MIT researchers just found out:
99% of people are prompting wrong.
They throw random words at AI and hope for magic.
Here’s how to actually get consistent, high-quality outputs:
99% of people are prompting wrong.
They throw random words at AI and hope for magic.
Here’s how to actually get consistent, high-quality outputs:
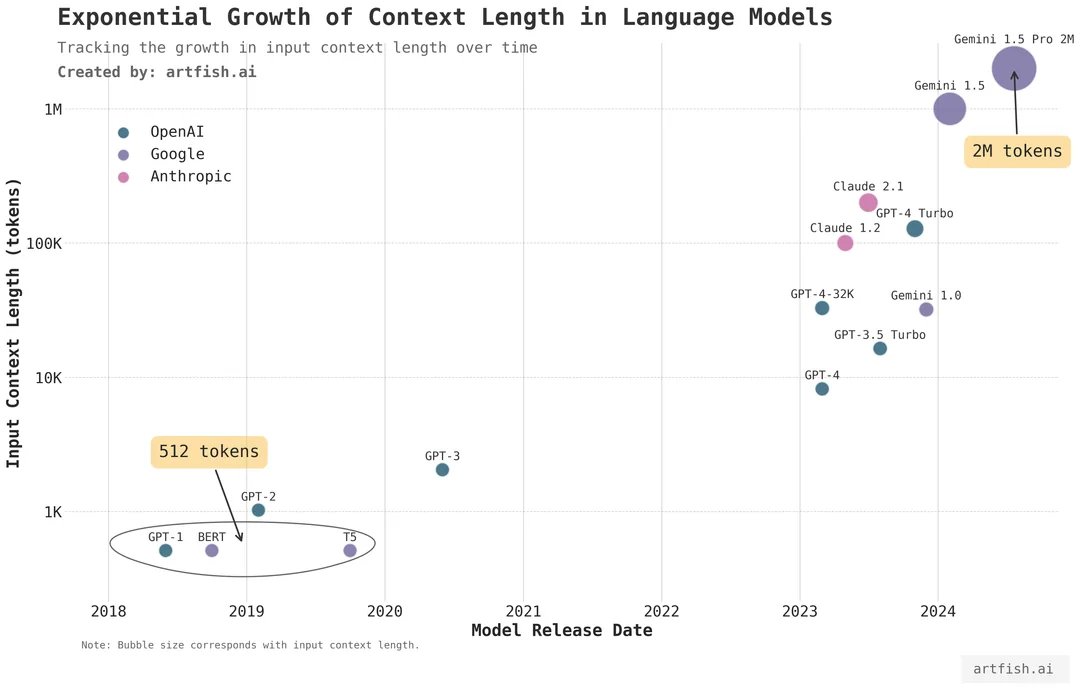
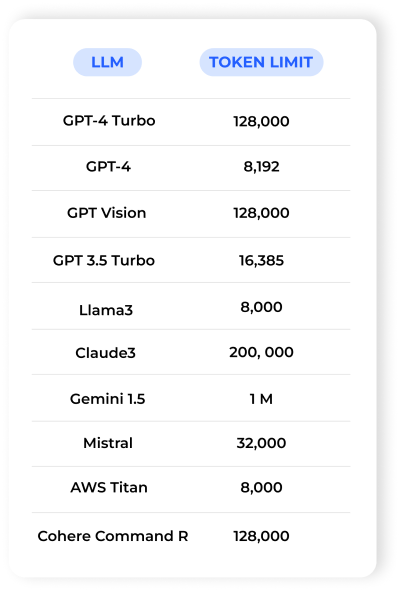
There are 3 main ways to prompt:
👉 Zero-shot
👉 Few-shot
👉 Chain-of-thought
Each works in different scenarios.
Get this wrong, and your outputs will always be shaky.
👉 Zero-shot
👉 Few-shot
👉 Chain-of-thought
Each works in different scenarios.
Get this wrong, and your outputs will always be shaky.

Zero-shot → Just ask the question.
Example:
“Summarize this article in 3 bullet points.”
Good for simple, clear tasks.
But it collapses when the task is fuzzy or creative.
Example:
“Summarize this article in 3 bullet points.”
Good for simple, clear tasks.
But it collapses when the task is fuzzy or creative.
Few-shot → Show the model examples first.
Bad:
“Write me a cold email for a SaaS tool.”
Better:
“Here are 2 cold emails I like. Write one for [X product] in the same style.”
LLMs learn by pattern. Show → then ask.
Bad:
“Write me a cold email for a SaaS tool.”
Better:
“Here are 2 cold emails I like. Write one for [X product] in the same style.”
LLMs learn by pattern. Show → then ask.

This is why examples > wording.
People obsess over magic phrases (“act as an expert”).
But what matters is showing the AI the shape of the answer you want.
Show 2–3 examples, and the model locks onto the pattern.
People obsess over magic phrases (“act as an expert”).
But what matters is showing the AI the shape of the answer you want.
Show 2–3 examples, and the model locks onto the pattern.
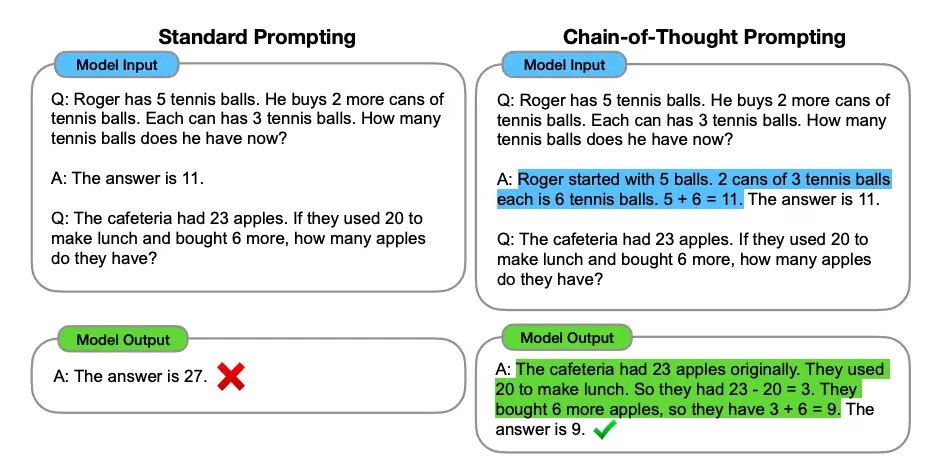
Chain-of-thought (CoT) → Tell the AI to “think step by step.”
Bad:
“What’s the best way to grow this SaaS?”
Better:
“Think step by step:
1. Identify growth channels.
2. Evaluate pros/cons.
3. Suggest the most cost-effective one.”
Now the output has structure.
Bad:
“What’s the best way to grow this SaaS?”
Better:
“Think step by step:
1. Identify growth channels.
2. Evaluate pros/cons.
3. Suggest the most cost-effective one.”
Now the output has structure.
Here’s a practical analogy:
Prompts are like code.
If it breaks, you don’t blame the computer you debug.
→ Add an example.
→ Break it into smaller steps.
→ Reframe the ask.
Iterate until stable.
Prompts are like code.
If it breaks, you don’t blame the computer you debug.
→ Add an example.
→ Break it into smaller steps.
→ Reframe the ask.
Iterate until stable.
Example Prompt Debugging:
❌ Bad: “Explain quantum computing simply.”
🤷 Result: Jargon-heavy mess.
✅ Better:
“Explain quantum computing to a 10-year-old using analogies. Give 3 examples.”
❌ Bad: “Explain quantum computing simply.”
🤷 Result: Jargon-heavy mess.
✅ Better:
“Explain quantum computing to a 10-year-old using analogies. Give 3 examples.”
This is the mindset shift:
Stop prompting like a spellcaster.
Start prompting like an engineer.
Good prompts aren’t magic words, they’re systems.
Stop prompting like a spellcaster.
Start prompting like an engineer.
Good prompts aren’t magic words, they’re systems.
And the future? Self-improving prompts.
We’ll soon have AI that auto-tests multiple prompt variations, measures the outputs, and refines the best one.
Prompt engineering → prompt evolution.
We’ll soon have AI that auto-tests multiple prompt variations, measures the outputs, and refines the best one.
Prompt engineering → prompt evolution.
So here’s the practical framework:
- Zero-shot for simple asks
- Few-shot for style & format
- CoT for reasoning tasks
- Debug like code when it breaks
- Zero-shot for simple asks
- Few-shot for style & format
- CoT for reasoning tasks
- Debug like code when it breaks
Prompting isn’t broken.
The way most people do it is broken.
Once you apply this framework, your AI outputs will stop being random and start being reliable.
The way most people do it is broken.
Once you apply this framework, your AI outputs will stop being random and start being reliable.
90% of customers expect instant replies.
Most businesses? Still responding days later.
Meet Droxy AI: your 24/7 AI employee:
• Handles calls, chats, comments
• Speaks 95+ languages
• Feels human
• Costs $20/mo
Start automating:
try.droxy.ai/now
Most businesses? Still responding days later.
Meet Droxy AI: your 24/7 AI employee:
• Handles calls, chats, comments
• Speaks 95+ languages
• Feels human
• Costs $20/mo
Start automating:
try.droxy.ai/now
I hope you've found this thread helpful.
Follow me @alxnderhughes for more.
Like/Repost the quote below if you can:
Follow me @alxnderhughes for more.
Like/Repost the quote below if you can:
https://twitter.com/1927203051263184896/status/1962799520825446592
• • •
Missing some Tweet in this thread? You can try to
force a refresh