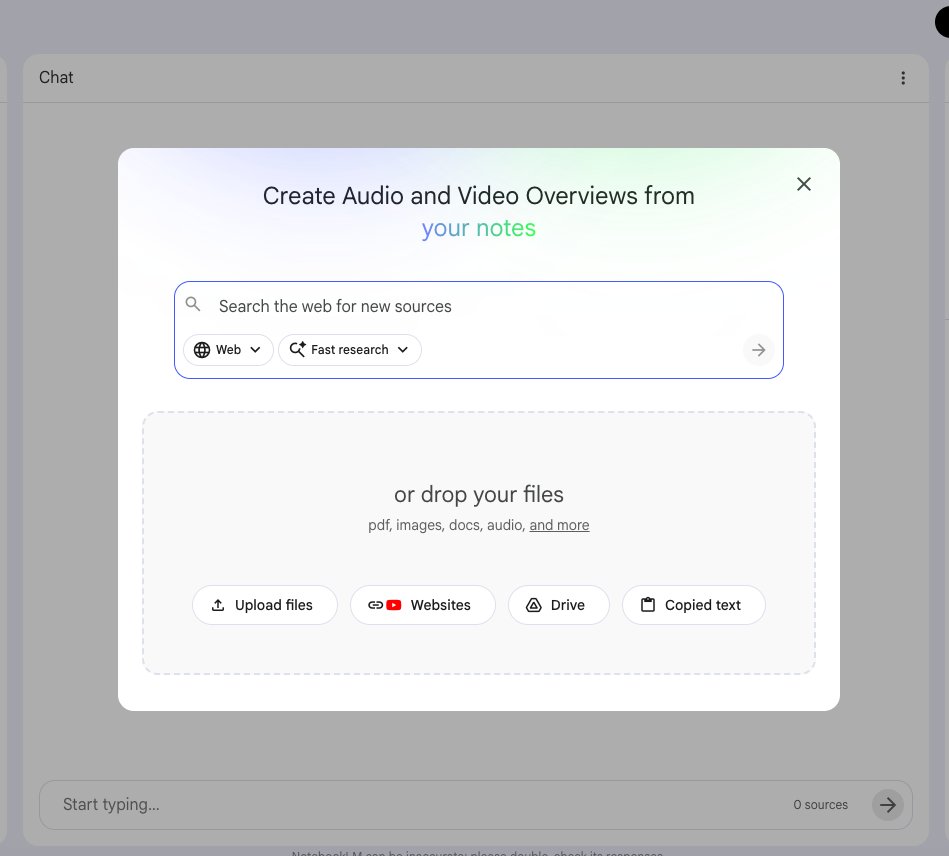
 "ChatGPT is mainly for work"
"ChatGPT is mainly for work"
 𝟏. Scheduled Tasks That Run While You Sleep
𝟏. Scheduled Tasks That Run While You Sleep 1. The Goldman Sachs Stock Screener
1. The Goldman Sachs Stock Screener 1/ THE BUSINESS IDEA GENERATOR
1/ THE BUSINESS IDEA GENERATOR Here's the repo: github.com/BehiSecc/aweso…
Here's the repo: github.com/BehiSecc/aweso…
 1. Specific Knowledge Audit
1. Specific Knowledge Audit

 Prompt 1: The Resume Surgeon
Prompt 1: The Resume Surgeon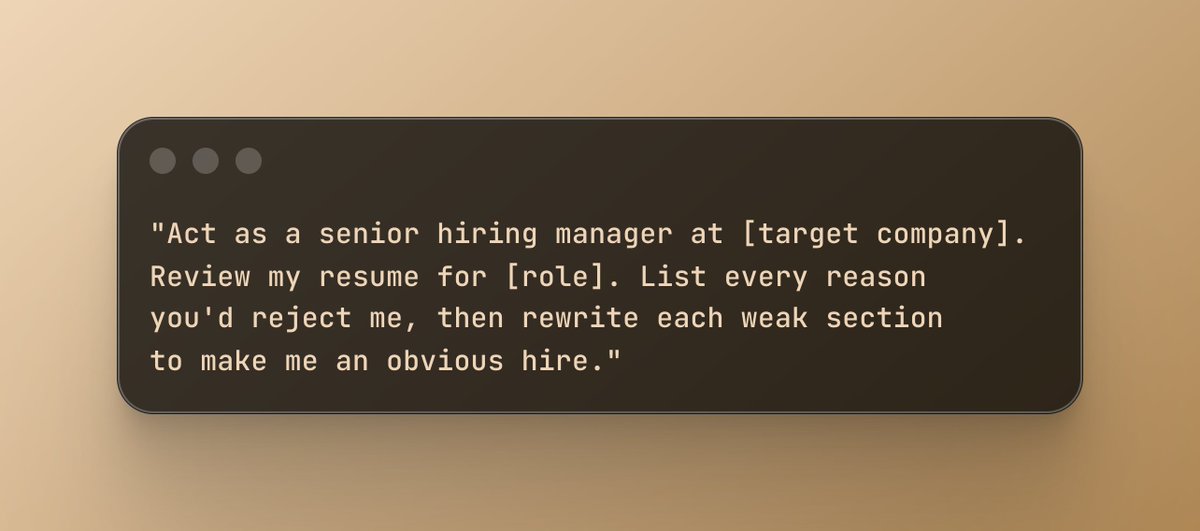
 The setup was identical for all 5 models:
The setup was identical for all 5 models:
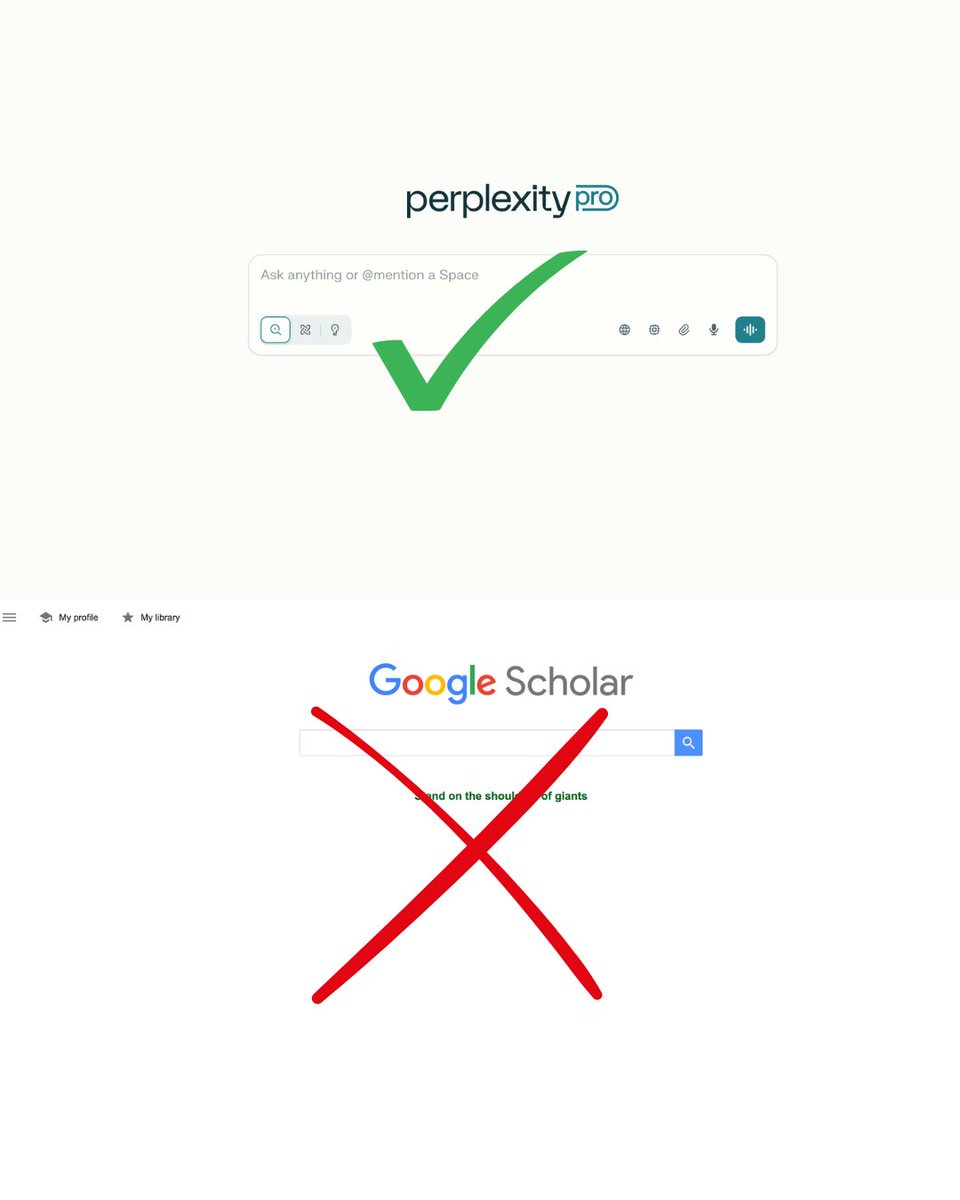 1. Competitive Intelligence Deep Dive
1. Competitive Intelligence Deep Dive 1/ LITERATURE REVIEW SYNTHESIZER
1/ LITERATURE REVIEW SYNTHESIZER 1. THE LITERATURE SYNTHESIZER
1. THE LITERATURE SYNTHESIZER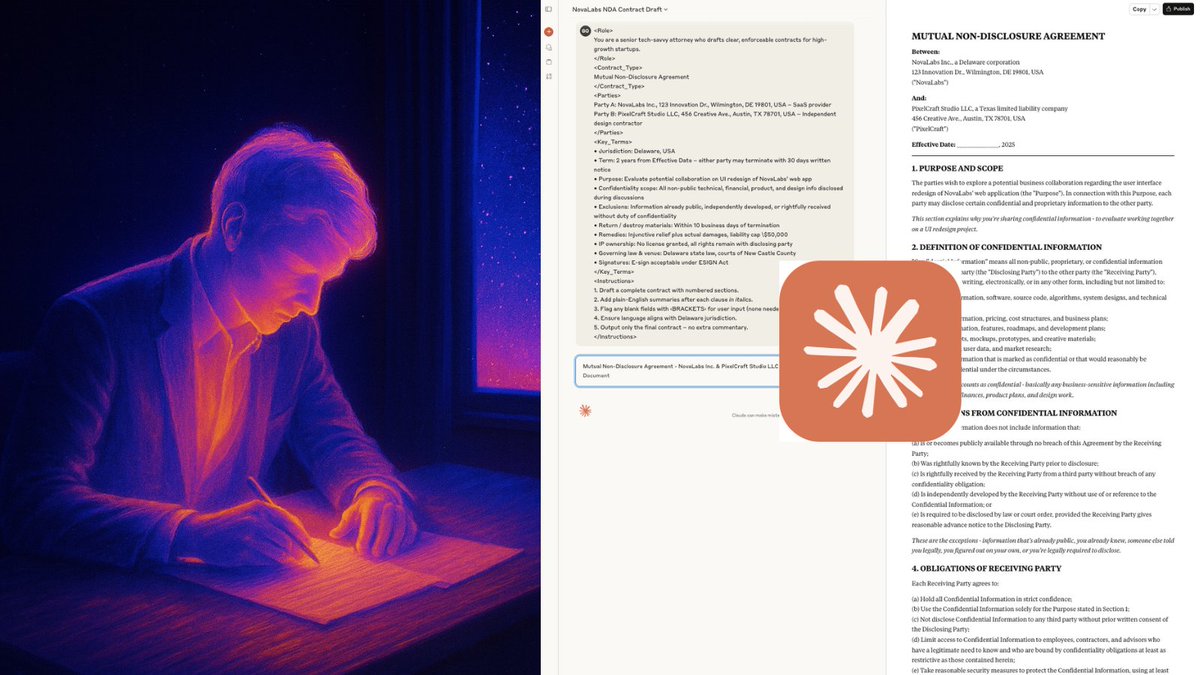 Claude handles every startup staple like a pro:
Claude handles every startup staple like a pro: 1. The Feynman Technique
1. The Feynman Technique

 1. ATS-Proof Resume Tailor
1. ATS-Proof Resume Tailor

 Let me tell you what McKinsey consultants actually do:
Let me tell you what McKinsey consultants actually do: