
Join the Prime Intellect RL Residency
Our community already shipped 100+ environments to the Environment Hub
Help us accelerate, with compute, a stipend, and support from our research team
Our community already shipped 100+ environments to the Environment Hub
Help us accelerate, with compute, a stipend, and support from our research team
The RL Residency gives you:
— Compute for experiments
— A stipend
— Hands-on support from our internal research team
— Compute for experiments
— A stipend
— Hands-on support from our internal research team
Who should apply?
— Grad students with research ideas
— Independent builders & hackers
— Part time researchers exploring novel RL environments and evals
If you’ve wanted to build environments but lacked compute or support - this is for you
— Grad students with research ideas
— Independent builders & hackers
— Part time researchers exploring novel RL environments and evals
If you’ve wanted to build environments but lacked compute or support - this is for you
Some moonshot environments and evals we’d be especially excited about:
— Robust code-quality evaluations for agentic software engineering
— Evaluating usage of filesystems and memory for long-running tasks
— Adaptive coherent instruction-following for realistic multi-turn interactions
— Generative generalist reward models with process critiques
— Harness and task design for machine learning, such as:
—— Environments for NanoGPT speedrun optimizations
—— Terminal-friendly data visualization
—— Research plan generation, with recent notable papers as golden targets
— Robust code-quality evaluations for agentic software engineering
— Evaluating usage of filesystems and memory for long-running tasks
— Adaptive coherent instruction-following for realistic multi-turn interactions
— Generative generalist reward models with process critiques
— Harness and task design for machine learning, such as:
—— Environments for NanoGPT speedrun optimizations
—— Terminal-friendly data visualization
—— Research plan generation, with recent notable papers as golden targets
Some highlights already live on the hub:
— KernelBench for GPU kernel generation
— DeepCoder coding problems with executable verification in sandbox
— StepFun-Prover for formal theorem proving in Lean4
— BrowseComp for agentic web research
— HUD 2048 variants, GPQA, AIME 2025, ARC-AGI with tools, and more
Each one expands the frontier of what open models can learn and be evaluated on
app.primeintellect.ai/dashboard/envi…
— KernelBench for GPU kernel generation
— DeepCoder coding problems with executable verification in sandbox
— StepFun-Prover for formal theorem proving in Lean4
— BrowseComp for agentic web research
— HUD 2048 variants, GPQA, AIME 2025, ARC-AGI with tools, and more
Each one expands the frontier of what open models can learn and be evaluated on
app.primeintellect.ai/dashboard/envi…
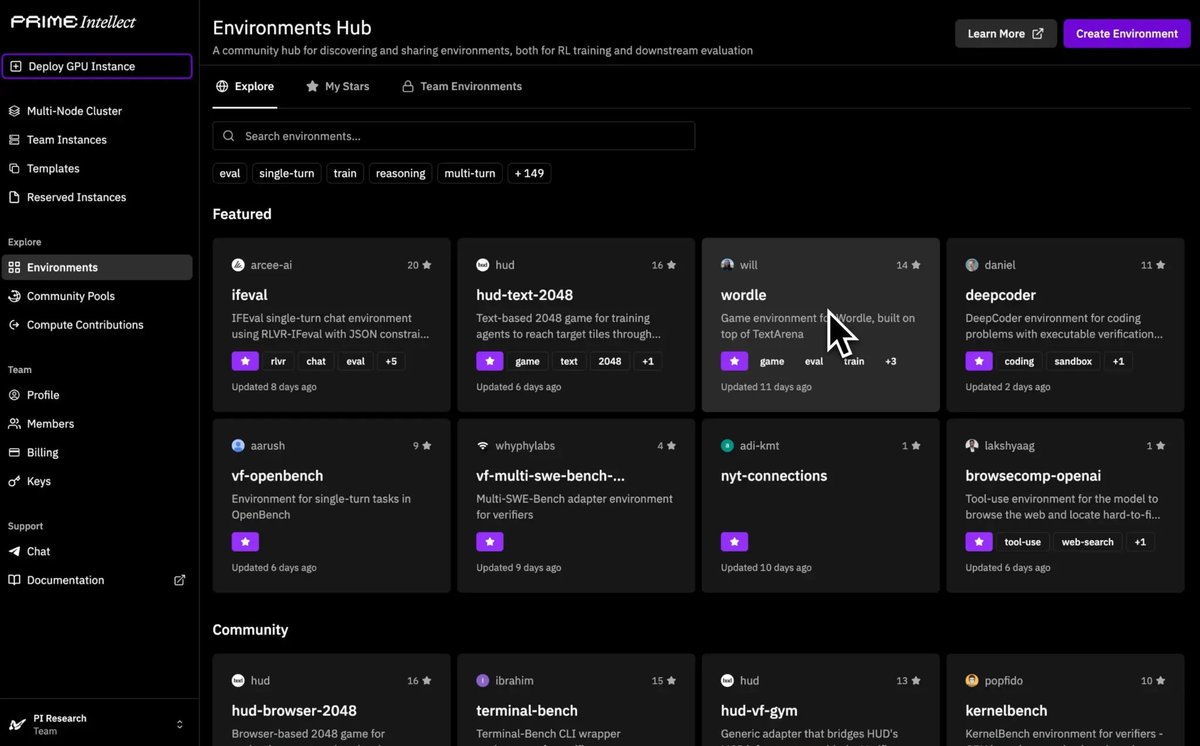
The Environments Hub forms the foundation of our full-stack open AGI infrastructure.
We want to put the tools to build AGI into the hands of the many, to diffuse chokepoints of control and reduce the risks of centralization.
Every environment contributed shifts the balance of power towards open-source.
We want to put the tools to build AGI into the hands of the many, to diffuse chokepoints of control and reduce the risks of centralization.
Every environment contributed shifts the balance of power towards open-source.
Apply to the residency, join the fellowship, and help contribute to open source AGI
Docs on building environments:
docs.primeintellect.ai/tutorials-envi…
Application link: form.typeform.com/to/ibQawo5e
form.typeform.com/to/ibQawo5e
Docs on building environments:
docs.primeintellect.ai/tutorials-envi…
Application link: form.typeform.com/to/ibQawo5e
form.typeform.com/to/ibQawo5e
• • •
Missing some Tweet in this thread? You can try to
force a refresh










