📢 Another Brilliant research just dropped from @GoogleResearch - a major advancement for a systematic way to generate expert-level scientific software automatically.
An LLM plus tree search turns scientific coding into a score driven search engine.
This work builds an LLM + Tree Search loop that writes and improves scientific code by chasing a single measurable score for each task.
The key idea is to treat coding for scientific tasks as a scorable search problem.
That means every candidate program can be judged by a simple numeric score, like how well it predicts, forecasts, or integrates data. Once you have a clear score, you can let a LLM rewrite code again and again, run the code in a sandbox, and use tree search to keep the best branches while discarding weaker ones
With compact research ideas injected into the prompt, the system reaches expert level and beats strong baselines across biology, epidemiology, geospatial, neuroscience, time series, and numerical methods.
Training speed: less than 2 hours on 1 T4 vs 36 hours on 16 A100s.
In bioinformatics, it came up with 40 new approaches for single-cell data analysis that beat the best human-designed methods on a public benchmark.
In epidemiology, it built 14 models that set state-of-the-art results for predicting COVID-19 hospitalizations.
🧵 Read on 👇
An LLM plus tree search turns scientific coding into a score driven search engine.
This work builds an LLM + Tree Search loop that writes and improves scientific code by chasing a single measurable score for each task.
The key idea is to treat coding for scientific tasks as a scorable search problem.
That means every candidate program can be judged by a simple numeric score, like how well it predicts, forecasts, or integrates data. Once you have a clear score, you can let a LLM rewrite code again and again, run the code in a sandbox, and use tree search to keep the best branches while discarding weaker ones
With compact research ideas injected into the prompt, the system reaches expert level and beats strong baselines across biology, epidemiology, geospatial, neuroscience, time series, and numerical methods.
Training speed: less than 2 hours on 1 T4 vs 36 hours on 16 A100s.
In bioinformatics, it came up with 40 new approaches for single-cell data analysis that beat the best human-designed methods on a public benchmark.
In epidemiology, it built 14 models that set state-of-the-art results for predicting COVID-19 hospitalizations.
🧵 Read on 👇

🧵2/n. ⚙️ The Core Concepts
Empirical software is code built to maximize a quality score on observed data, and any task that fits this framing becomes a scorable task.
This view turns software creation into a measurable search problem, because every candidate program is judged by the same numeric target.
This framing also explains why the method can travel across domains, since only the scoring function changes.
Empirical software is code built to maximize a quality score on observed data, and any task that fits this framing becomes a scorable task.
This view turns software creation into a measurable search problem, because every candidate program is judged by the same numeric target.
This framing also explains why the method can travel across domains, since only the scoring function changes.

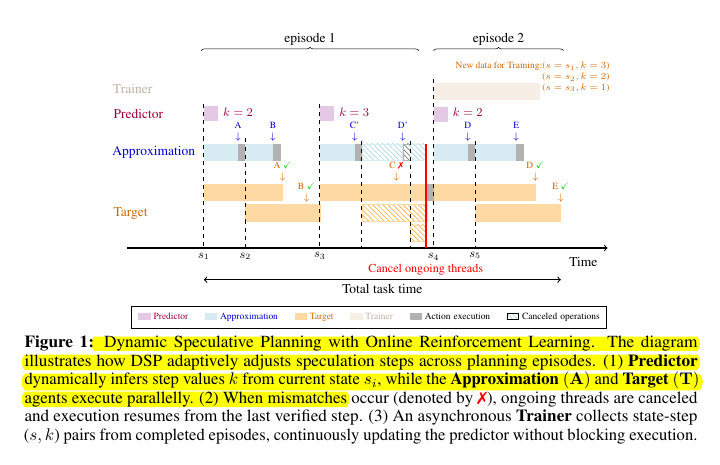
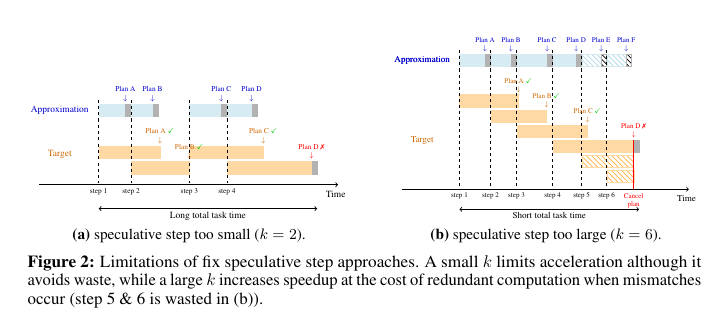
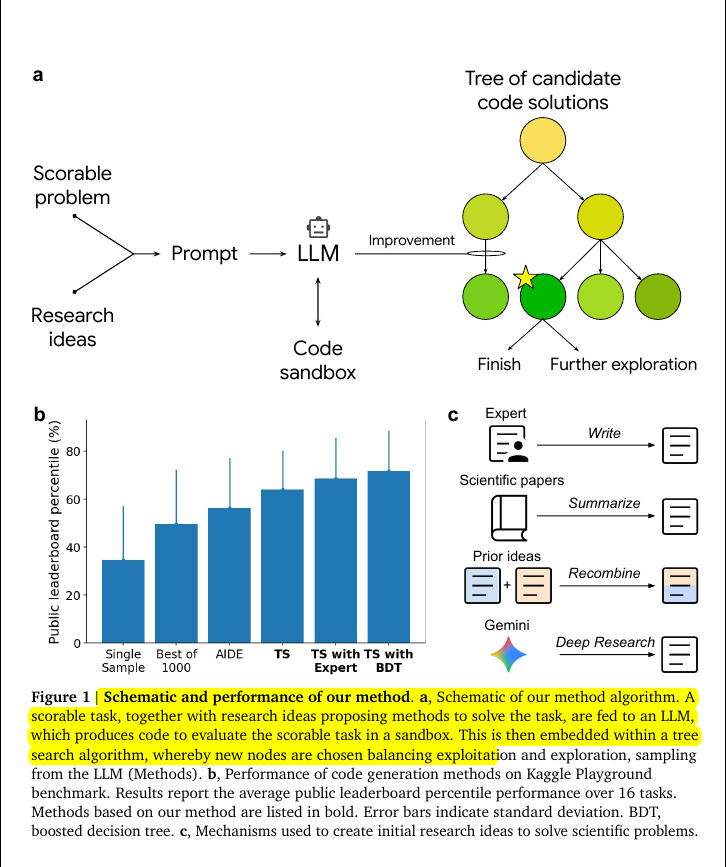
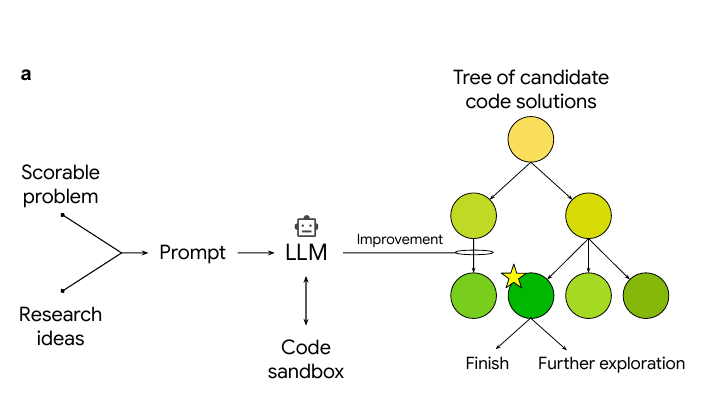
🧵3/n. This figure is breaking down both how the system works.
The top-left part shows the workflow. A scorable problem and some research ideas are given to an LLM, which then generates code. That code is run in a sandbox to get a quality score. Tree search is used to decide which code branches to keep improving, balancing exploration of new ideas with exploitation of ones that already look promising.
On the right, different ways of feeding research ideas into the system are shown. Ideas can come from experts writing direct instructions, from scientific papers that are summarized, from recombining prior methods, or from LLM-powered deep research. These sources make the search more informed and help the model produce stronger, more competitive solutions.
So overall, the loop of tree search plus targeted research ideas turns an LLM from a one-shot code generator into a system that steadily climbs toward expert-level performance.
The top-left part shows the workflow. A scorable problem and some research ideas are given to an LLM, which then generates code. That code is run in a sandbox to get a quality score. Tree search is used to decide which code branches to keep improving, balancing exploration of new ideas with exploitation of ones that already look promising.
On the right, different ways of feeding research ideas into the system are shown. Ideas can come from experts writing direct instructions, from scientific papers that are summarized, from recombining prior methods, or from LLM-powered deep research. These sources make the search more informed and help the model produce stronger, more competitive solutions.
So overall, the loop of tree search plus targeted research ideas turns an LLM from a one-shot code generator into a system that steadily climbs toward expert-level performance.
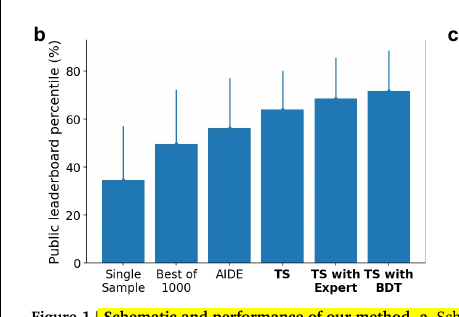
🧵4/n. This chart shows how different code generation approaches perform on the Kaggle Playground benchmark. It measures the public leaderboard percentile, which is a way to rank how well the generated solutions score compared to human submissions.
The simple methods like generating a single sample or even picking the best from 1000 runs stay below 50%. That means they rarely reach strong leaderboard positions.
When the system adds tree search (TS), performance jumps significantly. The average rank moves closer to the top half of the leaderboard, meaning the AI is finding higher-quality code solutions.
Performance climbs even higher when tree search is combined with expert guidance or with a boosted decision tree idea. These additions steer the search toward strategies that humans have found effective, letting the system consistently reach well above the 60–70% percentile.
So this graph basically shows that iterative search guided by research ideas or expert hints is much stronger than one-shot or random attempts at code generation.
The simple methods like generating a single sample or even picking the best from 1000 runs stay below 50%. That means they rarely reach strong leaderboard positions.
When the system adds tree search (TS), performance jumps significantly. The average rank moves closer to the top half of the leaderboard, meaning the AI is finding higher-quality code solutions.
Performance climbs even higher when tree search is combined with expert guidance or with a boosted decision tree idea. These additions steer the search toward strategies that humans have found effective, letting the system consistently reach well above the 60–70% percentile.
So this graph basically shows that iterative search guided by research ideas or expert hints is much stronger than one-shot or random attempts at code generation.
🧵5/n. 🧱 How the system searches
The system starts from a working template, asks an LLM to rewrite the code, runs it in a sandbox, and records the score.
Tree Search chooses which branches to extend based on the gains seen so far, so exploration favors promising code paths.
The loop repeats until the tree contains a high scoring solution that generalizes on the task’s validation scheme.
The system starts from a working template, asks an LLM to rewrite the code, runs it in a sandbox, and records the score.
Tree Search chooses which branches to extend based on the gains seen so far, so exploration favors promising code paths.
The loop repeats until the tree contains a high scoring solution that generalizes on the task’s validation scheme.
🧵6/n. 🧪 How research ideas guide the code
The prompt is augmented with research ideas distilled from papers, textbooks, or LLM powered literature search, then the LLM implements those ideas as code.
These ideas are injected as short instructions, often auto summarized from manuscripts, so the search explores concrete methods rather than vague hunches.
The system can also recombine parent methods into hybrids, and many of those hybrids score higher than both parents.
The prompt is augmented with research ideas distilled from papers, textbooks, or LLM powered literature search, then the LLM implements those ideas as code.
These ideas are injected as short instructions, often auto summarized from manuscripts, so the search explores concrete methods rather than vague hunches.
The system can also recombine parent methods into hybrids, and many of those hybrids score higher than both parents.
Paper –
Paper Title: "An AI system to help scientists write expert-level empirical software"arxiv.org/abs/2509.06503
Paper Title: "An AI system to help scientists write expert-level empirical software"arxiv.org/abs/2509.06503
• • •
Missing some Tweet in this thread? You can try to
force a refresh